2 Construire un environnement de data science moderne grâce aux technologies cloud
L’intégration des nouvelles sources de données et des méthodologies innovantes dans les processus de production statistique pose plusieurs défis. Le premier est celui de l’infrastructure : ces sources de données sont souvent massives, donc coûteuses en stockage, et les méthodologies permettant de les traiter sont généralement gourmandes en ressources de calcul. L’autre défi est de permettre aux statisticiens d’accéder à ces ressources à travers des environnements qui favorisent l’autonomie — qu’il s’agisse de dimensionner les ressources de calcul en fonction des chaînes de productions statistiques à traiter, de déployer des preuves de concept avec agilité, de travailler de manière collaborative, etc. Dans ce contexte, l’objectif était de concevoir une plateforme de data science qui non seulement rende possible le traitement des données massives, mais qui permette également aux statisticiens de tester et déployer de nouveaux outils de manière autonome. Pour se faire, la première étape a été d’analyser les évolutions de l’écosystème de la donnée afin d’identifier les tendances significatives qui sous-tendent les choix technologiques observés dans l’industrie. L’analyse de ces évolutions indique une tendance générale vers l’adoption des technologies cloud, en particulier les conteneurs et le stockage objet, qui permettent de construire des infrastructures capables de gérer des ensembles de données volumineux et variés de manière flexible et efficiente. Ces technologies sont par ailleurs particulièrement pertinentes pour construire des environnements de calcul destinés à la statistique publique, dans la mesure où elles favorisent l’autonomie et la reproductibilité des traitements.
2.1 Limites des architectures informatiques traditionnelles
Afin de comprendre la prédominance des technologies cloud dans les infrastructures actuelles de traitement de la donnée, il est nécessaire de rappeler l’historique — sans prétendre à l’exhaustivité — des architectures développées au cours des dernières décennies afin de traiter les données de plus en plus volumineuses générées par la numérisation des activités humaines. Historiquement, les données ont été stockées dans des bases de données, c’est à dire des systèmes de stockage et d’organisation de la donnée. Ces objets ont vu le jour dans les années 1950, et ont connu un essor particulier avec les bases de données relationnelles dans les années 1980. Cette technologie se révélant particulièrement pertinente pour organiser le stockage des données “métier” des entreprises, elle a été à la base des data warehouses, qui ont longtemps constitué la référence des infrastructures de stockage de la donnée. Si leur implémentation technique peut être de nature variée, leur principe est simple : des données de sources multiples et hétérogènes sont intégrées dans un système de bases de données relationnel selon des règles métier grâce à des processus dits ETL (extract-transform-load), afin de les rendre directement accessibles pour une variété d’usages (analyse statistique, reporting, etc.) à l’aide d’un langage normalisé : SQL (Chaudhuri and Dayal 1997).
Au début des années 2000, la montée en puissance des usages de nature big data dans les entreprises met en lumière les limites des data warehouses traditionnels. D’une part, les données traités présentent une diversité croissante de formats (structurés, semi-structurés et non structurés), et cette réalité rentre difficilement dans le monde ordonné des data warehouses, qui nécessite de spécifier a priori le schéma des données. Pour pallier ces limites, de nouvelles infrastructures de stockage vont être développées : les data lakes, qui permettent la collecte et le stockage de quantités massives de données de nature diverse. D’autre part, la taille considérable de ces données rend de plus en plus difficile leur exploitation sur une unique machine. C’est dans ce contexte que Google publie le paradigme MapReduce (Ghemawat, Gobioff, and Leung 2003; Dean and Ghemawat 2008), jetant les bases d’une nouvelle génération de systèmes permettant de traiter de larges volumes de données de manière distribuée. Cette approche oppose à l’idée de scalabilité verticale — augmenter la puissance d’une machine de calcul, ce qui devient rapidement très coûteux et se heurte aux limites physiques des composants — la logique de la scalabilité horizontale : en installant en parallèle des serveurs — chacun d’une puissance limitée — et en adaptant les algorithmes à cette logique distribuée, on parvient à traiter des données massives avec du matériel standard. Dans la lignée de ces travaux, émerge l’écosystème Hadoop qui offre une combinaison de technologies complémentaires : un data lake (HDFS - Hadoop Distributed File System), un moteur de calcul distribué (MapReduce) et des outils d’intégration et de transformation de la donnée. Cet éco-système est progressivement complété par des outils qui vont démocratiser la capacité à traiter des données big data : Hive, qui convertit des requêtes SQL en traitements MapReduce distribués, puis Spark, qui lève certaines limites techniques de MapReduce et fournit des API dans plusieurs langages (Java, Scala, Python, etc.). Le succès de l’éco-système Hadoop dans l’industrie est considérable dans la mesure où il permet de traiter des volumes de données sans précédent — jusqu’au péta-octet — et des vélocités considérables — jusqu’au temps réel — à l’aide de langages de programmation non réservés aux seuls informaticiens.
À la fin des années 2010, les architectures basées sur Hadoop connaissent néanmoins un net déclin de popularité. Dans les environnements Hadoop traditionnels, le stockage et le calcul sont co-localisés par construction : si les données à traiter sont réparties sur plusieurs serveurs, chaque section des données est directement traitée sur la machine hébergeant cette section, afin d’éviter les transferts réseau entre serveurs. Dans ce paradigme, la mise à l’échelle de l’architecture implique une augmentation linéaire à la fois des capacités de calcul et de stockage, indépendamment de la demande réelle. Dans un article volontairement provocateur et intitulé “Big Data is Dead” (Tigani 2023), Jordan Tigani, l’un des ingénieurs fondateurs de Google BigQuery, explique pourquoi ce modèle ne correspond plus à la réalité de la plupart des organisations exploitant intensivement de la donnée. Premièrement, parce que “dans la pratique, la taille des données augmente beaucoup plus rapidement que les besoins en calcul”. Même si la quantité de données générées et nécessitant donc d’être stockées croît de manière rapide au fil du temps, il n’est généralement pas nécessaire d’interroger l’ensemble des données stockés mais seulement les portions les plus récentes, ou seulement certaines colonnes et/ou groupes de lignes. Par ailleurs, Tigani souligne que “la frontière du big data ne cesse de reculer” : les avancées dans les capacités des serveurs et la baisse des coûts du matériel signifient que le nombre de charges de travail ne tenant pas sur une seule machine — une définition simple mais efficace du big data — a diminué de manière continue. En conséquence, en séparant correctement les fonctions de stockage et de calcul, même les traitements de données substantiels peuvent finir par utiliser “beaucoup moins de calcul que prévu […] et pourraient même ne pas avoir besoin d’un traitement distribué du tout”.
Cette tendance est par ailleurs renforcée par certaines avancées technologiques récentes issues de l’éco-système de la donnée qui permettent de traiter des volumes de plus en plus importants de données sur des machines standards et à l’aide de logiciels conventionnels (R, Python). Tout d’abord, en utilisant des formats de stockage efficients, comme Apache Parquet (Foundation 2013). Ce format de stockage orienté-colonne (voir Figure 1) est notamment optimisé pour les analyses WORM (write once, read many) ce qui le rend particulièrement adapté aux traitements statistiques, où les données sont généralement figées après la collecte, mais les analyses ultérieures à partir de ces données potentiellement nombreuses. De plus, la possibilité de partitionner ces données selon une variable de filtrage fréquente, comme la région ou le département par exemple, permet d’optimiser les traitements — à la manière d’un index dans une base SQL — et d’accroître encore leur efficience. Ces différentes propriétés rendent le format Parquet particulièrement adapté aux tâches analytiques comme celles généralement effectuées dans les statistiques publiques (Dondon and Lamarche 2023; Abdelaziz et al. 2023).
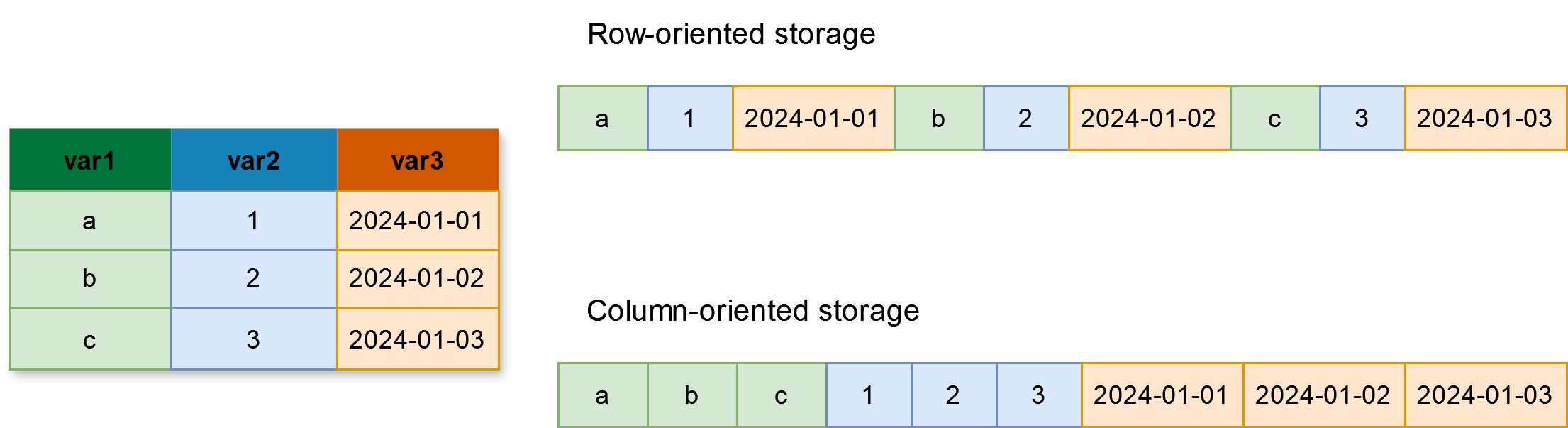
Note: De nombreuses opérations statistiques sont analytiques (dites OLAP - Online Analytical Processing) par nature : elles impliquent la sélection de colonnes spécifiques, le calcul de nouvelles variables, la réalisation d’agrégations basées sur des groupes, etc. Le stockage orienté ligne - comme dans un fichier CSV - n’est pas adapté à ces opérations analytiques, car il nécessite de charger l’ensemble du jeu de données en mémoire afin d’effectuer une requête. À l’inverse, le stockage orienté colonne permet de ne lire que les colonnes de données pertinentes, ce qui réduit considérablement les temps de lecture et de traitement pour ces charges de travail analytiques. En pratique, les formats colonnes populaires tels que Parquet utilisent une représentation hybride : ils sont principalement orientés colonne, mais intègrent également un regroupement astucieux basé sur les lignes pour optimiser les requêtes de filtrage.
Une autre innovation majeure concerne le traitement des données non plus en matière de stockage, mais en mémoire (RAM). La première est Apache Arrow, un format tabulaire de données en mémoire interopérable entre de nombreux langages (Python, R, Java, etc.). La seconde est DuckDB, un système de base de données portable et également interopérable. Ces deux outils, bien que techniquement très différents en termes d’implémentation, présentent des avantages et des gains de performance semblables. D’abord, ils sont tous deux orientés-colonne (voir Figure 1) et travaillent ainsi en synergie avec le format Parquet, dans la mesure où ils font persister les bénéfices de ce format de stockage dans la mémoire. Par ailleurs, ils permettent tout deux d’augmenter considérablement les performances des requêtes sur les données grâce à l’utilisation de la lazy evaluation (“évaluation paresseuse”). Là où les opérations sur des données sont généralement exécutées de manière linéaire par les langages de programmation — par exemple, sélectionner des colonnes et/ou filtrer des lignes, puis calculer de nouvelles colonnes, puis effectuer des agrégations, etc. — Arrow comme DuckDB exécutent quant à eux ces dernières selon un plan d’exécution pré-calculé qui optimise de manière globale la chaîne de traitements. Dans ce paradigme, les calculs sont non seulement beaucoup plus performants, mais également beaucoup plus efficients dans la mesure où ils se limitent aux données effectivement nécessaires pour les traitements demandé. Ces innovations permettant ainsi d’envisager des traitements basés sur des données dont le volume total dépasse la mémoire RAM effectivement disponible sur une machine.
2.2 L’apport des technologies cloud
Dans la lignée des observations de Tigani, on observe ces dernières années dans l’industrie une transition marquée vers des architectures plus flexibles et faiblement couplées. L’avènement des technologies cloud a joué un rôle déterminant dans cette transition, et ce pour plusieurs raisons. D’abord, une raison technique : par rapport à l’époque où Hadoop constituait l’infrastructure big data de référence, la latence des flux réseaux est devenue une préoccupation bien moindre, rendant le modèle de co-localisation du stockage et des ressources de calcul sur de mêmes machines moins pertinent. Ensuite, une raison liée aux usages : si le volume des données générées continue de croître, c’est surtout la diversification des données exploitées qui marque l’évolution récente de l’éco-système. Les infrastructures modernes doivent doivent non seulement être capables de traiter de grands volumes, mais aussi être adaptables sur de multiples dimensions. Elles doivent pouvoir prendre en charge diverses structures de données (allant des formats structurés et tabulaires aux formats non structurés comme le texte, les images, le son et la vidéo) et permettre une large gamme de techniques computationnelles, du calcul parallèle aux modèles d’apprentissage profond qui nécessitent des GPU, ainsi que le déploiement et la gestion d’applications (Li et al. 2020). Ces dernières années, deux technologies intimement liée au cloud — justifiant leur qualificatif de technologies cloud-native — ont émergé comme des solutions essentielles pour atteindre ce besoin d’environnements de calcul plus flexibles : la conteneurisation et le stockage objet.
Dans un environnement cloud, l’ordinateur de l’utilisateur devient un simple point d’accès pour effectuer des calculs sur une infrastructure centralisée. Cela permet à la fois un accès universel aux ressources et un passage à l’échelle des services, car il est plus facile de faire passer à l’échelle une infrastructure centrale — là encore de manière horizontale, c’est-à-dire en ajoutant davantage de serveurs. Cependant, ces infrastructures centralisées présentent deux limites importantes : la concurrence entre utilisateurs pour l’accès aux ressources physiques et la nécessité d’isoler correctement les applications déployées. Le choix de la conteneurisation est fondamental, car il répond à ces deux enjeux (Bentaleb et al. 2022). En créant des “bulles” spécifiques à chaque service, les conteneurs garantissent l’herméticité des applications tout en restant légers, puisqu’ils partagent le système d’exploitation avec la machine hôte (voir Figure 2). Initialement développés dans le cadre du noyau Linux, les conteneurs ont fortement gagné en popularité au début des années 2010 grâce au moteur Docker qui a permis la démocratisation de leur utilisation - à tel point que l’on emploie parfois le terme “dockerisation” pour désigner la conteneurisation.
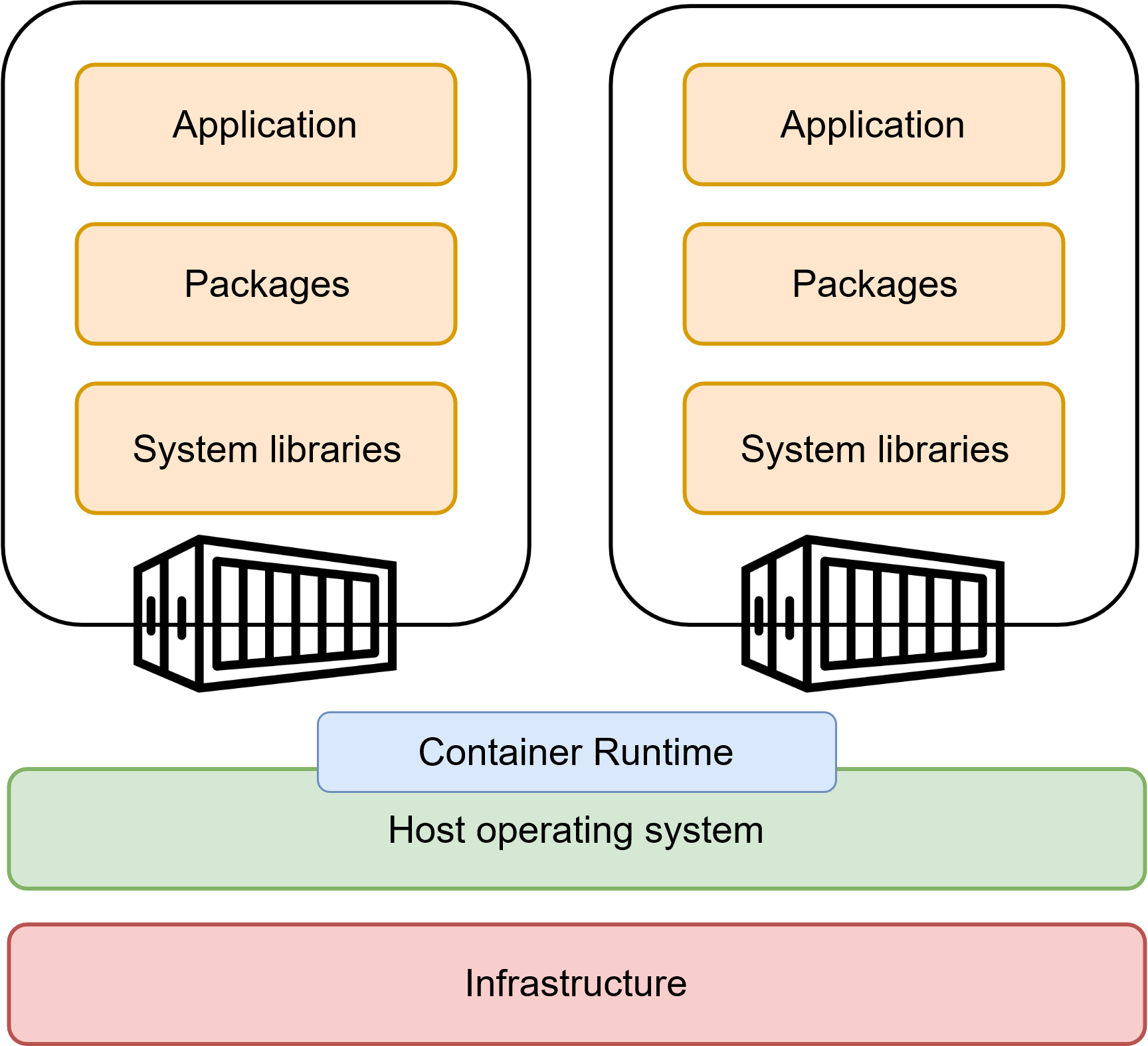
Note: Un conteneur est un groupe logique de ressources permettant d’encapsuler une application (par exemple, un batch R), les bibliothèques utilisées (ggplot, dplyr, etc.) et les librairies système nécessaires (l’interpréteur R, d’autres bibliothèques dépendantes du système d’exploitation, etc.) dans un contenant auto-suffisant. Les applications conteneurisées sont isolées les unes des autres grâce à la virtualisation, qui permet d’attribuer des ressources physiques spécifiques à chaque application tout en garantissant leur herméticité. Contrairement aux machines virtuelles (VM), qui virtualisent également le système d’exploitation (OS), les conteneurs s’appuient sur une forme de virtualisation légère : le conteneur partage l’OS de l’infrastructure hôte via le moteur de conteneurisation, dont le plus connu est Docker. En conséquence, les conteneurs sont beaucoup plus portables que les VM et peuvent être déployés et redistribués facilement.
Pour gérer plusieurs applications conteneurisées de manière systématique, les infrastructures conteneurisées s’appuient généralement sur un logiciel orchestrateur — le plus utilisé étant Kubernetes, un projet open source initialement développé par Google pour gérer ses nombreuses charges de travail conteneurisées en production (Vaño et al. 2023). Les orchestrateurs automatisent le processus de déploiement, de mise à l’échelle et de gestion des applications conteneurisées, coordonnant leur exécution sur différents serveurs. Cette propriété permet notamment de traiter de très grands volumes de données de manière distribuée : les conteneurs décomposent les opérations de traitement des données massives en une multitude de petites tâches, organisées par l’orchestrateur. Cela minimise les ressources requises tout en offrant une flexibilité supérieure aux architectures basées sur Hadoop (Zhang et al. 2018). Cette transition s’est d’ailleurs observée de manière très empirique à l’Insee dans le cadre du projet d’exploitation des données de caisse. Face aux difficultés computationnelles que posaient l’utilisation de ces données dans le calcul de l’IPC, un cluster Hadoop a d’abord été mis en place comme alternative à l’architecture existante. Une accélération des opérations de traitement des données pouvant aller jusqu’à un facteur 10 avait été observée, pour des opérations qui prenaient auparavant plusieurs heures (Leclair et al. 2019). Malgré cette amélioration des performances, ce type d’architectures n’a pas été pérennisée, principalement du fait de leur complexité et donc de leur coût de maintenance. La solution finalement retenue a été de mettre en place un environnement Spark sur Kubernetes, permettant de bénéficier des gains de performance liés à la distribution des calculs tout en bénéficiant de la flexibilité des infrastructures cloud.
L’autre choix fondamental dans une architecture cloud concerne le mode de stockage des données. Les conteneurs étant par construction sans état (stateless), il est nécessaire de prévoir une couche de persistence pour stocker à la fois les données brutes en entrée des traitements et les données transformées en sortie de ces derniers. Dans l’écosystème des infrastructures de données conteneurisées, le stockage dit “objet” s’est progressivement imposé comme référence, largement popularisée par l’implémentation S3 (Amazon Simple Storage Service) d’Amazon (Samundiswary and Dongre 2017). Afin de comprendre cette prédominance, il est utile de comparer ce mode de stockage aux autres modes existants.
Schématiquement, on peut distinguer trois grandes approches en matière de stockage : le stockage de fichiers (filesystem), le stockage par bloc (block storage) et le stockage d’objets (object storage). Le stockage de fichiers est le plus intuitif : les données sont organisées sous forme d’une structure hiérarchique de répertoires et de fichiers — comme sur un ordinateur personnel. Facile d’utilisation et adapté aux environnements traditionnels, ce mode de stockage passe difficilement à l’échelle et requiert des interventions manuelles pour monter et gérer les accès aux fichiers, ce qui restreint l’autonomie des utilisateurs et n’est pas adapté aux environnements de traitement éphémères comme les conteneurs. Le stockage par bloc propose un accès de bas niveau aux données sous forme de blocs contigus — à l’image du stockage sur un disque dur — garantissant des performances élevées et une faible latence. Il s’avère donc très pertinent pour des applications qui exigent un accès rapide aux données stockées — comme une base de données — mais passe là encore difficilement à l’échelle du fait du coût de la technologie et de la difficulté à leur faire croître horizontalement. Enfin, le stockage objet divise les fichiers de données en morceaux appelés “objets” qui sont ensuite stockés dans un référentiel unique, qui peut être distribué sur plusieurs machines. Chaque objet se voit attribuer un certain nombre de métadonnées (nom de l’objet, taille, date de création, etc.) dont un identifiant unique qui permet au système de retrouver l’objet sans la nécessité d’une structure hiérarchique comme celle d’un filesystem, réduisant drastiquement le coût du stockage.
Les différentes propriétés du stockage objet le rendent particulièrement pertinent pour construire une infrastructures conteneurisées pour la data science. D’abord, il est optimisé pour la scalabilité : les objets stockés ne sont pas limités en taille et la technologie sous-jacente permet un stockage efficient de fichiers potentiellement très volumineux, si besoin en les distribuant horizontalement. Ensuite, il est source d’autonomie pour les utilisateurs : en stockant les données sous forme d’objets enrichis de métadonnées et accessibles via des API REST standardisées, il permet aux utilisateurs d’interagir directement avec le stockage via leur code applicatif (en R, Python, etc.) tout en offrant une gestion très fine des permissions — jusqu’aux droits sur un fichier — vie des jetons d’accès, garantissant ainsi une traçabilité accrue des opérations effectuées. Enfin, le stockage objet joue un rôle clé dans l’objectif de construction d’une infrastructure découplée comme celle évoquée précédemment. Dans la mesure où les dépôts de données — appelés “buckets” — sont interrogeables via des requêtes HTTP standards, les environnements de calcul peuvent importer par le biais du réseau les données nécessaires aux traitements réalisés. Ainsi, les ressources de stockage et de calcul n’ont plus besoin d’être sur les mêmes machines ni même nécessairement dans le même lieu, et peuvent ainsi évoluer indépendamment en fonction des besoins spécifiques de l’organisation.
2.3 Les technologies cloud favorisent l’autonomie et la reproductibilité
Comprendre comment les choix technologiques décrits dans la discussion technique ci-dessus se révèlent pertinents dans le contexte des statistiques publiques nécessite un examen critique de l’évolution des environnements informatiques mis à disposition des statisticiens à l’Insee.
À la fin des années 2000, alors que la micro-informatique est à son apogée, une grande partie des ressources techniques utilisées par les statisticiens sont locales : le code et les logiciels de traitement sont situés sur des ordinateurs personnels, tandis que les données sont accessibles via un système de partage de fichiers. En raison de la puissance limitée des ordinateurs personnels, cette configuration restreignait considérablement la capacité des statisticiens à expérimenter avec des sources big data ou des méthodes statistiques intensives en calculs. Par ailleurs, cet état de faire impliquait des risques de sécurité liés à la dissemination des données confidentielles au sein de l’organisation. Afin de pallier ces limites, une transition progressive est opérée vers des infrastructures centralisées avec le projet d’Architecture Unifiée Statistique (AUS). Ce centre de calcul propose une forme de transition entre une informatique locale et une informatique centralisée : elle concentre toutes les ressources sur des serveurs centraux, mais recrée l’expérience du poste de travail via un accès par bureau distant au centre de calcul. La centralisation des ressources de calcul et la technologie des coffres sécurisés permettent aux statisticiens d’effectuer des traitements en self sur des données à la fois volumineuses et confidentielles qui étaient jusqu’alors impossibles. A ce jour, AUS — dans sa troisième version — reste l’infrastructure de référence pour les traitements réalisés “en self” : les environnements disponibles couvrent une majorité des besoins des statisticiens et contribuent de manière essentielle à la production statistique de l’institut.
À travers nos observations et nos discussions avec d’autres statisticiens, il est devenu évident que, bien que l’infrastructure informatique actuelle soutienne adéquatement les activités fondamentales de production statistique, elle restreint de manière notable la capacité des statisticiens à expérimenter librement et à innover. Le principal goulot d’étranglement dans cette organisation réside dans la dépendance des projets statistiques à la prise de décision centralisée en matière d’informatique, notamment en ce qui concerne l’allocation des ressources de calcul, l’accès au stockage partagé, l’utilisation de langages de programmation préconfigurés etc. En outre, ces dépendances conduisent souvent à un phénomène bien connu dans la communauté du développement logiciel, où les priorités des développeurs — itérer rapidement pour améliorer continuellement les fonctionnalités — entrent souvent en conflit avec l’objectif des équipes informatiques de garantir la sécurité et la stabilité des processus. À l’inverse, nous comprenons que les pratiques modernes en data science reflètent une implication accrue des statisticiens dans le développement et l’orchestration informatique de leurs opérations de traitement de données, au-delà de la simple phase de conception ou de validation. Les nouvelles infrastructures de data science doivent donc prendre en compte ce rôle élargi de leurs utilisateurs, en leur offrant plus d’autonomie que les infrastructures traditionnelles.
Nous soutenons que les technologies cloud sont une solution puissante pour offrir aux statisticiens une autonomie bien plus grande dans leur travail quotidien, favorisant ainsi une culture de l’innovation. Grâce au stockage d’objets, les utilisateurs obtiennent un contrôle direct sur la couche de stockage, leur permettant d’expérimenter avec des sources de données diverses sans être limités par les espaces de stockage souvent restreints et alloués par les départements informatiques. La conteneurisation permet aux utilisateurs de personnaliser leurs environnements de travail selon leurs besoins spécifiques — qu’il s’agisse de langages de programmation, de bibliothèques système ou de versions de packages — tout en leur offrant la flexibilité nécessaire pour adapter leurs applications à la puissance de calcul et aux capacités de stockage requises. Par construction, les conteneurs favorisent également le développement d’applications portables, permettant des transitions plus fluides entre les environnements (développement, test, pré-production, production), en garantissant que les applications peuvent être exécutées sans difficulté, évitant ainsi les problèmes liés aux incohérences d’environnement. Enfin, avec des outils d’orchestration tels que Kubernetes, les statisticiens peuvent déployer plus facilement des applications et des API, tout en automatisant l’ensemble du processus de construction. Cette capacité s’aligne avec l’approche DevOps, qui préconise la création de preuves de concept de manière itérative, plutôt que de chercher à développer la solution optimale (mais chronophage) pour un objectif préalablement défini (Leite et al. 2019).

Note: Dans un environnement conteneurisé, les applications sont créées à partir de spécifications écrites dans des manifestes — un paradigme connu sous le nom d’“infrastructure as code”. Dans un script, conventionnellement nommé Dockerfile, les data scientists spécifient l’environnement de travail de leur application : le code de l’application, les logiciels à inclure (par exemple, R), les packages utilisés pour leurs opérations de traitement (par exemple, le package sf pour le calcul géospatial), ainsi que les librairies système dépendant de l’OS appelées par ces packages (par exemple GDAL, une bibliothèque standard pour traiter les formats utilisés par la majorité des packages traitant des données géospatiales). En particulier, les versions de ces différentes dépendances de l’application peuvent être précisément spécifiées, ce qui garantit la reproductibilité des calculs effectués. Une fois le Dockerfile correctement spécifié, une étape de construction (build) génère une image, c’est-à-dire une forme empaquetée et compressée de l’environnement qui permet de lancer l’application à l’identique. Les images créées de cette manière sont portables : elles peuvent être facilement distribuées — via un registre d’images, comme celui de GitLab à l’Insee — et exécutées de manière reproductible sur n’importe quelle infrastructure disposant d’un moteur de conteneurisation. L’exécution de l’image donne naissance à un conteneur, c’est à dire une instance vivante et déployée de l’application contenue dans l’image.
Outre la scalabilité et l’autonomie, ces choix architecturaux favorisent également la reproductibilité des calculs statistiques. Le concept de reproductibilité — à savoir la capacité de reproduire le résultat d’une expérience en appliquant la même méthodologie aux mêmes données — est un critère fondamental de validité scientifique (McNutt 2014). Il est également très pertinent dans le domaine des statistiques publiques, car il constitue un facteur de transparence, essentielle pour établir et maintenir la confiance du public (European Commission, n.d.). Favoriser la reproductibilité dans la production statistique implique de concevoir des solutions de traitement capables de produire des statistiques reproductibles, tout en étant partageables entre pairs (Luhmann et al. 2019). Les infrastructures informatiques traditionnelles — qu’il s’agisse d’un ordinateur personnel ou d’une infrastructure partagée avec un accès à distance — sont limitées à cet égard. Construire un projet ou calculer un simple indicateur statistique dans ces environnements implique généralement une série d’étapes manuelles (installation des bibliothèques système, des binaires du langage de programmation, des packages du projet, gestion des versions conflictuelles, etc.) qui ne peuvent pas être pleinement reproduites d’un projet à l’autre du fait de la persistence de l’environnement sous-jacent. En comparaison, les conteneurs sont reproductibles par construction : leur processus de construction implique de définir précisément toutes les ressources nécessaires sous la forme d’un ensemble d’opérations standardisées, allant de la machine quasi-nue à l’application en cours d’exécution (Moreau, Wiebels, and Boettiger 2023). De plus, ces environnements reproductibles peuvent être facilement partagés avec des pairs en les publiant sur des registres ouverts (par exemple, un registre de conteneurs comme DockerHub ou celui de GitLab) en plus du code source de l’application (par exemple, sur une forge logicielle comme GitHub ou GitLab). Cette approche améliore considérablement la réutilisation des projets de données, favorisant un modèle de développement et d’innovation basé sur la collaboration communautaire.