3 Onyxia : un projet open source pour construire des plateformes de data science sur des technologies cloud
Cette section examine comment Onyxia, un projet open source initié par l’Insee, démocratise l’accès aux technologies cloud pour les statisticiens en fournissant des environnements modernes de data science favorisant l’autonomie. Nous analysons comment cette initiative s’inscrit dans l’objectif général de création des “connaissances communes” en promouvant et en développant des logiciels facilement réutilisables dans le domaine des statistiques publiques et ailleurs.
3.1 Rendre les technologies cloud accessibles aux statisticiens
Notre veille technologique et notre revue de la littérature ont mis en évidence les technologies cloud, en particulier la conteneurisation et le stockage d’objets, comme des éléments clés pour construire une plateforme de data science à la fois scalable et flexible. En nous appuyant sur ces enseignements, nous avons mis en place notre premier cluster Kubernetes dans les locaux de l’Insee en 2020, en l’intégrant avec MinIO, un système de stockage d’objets open source conçu pour fonctionner de manière fluide avec Kubernetes. Cependant, nos premières expérimentations ont révélé un obstacle majeur à l’adoption généralisée des technologies cloud : la complexité de leur intégration. C’est une considération importante lorsqu’il s’agit de construire des architectures de données qui privilégient la modularité — une caractéristique essentielle pour atteindre la flexibilité que nous visons1. Toutefois, la modularité des composants architecturaux implique également que toute application de données lancée sur le cluster doit être configurée pour communiquer avec tous les autres composants. Par exemple, dans un environnement big data, la configuration de Spark pour fonctionner sur Kubernetes tout en interagissant avec des ensembles de données stockés dans MinIO nécessite de nombreuses et complexes configurations (définition des points d’entrée, des jetons d’accès, etc.), une compétence qui dépasse généralement l’expertise des statisticiens.
1 Un exemple révélateur de l’importance de construire une architecture modulaire est la capacité de basculer entre différentes sources de stockage (on-premise, fournisseur de cloud public, etc.). La solution de stockage que nous avons choisie, MinIO, est compatible avec l’API S3 d’Amazon, qui est devenue un standard de facto dans l’écosystème cloud grâce au succès de la solution de stockage S3 d’Amazon AWS. Ainsi, les organisations qui choisissent d’utiliser Onyxia ne sont pas liées à une solution de stockage spécifique : elles peuvent opter pour n’importe quelle solution conforme aux standards définis par l’API S3.
Par exemple, grâce à la compatibilité de MinIO avec l’API S3 d’Amazon, la source de stockage pourrait facilement être remplacée par une solution gérée par un autre fournisseur de cloud public, sans nécessiter de modifications substantielles.
Cette idée est véritablement le fondement du projet Onyxia : choisir des technologies qui favorisent l’autonomie ne remplira pas cet objectif si leur complexité constitue une barrière à une adoption généralisée au sein de l’organisation. Ces dernières années, les statisticiens de l’Insee ont déjà dû s’adapter à un environnement en évolution en ce qui concerne leurs outils quotidiens : passer de logiciels propriétaires (SAS®) à des outils open source (R, Python), s’approprier des technologies qui améliorent la reproductibilité (contrôle de version avec Git), consommer et développer des API, etc. Ces changements, rendant leur travail de plus en plus semblable à celui de développeurs logiciels, impliquent déjà des efforts considérables en termes de formation et des modifications des pratiques de travail quotidiennes. Dans ce contexte, l’adoption des technologies cloud dépend totalement de leur accessibilité immédiate.

Pour combler cet écart, nous avons développé Onyxia, une application qui agit essentiellement comme une interface entre les composants modulaires qui composent l’architecture (voir Figure 1). Le point d’entrée principal pour l’utilisateur est une application web ergonomique2 qui lui permet de lancer des services à partir d’un catalogue de data science (voir Section 3.3) sous forme de conteneurs exécutés sur le cluster Kubernetes sous-jacent. Le lien entre l’interface utilisateur (UI) et Kubernetes est assurée par une API 3, qui transforme essentiellement la demande d’application de l’utilisateur en un ensemble de manifestes nécessaires pour déployer des ressources Kubernetes. Pour une application donnée, ces ressources sont regroupées sous la forme de charts Helm, une méthode populaire pour empaqueter des applications potentiellement complexes sur Kubernetes (Gokhale et al. 2021). Bien que les utilisateurs puissent configurer un service pour l’adapter à leurs besoins, la plupart du temps, ils se contentent de lancer un service prêt à l’emploi avec des paramètres par défaut et commencent à développer immédiatement. Ce point illustre parfaitement la valeur ajoutée d’Onyxia pour faciliter l’adoption des technologies cloud. En injectant automatiquement les informations d’authentification et de configuration dans les conteneurs lors de leur initialisation, nous veillons à ce que les utilisateurs puissent lancer et gérer des services de data science dans lesquels ils interagissent sans difficulté avec les données de leur bucket sur MinIO, leurs informations sensibles (jetons, mots de passe) dans un outil de gestion des secrets tel que Vault, etc. Cette injection automatique, associée à la pré-configuration des environnements de data science dans les catalogues d’images4 et de charts Helm5 d’Onyxia, permet aux utilisateurs d’exécuter des scripts potentiellement complexes — comme des calculs distribués avec Spark sur Kubernetes à l’aide de données stockées sur S3, ou l’entraînement de modèles d’apprentissage profond utilisant un GPU — sans se heurter aux difficultés techniques liées à la configuration.
3.2 Des choix architecturaux visant à favoriser l’autonomie
Le projet Onyxia repose sur quelques principes structurants, avec un thème central : favoriser l’autonomie, à la fois au niveau organisationnel et individuel. Tout d’abord, au niveau de l’organisation, en évitant l’enfermement propriétaire. Pour obtenir un avantage concurrentiel, de nombreux fournisseurs de cloud commerciaux développent des applications et protocoles spécifiques que les clients doivent utiliser pour accéder aux ressources cloud, mais qui ne sont pas interopérables, compliquant considérablement les migrations potentielles vers une autre plateforme cloud (Opara-Martins, Sahandi, and Tian 2016). Sachant cela, une tendance émerge vers l’adoption de stratégies neutres vis-à-vis des clouds (Opara-Martins, Sahandi, and Tian 2017) afin de réduire la dépendance à des solutions spécifiques d’un seul fournisseur. En revanche, l’utilisation d’Onyxia n’est intrinsèquement pas restrictive : lorsqu’une organisation choisit de l’utiliser, elle choisit les technologies sous-jacentes — la conteneurisation et le stockage d’objets — mais pas la solution en elle-même. La plateforme peut être déployée sur n’importe quel cluster Kubernetes, qu’il soit on-premise ou sur des clouds commerciaux. De même, Onyxia a été conçue pour être utilisée avec MinIO, car il s’agit d’une solution de stockage d’objets open source, mais il est également possible de l’utiliser avec les solutions de stockage d’objets proposées par divers fournisseurs de cloud (AWS, GCP, etc.).
Onyxia favorise également l’autonomie au niveau des utilisateurs. Les logiciels propriétaires qui ont été intensivement utilisés dans les statistiques publiques — comme SAS ou STATA — induisent également un phénomène d’enfermement propriétaire. Les coûts des licences sont élevés et peuvent évoluer rapidement, et les utilisateurs se retrouvent dépendants de certaines méthodes de calcul, empêchant une montée en compétences progressive. Au contraire, Onyxia aspire à être amovible ; nous souhaitons améliorer la familiarité et le confort des utilisateurs avec les technologies cloud sous-jacentes plutôt que de devenir un élément permanent travail quotidien. Un exemple illustratif de cette philosophie est l’approche de la plateforme concernant les actions des utilisateurs : pour les tâches effectuées via l’interface utilisateur, comme le lancement d’un service ou la gestion des données, nous fournissons aux utilisateurs les commandes terminal équivalentes, promouvant ainsi une compréhension plus approfondie de ce qui se passe réellement lors du déclenchement d’une action. De plus, tous les services proposés via le catalogue d’Onyxia sont open source.
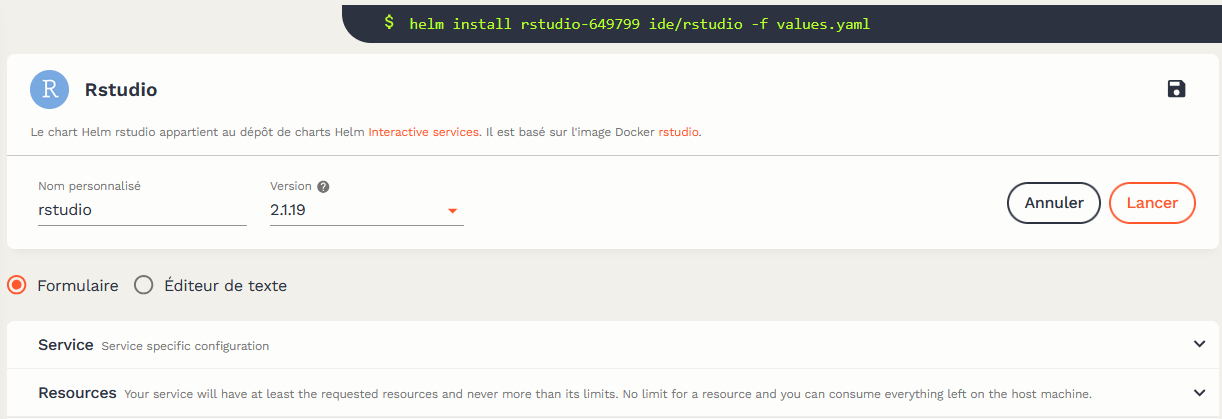
Note: Les services du catalogue d’Onyxia peuvent être utilisés tels quels ou configurés par les utilisateurs pour répondre à leurs besoins spécifiques. Afin de limiter la dépendance des utilisateurs vis-à-vis d’Onyxia, chaque action effectuée par l’utilisateur via l’interface utilisateur est accompagnée de la commande exacte exécutée sur le cluster Kubernetes.
Naturellement, la manière dont Onyxia rend les statisticiens plus autonomes dans leur travail dépend de leurs besoins et de leur familiarité avec les compétences informatiques. Les statisticiens qui souhaitent simplement accéder à des ressources de calcul importantes pour expérimenter avec de nouvelles sources de données ou méthodes statistiques pourront, en quelques clics, accéder à des environnements de data science préconfigurés et faciles à utiliser, leur permettant de commencer à expérimenter immédiatement. Cependant, de nombreux utilisateurs souhaitent aller plus loin et développer de véritables prototypes d’applications de production pour leurs projets : configurer des scripts d’initialisation pour adapter les environnements à leurs besoins, déployer une application interactive offrant des visualisations de données aux utilisateurs de leur choix, ou encore déployer d’autres services que ceux disponibles dans nos catalogues. Pour permettre à ces utilisateurs avancés de continuer à repousser les limites de l’innovation, Onyxia leur donne accès au cluster Kubernetes sous-jacent. Cela signifie que les utilisateurs peuvent ouvrir librement un terminal sur un service interactif et interagir avec le cluster — dans les limites de leur namespace — afin d’appliquer des ressources personnalisées et de déployer des applications ou services personnalisés.
Au-delà de l’autonomie et de la scalabilité, les choix architecturaux d’Onyxia favorisent également la reproductibilité des calculs statistiques. Dans le paradigme des conteneurs, l’utilisateur doit apprendre à gérer des ressources qui sont par nature éphémères, puisqu’elles n’existent qu’au moment de leur mobilisation effective. Cela encourage l’adoption de bonnes pratiques de développement, notamment la séparation du code — hébergé sur une forge interne ou open source telle que GitLab ou GitHub —, des données — stockées sur une solution de stockage spécifique, comme MinIO —, et de l’environnement de calcul. Bien que cela impose un coût d’entré non négligeable aux utilisateurs, cela les aide également à concevoir leurs projets sous forme de pipelines, c’est-à-dire une série d’étapes séquentielles avec des données en entrées et productions finales bien définies (semblables à un graphe orienté acyclique, ou DAG). Les projets développés de cette manière sont généralement plus reproductibles et transposables — ils peuvent fonctionner sans problème sur différents environnements de calcul — et sont ainsi plus facilement partageables avec leurs pairs.
3.3 Un large catalogue de services pour couvrir le cycle de vie complet des projets de data science
Lors du développement de la plateforme Onyxia, notre intention était de fournir aux statisticiens un environnement complet conçu pour accompagner le développement de bout en bout des projets de data science. Comme illustré dans Figure 3, la plateforme propose une vaste gamme de services couvrant l’ensemble du cycle de vie d’un projet de data science.

L’utilisation principale de la plateforme est le déploiement d’environnements de développement interactifs (IDE), tels que RStudio, Jupyter ou VSCode. Ces IDE sont équipés des dernières versions des principaux langages de programmation open source couramment utilisés par les statisticiens publics (R, Python, Julia), ainsi que d’une vaste collection de librairies fréquemment employées en data science pour chaque langage. Afin de garantir que les services restent à jour et cohérents entre eux, nous maintenons nos propres images Docker sous-jacentes et les mettons à jour chaque semaine. Ces images sont entièrement open source6 et peuvent donc être réutilisée en dehors d’Onyxia.
Comme discuté dans les sections précédentes, la couche de persistance de ces environnements interactifs est principalement assurée par MinIO, la solution de stockage d’objets par défaut d’Onyxia. Étant basé sur une API REST standardisée, les fichiers peuvent être facilement interrogés depuis R ou Python à l’aide de librairies de haut niveau. Cela représente en soi une étape importante pour garantir la reproductibilité : les données ne sont pas sauvegardés localement, puis spécifiés via des chemins propres à une infrastructure ou un système de fichiers particulier. Au contraire, les fichiers sont spécifiés sous forme de requêtes HTTP, rendant la structure globale des projets bien plus extensible. D’après notre expérience, le paradigme du stockage d’objets répond très bien aux besoins de la plupart des projets statistiques que nous accompagnons. Cependant, des services de bases de données supplémentaires, tels que PostgreSQL et MongoDB, sont disponibles pour les applications ayant des besoins spécifiques, notamment celles nécessitant des capacités de traitement transactionnel en ligne (OLTP) ou un stockage orienté documents.
Comme Onyxia a été développée pour permettre l’expérimentation avec des sources de données volumineuses et des méthodes d’apprentissage automatique, nous proposons également des services optimisés pour passé à l’échelle facilement. Par exemple, des frameworks comme Spark et Trino, qui permettent d’effectuer des calculs distribués au sein d’un cluster Kubernetes. Ces services sont préconfigurés pour s’intégrer parfaitement avec le stockage S3, facilitant ainsi la création de pipelines de données intégrés et efficaces.
Au-delà de la simple expérimentation, notre objectif est de permettre aux statisticiens de passer des phases de test à des projets de qualité proche de celle requise en production afin de réduire le coût lors de la transmission d’un projet d’une équipe de production vers une équipe informatique. Conformément aux principes de l’approche DevOps, cela implique de faciliter le déploiement de prototypes et leur amélioration continue au fil du temps. À cette fin, nous proposons un ensemble de services open source visant à automatiser et industrialiser le processus de déploiement d’applications (ArgoCD, Argo-Workflows, MLflow). Pour les projets exploitant des modèles d’apprentissage automatique, les statisticiens peuvent exposer leurs modèles via des API, les déployer en utilisant les outils susmentionnés et gérer leur cycle de vie grâce à un gestionnaire d’API (par exemple, Gravitee). La Section 4 illustrera comment ces outils, en particulier MLflow, ont joué un rôle central dans la mise en production de modèles d’apprentissage automatique à l’Insee, en lien avec les principes de MLOps.
Dans la Section 3.2, nous avons souligné qu’un des principes fondamentaux de conception d’Onyxia était d’éviter l’enfermement propriétaire. Dans cette optique, les organisations qui instancient Onyxia sont libres de personnaliser les catalogues pour répondre à leurs besoins spécifiques, ou même de créer leurs propres catalogues indépendamment des offres par défaut d’Onyxia. Cette flexibilité garantit aux organisations de ne pas être limité à une solution ou à un fournisseur unique, et qu’elles peuvent adapter la plateforme à l’évolution de leurs besoins.
3.4 Construire des communs numérique : un projet open source et une plateforme d’innovation ouverte
En tant qu’initiative entièrement open source, le projet Onyxia vise à construire des « connaissances communes » en promouvant et en développant des logiciels facilement réutilisables dans les statistiques publiques et ailleurs (Schweik 2006). Cela concerne, tout d’abord, les composants sur lesquels repose Onyxia : à la fois ses briques technologiques (Kubernetes, MinIO, Vault) et l’ensemble des services du catalogue, qui sont open source. Plus important encore, tout le code du projet est disponible publiquement sur GitHub7. Associée à une documentation détaillée8, cette transparence facilite grandement la possibilité pour d’autres organisations de créer des instances de plateformes de data science basées sur le logiciel Onyxia et de les adapter à leurs besoins spécifiques (voir Figure 4). Cela a permis au projet d’attirer une communauté croissante de contributeurs issus des statistiques publiques (Statistique Norvège), des ONG (Mercator Ocean9), des centres de recherche et même de l’industrie, favorisant ainsi une transition progressive vers une gouvernance plus décentralisée du projet.
9 Lien vers l’instance Onyxia de Mercator Ocean : https://datalab.dive.edito.eu/
10 Plus d’informations à propos de ce projet disponibles à https://cros.ec.europa.eu/dashboard/aiml4os
Dans les prochaines années, l’implication des INS (Instituts Nationaux de Statistique) du système statistique européen devrait augmenter, puisque le SSPCloud a été choisie comme plateforme data science de référence dans le cadre du projet AIML4OS10.
Une autre manière majeure de construire des communs est le développement et le maintien d’une instance de démonstration du projet Onyxia, le SSP Cloud (Comte, Degorre, and Lesur 2022). Cette plateforme, équipée de ressources de calcul extensives et évolutives11, est conçue comme un bac à sable pour expérimenter avec les technologies cloud et les nouvelles méthodes de science des données. Le catalogue complet des services d’Onyxia est disponible sur cette plateforme, permettant aux utilisateurs motivés d’aller au-delà de la simple expérimentation en produisant des « preuves de concept » avec une autonomie totale concernant la configuration et l’orchestration de leurs services.
11 Sur le plan matériel, le SSP Cloud est constitué d’un cluster Kubernetes d’environ 20 serveurs, pour une capacité totale de 10 To de RAM, 1100 processeurs, 34 GPU et 150 To de stockage.
13 Lien vers les canaux de discussion https://www.tchap.gouv.fr/#/room/#SSPCloudXDpAw6v:agent.finances.tchap.gouv.fr et https://join.slack.com/t/3innovation/shared_invite/zt-19tht9hvr-bZGMdW8AV_wvd5kz3wRSMw
Au-delà de ses capacités techniques, le SSP Cloud incarne les principes de l’innovation ouverte (Chesbrough 2003). Déployé sur internet12, il est accessible non seulement aux employés de l’Insee, mais également, plus largement, aux agences gouvernementales françaises, aux universités françaises et aux autres INS européens. Il est dédié à l’expérimentation des méthodes de data science en utilisant des données ouvertes. Ainsi, les projets menés sur cette plateforme mettent en lumière l’abondance croissante des jeux de données publiés en libre accès par les organisations publiques ou privés, faisant écho à la loi pour une République numérique de 2016. La nature fondamentalement collaborative du SSP Cloud s’est avérée particulièrement bénéfique pour l’organisation d’événements innovants, tels que des hackathons — tant au niveau national qu’international — et dans le domaine académique. Il est devenu une ressource intégrale pour plusieurs universités et Grandes Écoles en France, favorisant l’utilisation d’environnements cloud et reproductibles, tout en évitant l’effet d’enfermement propriétaire dû à une dépendance excessive des institutions éducatives envers des solutions cloud propriétaires. En conséquence, la plateforme est désormais largement utilisée dans le service statistique publique français et ailleurs, avec environ 1000 utilisateurs uniques par mois début 2025. Ces utilisateurs forment une communauté dynamique grâce à un canal de discussion centralisé13 ; ils contribuent à améliorer l’expérience utilisateur en signalant des bugs, en proposant de nouvelles fonctionnalités et en participant ainsi directement au projet.