4 Cas d’usage : adopter les pratiques MLOps pour améliorer la codification de l’APE
Ce chapitre vise à illustrer comment l’Insee a réussi à déployer son premier modèle de machine learning (ML) en production. Il propose une description détaillée de l’approche MLOps à laquelle ce projet s’est efforcé d’adhérer, en mettant l’accent sur les différentes technologies employées. En particulier, nous soulignons le rôle crucial des technologies cloud qui ont permis la construction du projet de manière itérative, ainsi que la manière dont Onyxia a grandement facilité cette construction en fournissant des environnements de développement flexibles et des outils pour entraîner, déployer et surveiller les modèles des modèles d’apprentissage automatique. De plus, la convergence entamée des environnement de self (\(LS^3\)), de développement (KubeDev) et de production (KubeProd) constitue une réelle avancer pour faciliter la mise en production d’autres modèles d’apprentissage automatique (un modèle de codification de la PCS a également été déployé récemment). Le projet présenté est totalement disponible en open source 1 et reste en cours de développement actif.
4.1 Fluidifier la codification de l’APE à l’aide de méthodes d’apprentissage automatique
4.1.1 Motivation
Les tâches de codification sont des opérations bien connues des instituts statistiques, et peuvent parfois être complexes en raison de la taille des nomenclatures. À l’Insee, un outil sophistiqué appelé Sicore a été développé dans les années 1990 pour effectuer diverses tâches de classification (Meyer and Rivière 1997). Cet outil repose sur un ensemble de règles déterministes permettant d’identifier les codes corrects à partir d’un libellé textuel en se basant sur un fichier de référence comprenant un certain nombre d’exemples. Chaque libellé d’entrée est soumis à ces règles et, lorsqu’un code correct est reconnu, il est attribué au libellé. En revanche, si le libellé n’est pas reconnu, il doit être classer manuellement par un agent de l’Insee.
Deux raisons principales ont motivé l’expérimentation de nouvelles méthodes de codification.
Premièrement, un changement interne est survenu avec la refonte du répertoire statistique des entreprises en France (Sirene), qui liste toutes les entreprises et leur attribue un identifiant unique utilisé par les administrations publiques, le numéro Siren. Les principaux objectifs de cette refonte étaient d’améliorer la gestion quotidienne du répertoire pour les agents de l’Insee et de réduire les délais d’attente pour les entreprises. Par ailleurs, au niveau national, le gouvernement a lancé, dans le cadre de la loi PACTE (n° 2019-486 du 22 mai 2019), un guichet unique pour les formalités des entreprises, offrant aux chefs d’entreprises plus de flexibilité dans la description de leurs activités principales les rendant ainsi plus verbeux que précédemment. Les tests initiaux ont révélé que Sicore n’était plus adapté pour effectuer la codification APE, puisque seulement \(30\%\) des liasses d’entreprises étaient automatiquement codées, et donc \(70\%\) devait être codés manuellement par des gestionnaires. Les équipes en charge du répertoire Sirene, déjà confrontées à des charges de travail importantes et à de fortes contraintes opérationnelles, ne pouvaient pas voir leur charge augmentée par une re-codification manuelle, une tâche à la fois chronophage et peu stimulante. Ainsi, en mai 2022, la décision a été prise d’expérimenter de nouvelles méthodes pour effectuer cette tâche de codification, avec pour objectif de les utiliser en production dès le 1er janvier 2023, date de lancement du nouveau répertoire Sirene.
Trois parties prenantes étaient donc impliquées dans ce projet : l’équipe métier (division RIAS2), responsable de la gestion du répertoire statistique des entreprises ; l’équipe informatique, en charge du développement des applications liés au fonctionnement du répertoire ; et l’équipe d’innovation (l’unité SSP Lab), responsable de la mise en œuvre du nouvel outil de codification.
2 Répertoire Interadministratif Sirene
4.1.2 La tâche de codification
Le projet présenté consiste en un problème classique de classification dans le cadre de traitement de langage naturel. À partir d’une description textuelle de l’activité d’une entreprise, l’objectif est de prédire la classe associée dans la nomenclature APE. Cette classification présente la particularité d’être hiérarchique et comporte cinq niveaux différents3 : section, division, groupe, catégorie et sous-catégorie. Au total, la nomenclature comprend 732 sous-classes, ce qui correspond au niveau le plus fin de la nomenclature et pour lequel on souhaite réaliser notre codification. La table Table 1 fournit un exemple de cette structure hiérarchique.
3 En réalité, il existe cinq niveaux en France, mais seulement quatre au niveau européen.
| Niveau | NAF | Libellé | Taille |
|---|---|---|---|
| Section | H | Transports et entreposage | 21 |
| Division | 52 | Entreposage et services auxiliaires des transports | 88 |
| Groupe | 522 | Services auxiliaires des transports | 272 |
| Catégorie | 5224 | Manutention | 615 |
| Sous-catégorie | 5224A | Manutention portuaire | 732 |
Avec la mise en place du guichet unique, les chefs d’entreprise décrivent désormais leur activité dans un champ de texte libre. Par conséquent, les nouveaux libellés diffèrent fortement des libellés harmonisés précédemment reçus. Il a donc été décidé de travailler avec des modèles d’apprentissage automatique, reconnus pour leur efficacité sur les tâches de classification supervisée de texte (Li et al. 2022). Cela représente un changement de paradigme significatif pour l’Insee, puisque le machine learning n’est traditionnellement pas utilisé dans la production des statistiques publiques. De plus, la perspective de mettre le nouveau modèle en production a été envisagée dès le début du projet, orientant de nombreux choix méthodologiques et techniques. Ainsi, plusieurs décisions stratégiques ont dû être rapidement prises, notamment en ce qui concerne la méthodologie, le choix d’un environnement de développement cohérent avec l’environnement de production cible, et l’adoption de méthodes de travail collaboratif.
4.1.3 Méthodologie
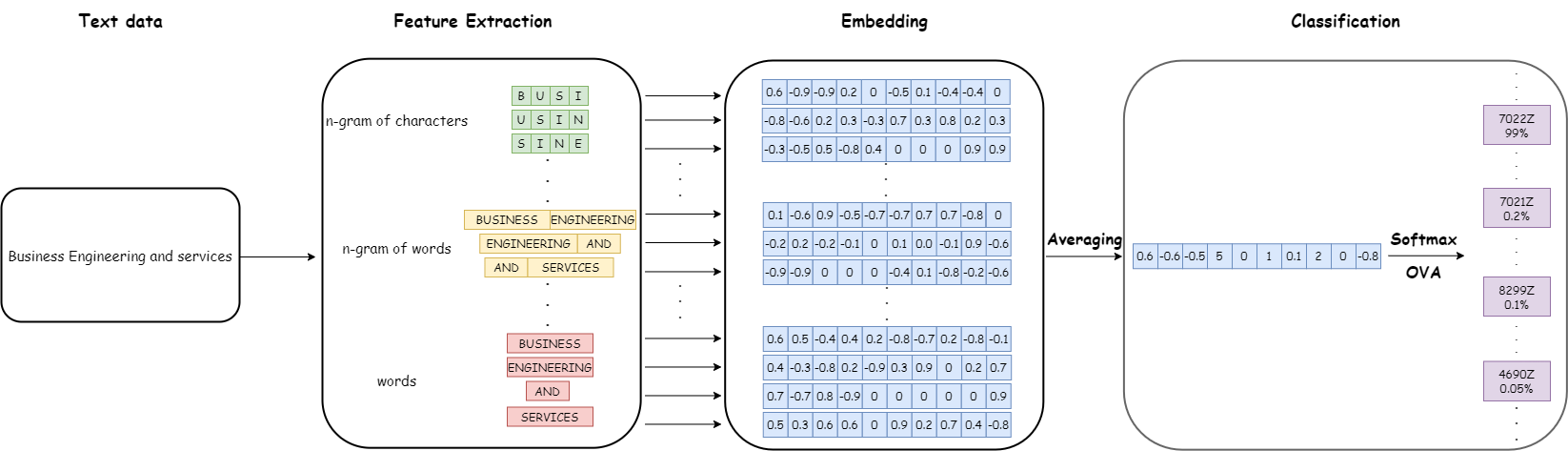
La classification textuelle à partir des champs de texte libre fournis par les chefs d’entreprise est une tâche complexe : les descriptions d’activité sont relativement courtes et contiennent donc peu d’information statistique, peuvent inclure des fautes d’orthographe et nécessitent souvent une expertise métier pour être correctement codées. Pour une telle tâche, les méthodes traditionnelles d’analyse textuelle, comme la vectorisation par comptage ou TF-IDF, sont souvent insuffisantes, tandis que les méthodes d’intégration basées sur des réseaux de neurones tendent à donner de meilleurs résultats (Li et al. 2022). Cependant, ces architectures nécessitent souvent des ressources de calcul importantes, et peuvent exiger du matériel spécifique, comme des GPUs, afin obtenir une latence acceptable lors de l’inférence. Ces contraintes nous ont, dans un premier temps, éloignés des modèles les plus performants, tels que les modèles Transformer, et orientés vers le modèle fastText (Joulin et al. 2016), un réseau de neurone plus simple basé sur des plongements lexicaux. Le modèle fastText est extrêmement rapide à entraîner, et l’inférence ne nécessite pas de GPU pour obtenir un temps de latence faible. En outre, le modèle a donné d’excellents résultats pour notre cas d’usage, qui, compte tenu des contraintes de temps et de ressources humaines, étaient largement suffisants pour améliorer le processus existant. Enfin, l’architecture du modèle est relativement simple, ce qui facilite la communication et l’adoption au sein des différentes équipes de l’Insee.
Le modèle fastText repose sur une approche de sac de mots (bag-of-words) pour obtenir des plongements lexicaux et une couche de classification basée sur la régression logistique. L’approche sac de mots consiste à représenter un texte comme un ensemble de représentations vectorielles de chacun des mots qui le composent. La spécificité du modèle fastText, par rapport à d’autres approches basées sur des plongements lexicaux, est que les plongements lexicaux ne sont pas seulement calculés sur les mots, mais aussi sur des n-grams de mots et de caractères, fournissant ainsi plus de contexte et réduisant les biais liés aux fautes d’orthographe. Ensuite, le plongement lexical d’une phrase est calculé comme une fonction des plongements lexicaux des mots (et n-grams de mots et de caractères), généralement une moyenne. Dans le cas de la classification textuelle supervisée, la matrice de plongement et les poids du classifier sont appris simultanément lors de l’entraînement par descente de gradient, en minimisant la fonction de perte d’entropie croisée.
Figure 1 présente la pipeline complete des opérations effectuées par fastText sur un exemple de texte en entrée.
4.2 Une approche orientée production et MLOps
Dès le début du projet, l’objectif était d’aller au-delà de la simple expérimentation et de mettre le modèle en production. Par ailleurs, ce projet pilote avait également pour but de servir de modèle pour les futurs projets de machine learning à l’Insee. Nous avons donc cherché à appliquer les meilleures pratiques de développement dès les premières étapes du projet : respect des standards de qualité de code de la communauté, utilisation de scripts pour le développement au lieu de notebooks, construction d’une structure modulaire semblable à un package, etc. Cependant, par rapport aux projets de développement traditionnels, les projets de machine learning présentent des caractéristiques spécifiques qui nécessitent l’application d’un ensemble de bonnes pratiques complémentaire, regroupées sous le nom de MLOps.
4.2.1 Du DevOps au MLOps
Le DevOps est un ensemble de pratiques conçu pour favoriser la collaboration entre les équipes de développement (Dev) et d’opérations (Ops). L’idée fondamentale est d’intégrer tout le cycle de vie d’un projet dans un continuum automatisé. Un outil important pour atteindre cette continuité sont les pipelines CI/CD. Avec l’intégration continue (Continuous Integration ou CI), chaque commit de nouveau code source déclenche un processus d’opérations standardisées, telles que la construction de l’application, son test et sa mise à disposition sous forme de version. Ensuite, le déploiement continu (Continuous Deployment ou CD) consiste en des outils pour automatiser le déploiement du nouveau code et limiter les interventions manuelles, tout en garantissant une supervision appropriée pour assurer la stabilité et la sécurité des processus. Cette approche favorise un déploiement plus rapide et continu des modifications ou ajouts nécessaires de fonctionnalités. En outre, en encourageant la collaboration entre les équipes, le DevOps accélère également le cycle d’innovation, permettant aux équipes de résoudre les problèmes au fur et à mesure qu’ils surviennent et d’intégrer efficacement les retours tout au long du cycle de vie du projet.
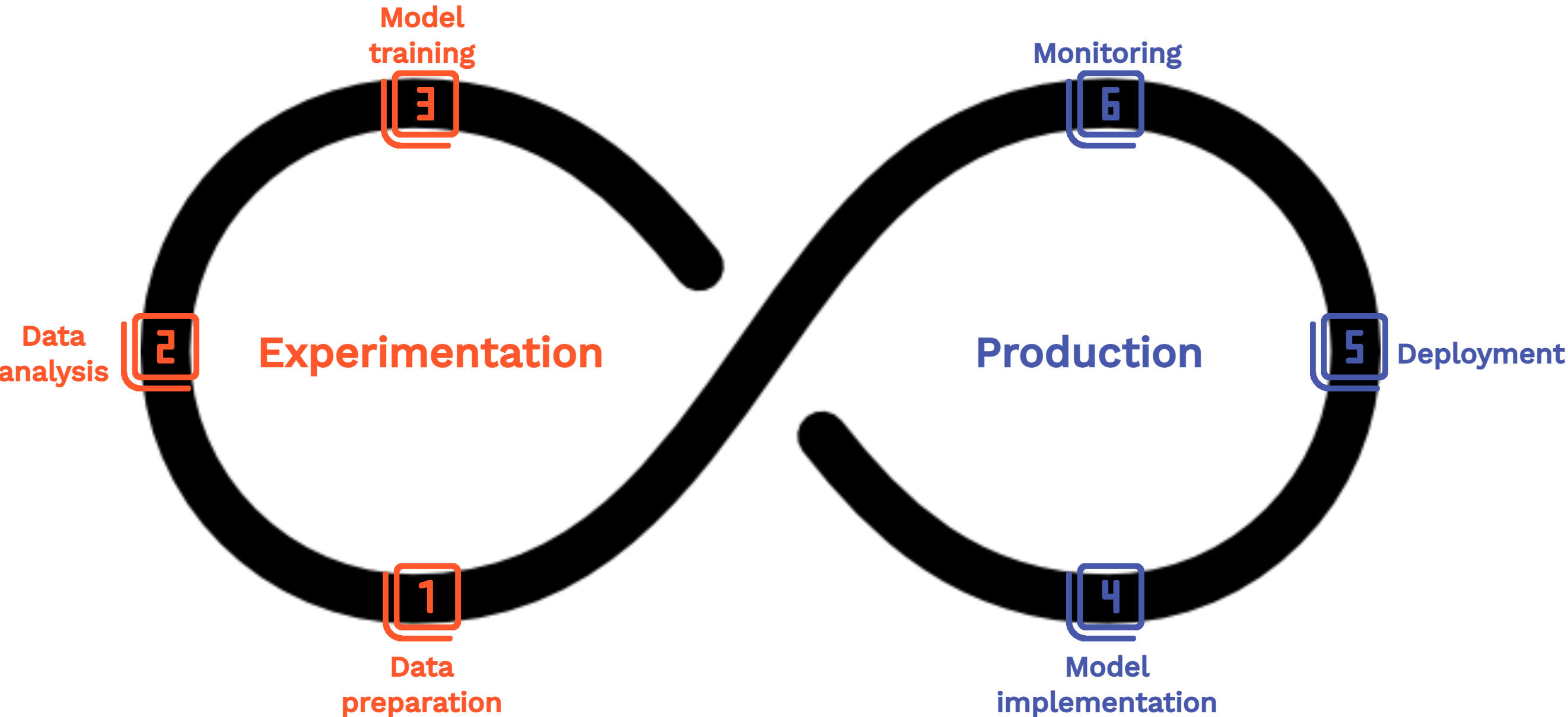
L’approche MLOps peut être vue comme une extension du DevOps, développée pour relever les défis spécifiques liés à la gestion du cycle de vie des modèles de ML. Fondamentalement, DevOps et MLOps partagent le même objectif : construire des logiciels de manière plus automatisée et robuste. La principale différence réside dans le fait qu’avec le MLOps, le logiciel inclut également une composante de machine learning. Par conséquent, le cycle de vie du projet devient plus complexe. Le modèle de ML sous-jacent doit être réentraîné régulièrement afin d’éviter toute perte de performance au fil du temps. L’ingestion des données doit également être intégrée au processus, car de nouvelles données peuvent être utilisées pour améliorer les performances. Figure 2 présente les étapes d’un projet de ML en utilisant une représentation continue, comme cela se fait traditionnellement en DevOps. Cela illustre un principe fondamental du MLOps : la nécessité d’une amélioration continue, décrite plus en détail dans Section 4.2.2.
4.2.2 Principes du MLOps
Le MLOps repose sur quelques principes fondamentaux qui sont essentiels pour construire des applications de machine learning évolutives et prêtes pour le passage en production. Ces principes visent à relever les défis spécifiques associés aux chaînes de production de machine learning.
Le principe le plus fondamental du MLOps est l’amélioration continue, reflétant la nature itérative des projets de ML. Lors de la phase d’expérimentation, le modèle est développé à partir d’un ensemble de données d’entraînement, qui diffère généralement des données de production à certains égards. Une fois le modèle déployé en production, les nouvelles données sur lesquelles le modèle doit effectuer des prédictions peuvent révéler des informations sur ses performances et ses éventuelles lacunes. Ces informations nécessitent un retour à la phase d’expérimentation, où les data scientists ajustent ou redéfinissent leurs modèles pour corriger les problèmes découverts ou améliorer la précision. Ce principe souligne donc l’importance de construire une boucle de rétroaction permettant des améliorations continues tout au long du cycle de vie d’un modèle. L’automatisation, en particulier grâce à l’utilisation de pipelines CI/CD, joue un rôle crucial en rendant la transition entre les phases d’expérimentation et de production plus fluide. La surveillance (monitoring) est également une composante essentielle de ce processus : un modèle déployé en production doit être continuellement analysé pour détecter d’éventuelles dérives importantes susceptibles de réduire ses performances prédictives et nécessitant des ajustements supplémentaires, comme un ré-entraînement.
Un autre objectif majeur du MLOps est de promouvoir la reproductibilité, en garantissant que toute expérience de ML puisse être reproduite de manière fiable avec les mêmes résultats. Les outils de MLOps facilitent ainsi une sauvegarde détaillée des expériences de ML, incluant les étapes de prétraitement des données, les hyperparamètres des modèles utilisés et les algorithmes d’entraînement. Les données, modèles et codes sont versionnés, permettant aux équipes de revenir à des versions antérieures si une mise à jour ne donne pas les résultats escomptés. Enfin, ces outils aident à produire des spécifications détaillées de l’environnement informatique utilisé pour produire ces expériences — comme les versions des bibliothèques — et reposent souvent sur des conteneurs pour reproduire les mêmes conditions que celles dans lesquelles le modèle initial a été développé.
Enfin, le MLOps vise à favoriser le travail collaboratif. Les projets basés sur le ML impliquent généralement une gamme plus large de profils : équipes métier et équipes de data science d’un côté, développeurs et équipes de production informatique de l’autre. Comme le DevOps, le MLOps met donc l’accent sur la nécessité d’une culture collaborative et d’éviter le travail en silos. Les outils de MLOps incluent généralement des fonctionnalités collaboratives, telles que des stockages centralisés pour les modèles de ML ou les caractéristiques (features) de ML, qui facilitent le partage des composants entre les membres des équipes et limitent la redondance.
4.2.3 Implémentation avec MLflow
De nombreux outils ont été développés pour mettre en œuvre l’approche MLOps dans des projets concrets. Tous visent à appliquer, sous une forme ou une autre, les principes fondamentaux décrits précédemment. Dans ce projet, nous avons choisi de nous appuyer sur un outil open-source populaire nommé MLflow4. Ce choix ne reflète pas une supériorité inhérente de MLflow par rapport à d’autres outil, mais s’explique par un ensemble de bonnes propriétés associées à MLflow, qui en font une solution particulièrement pertinente pour notre cas d’usage. Tout d’abord, il couvre l’intégralité du cycle de vie des projets de ML, tandis que d’autres outils peuvent être plus spécialisés sur certaines parties seulement. Ensuite, il offre une grande interopérabilité grâce à une bonne interface avec les bibliothèques populaires de ML — telles que PyTorch, Scikit-learn, XGBoost, etc. — et prend en charge plusieurs langages de programmation — notamment Python, R et Java, couvrant ainsi le spectre des langages couramment utilisés à l’Insee. Enfin, MLflow s’est révélé très facile d’utilisation, encourageant ainsi son adoption par les membres du projet et facilitant la collaboration continue entre eux.
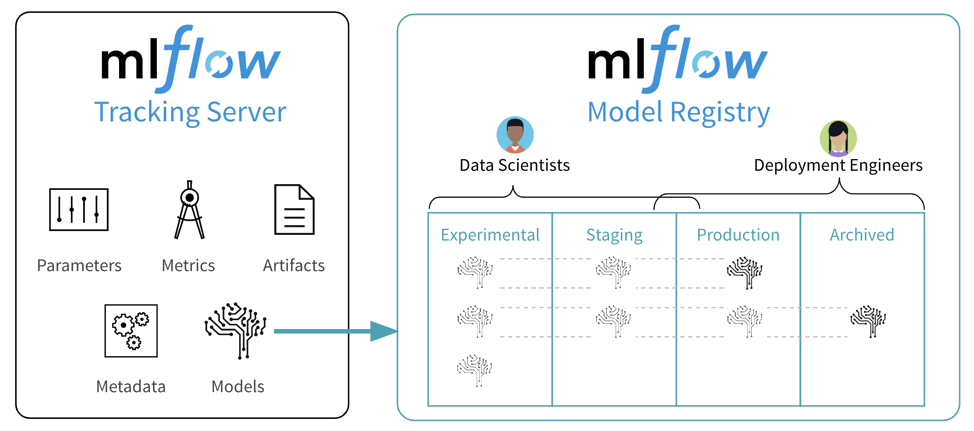
MLflow fournit un cadre cohérent pour opérationnaliser les principes du MLOps efficacement au sein des projets de ML. Les data scientists peuvent encapsuler leur travail dans des MLflow Projects qui regroupent le code ML et ses dépendances, garantissant que chaque projet soit reproductible et puisse être ré-exécuté de manière identique. Un projet s’appuie sur un MLflow Model, un format standardisé compatible avec la plupart des bibliothèques de ML et offrant une méthode normalisée pour déployer le modèle, par exemple via une API. Cette interopérabilité et cette standardisation sont essentielles pour soutenir l’amélioration continue du projet, puisque les modèles entraînés avec une multitude de packages peuvent être facilement comparés ou remplacés les uns par les autres sans casser le code existant.
À mesure que les expériences avec différents modèles progressent, le Tracking Server enregistre des informations détaillées sur chaque exécution — hyperparamètres, métriques, artefacts et données — ce qui favorise à la fois la reproductibilité et facilite la phase de sélection des modèles grâce à une interface utilisateur ergonomique. Une fois la phase d’expérimentation terminée, les modèles sélectionnés sont rajoutés dans le Model Registry, où ils sont versionnés et prêts pour le déploiement. Cet entrepôt sert de “magasin” centralisé pour les modèles, permettant aux différents membres ou équipes du projet de gérer collaborativement le cycle de vie du projet.
Figure 3 illustre les composants principaux de MLflow et la manière dont ils facilitent un flux de travail plus continu et collaboratif au sein d’un projet de ML.
4.3 Faciliter le développement itératif avec les technologies cloud
Bien que l’amélioration continue soit un principe fondamental du MLOps, elle est également très exigeante. En particulier, elle nécessite de concevoir et de construire un projet sous la forme d’une pipeline intégrée, dont les différentes étapes sont principalement automatisées, de l’ingestion des données jusqu’à la surveillance du modèle en production. Dans ce contexte, le développement itératif est essentiel pour construire un produit minimum viable qui sera ensuite affiné et amélioré au fil du temps. Cette section illustre comment les technologies cloud, via le projet Onyxia, ont été déterminantes pour construire le projet sous forme de composants modulaires interconnectés, renforçant ainsi considérablement la capacité de raffinement continu au fil du temps.
4.3.1 Un environnement de développement flexible
Dans un projet de ML, la flexibilité de l’environnement de développement est essentielle. Premièrement, en raison de la diversité des tâches à accomplir : collecte des données, prétraitement, modélisation, évaluation, inférence, surveillance, etc. Deuxièmement, parce que le domaine du ML évolue rapidement, il est préférable de construire une application de ML sous forme d’un ensemble de composants modulaires afin de pouvoir mettre à jour certains éléments sans perturber l’ensemble de la pipeline. Comme discuté dans la Section 2.2, les technologies cloud permettent de créer des environnements de développement modulaires et évolutifs.
Cependant, comme également abordé dans la Section 3, l’accès à ces ressources ne suffit pas. Un projet de ML nécessite une grande variété d’outils pour se conformer aux principes du MLOps : stockage des données, environnements de développement interactifs pour expérimenter librement, outils d’automatisation, outils de surveillance, etc. Bien que ces outils puissent être installés sur un cluster Kubernetes, il est essentiel de les rendre disponibles aux data scientists de manière intégrée et préconfigurée pour faciliter leur adoption. Grâce à son catalogue de services et à l’injection automatique de configurations dans les services, Onyxia permet de construire des projets qui reposent sur plusieurs composants cloud capables de communiquer facilement entre eux.
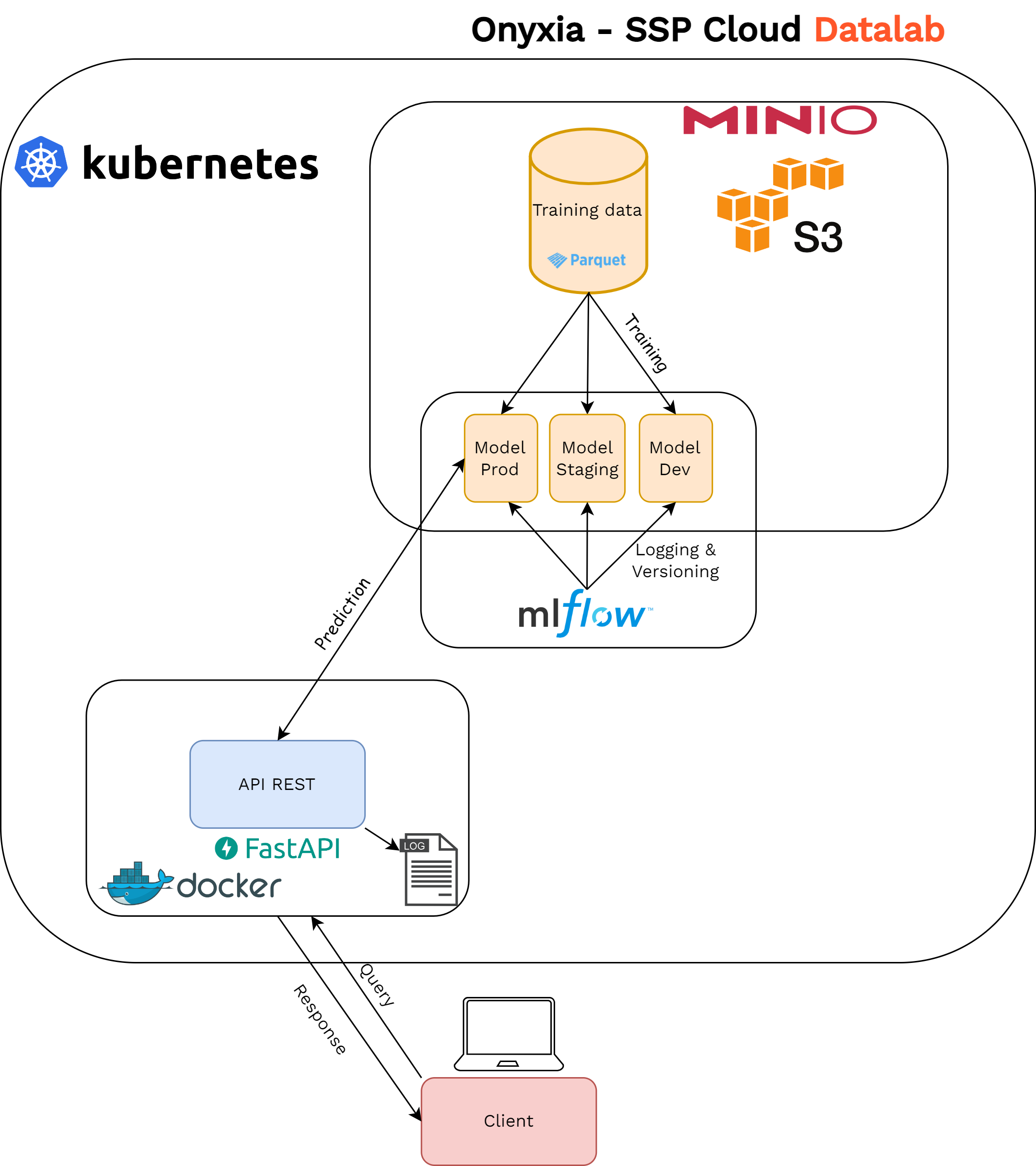
La manière dont l’entraînement du modèle a été réalisé pour ce projet illustre bien la flexibilité offerte par Onyxia pendant la phase d’expérimentation. Tout le code utilisé pour l’entraînement est écrit en Python au sein d’un service VSCode. Grâce à l’injection automatique des identifiants personnels S3 dans chaque service au démarrage, les différents utilisateurs du projet peuvent interagir directement avec les données d’entraînement stockées dans un bucket S3 sur MinIO, la solution de stockage d’objets par défaut d’Onyxia. Toutes les expériences menées lors de la phase de sélection du modèle sont consignées dans une instance partagée de MLflow, qui enregistre les données sur une instance PostgreSQL automatiquement lancée sur Kubernetes, tandis que les artefacts (modèles entraînés et métadonnées associées) sont stockés sur MinIO.
Le modèle a été entraîné en utilisant une recherche exhaustive (grid-search) pour l’ajustement des hyperparamètres et évalué par validation croisée (cross-validation). Cette combinaison, reconnue pour offrir une meilleure évaluation des performances de généralisation du modèle, nécessite cependant d’importantes ressources de calcul en raison de la nature combinatoire du test de nombreuses combinaisons d’hyperparamètres. Dans notre cas, nous avons tiré parti d’Argo Workflows, un moteur de workflows open source conçu pour orchestrer des tâches parallèles sur Kubernetes, chaque tâche étant spécifiée comme un conteneur indépendant. Cela a permis de comparer facilement les performances des différents modèles entraînés et de sélectionner le meilleur en utilisant les outils de comparaison et de visualisation disponibles dans l’interface utilisateur de MLflow.
En résumé, la phase d’entraînement a été rendue à la fois efficace et reproductible grâce à l’utilisation de nombreux composants modulaires interconnectés — une caractéristique distinctive des technologies cloud — mis à disposition des data scientists grâce à Onyxia.
4.3.2 Déploiement d’un modèle
Une fois que les modèles candidats ont été optimisés, évalués et qu’un modèle performant a été sélectionné, l’étape suivante consiste à le rendre accessible aux utilisateurs finaux de l’application. Fournir simplement le modèle entraîné sous forme d’artefact, ou même uniquement le code pour l’entraîner, n’est pas une manière optimale de le transmettre, car cela suppose que les utilisateurs disposent des ressources, de l’infrastructure et des connaissances nécessaires pour l’entraîner dans les mêmes conditions. L’objectif est donc de rendre le modèle accessible de manière simple et interopérable, c’est-à-dire qu’il doit être possible de l’interroger avec divers langages de programmation et par d’autres applications de manière programmatique.
Dans ce contexte, nous avons choisi de déployer le modèle via une API REST. Cette technologie est devenue une norme pour servir des modèles de ML, car elle présente plusieurs avantages. Tout d’abord, elle s’intègre parfaitement dans un environnement orienté cloud : comme les autres composants de notre stack, elle permet d’interroger le modèle en utilisant des requêtes HTTP standard, ce qui contribue à la modularité du système. De plus, elle est interopérable : reposant sur des technologies standards pour les requêtes (requêtes HTTP) et les réponses (généralement une chaîne formatée en JSON), elle est largement indépendante du langage de programmation utilisé pour effectuer les requêtes. Enfin, les API REST offrent une grande évolutivité grâce à leur conception sans état (stateless)5. Chaque requête contient toutes les informations nécessaires pour être comprise et traitée, ce qui permet de dupliquer facilement l’API sur différentes machines pour répartir une charge importante — un processus connu sous le nom de scalabilité horizontale.
5 La conception sans état (stateless) fait référence à une architecture système où chaque requête d’un client au serveur contient toutes les informations nécessaires pour comprendre et traiter la requête. Cela signifie que le serveur ne stocke aucune information sur l’état du client entre les requêtes, ce qui permet de traiter chaque requête indépendamment. Cette conception simplifie l’évolutivité et renforce la robustesse du système, car n’importe quel serveur peut gérer une requête sans dépendre des interactions précédentes.
Nous avons développé l’API servant le modèle avec FastAPI6, un framework web rapide et bien documenté pour construire des APIs avec Python. Le code de l’API et les dépendances logicielles nécessaires sont encapsulés dans une image Docker, ce qui permet de la déployer sous forme de conteneur sur le cluster Kubernetes. L’un des avantages majeurs de Kubernetes est sa capacité d’adapter la puissance de l’API — via le nombre de pods d’API effectivement déployés — en fonction de la demande, tout en fournissant un équilibrage de charge automatique. Au démarrage, l’API récupère automatiquement le modèle approprié depuis l’entrepôt de modèles MLflow stocké sur MinIO. Enfin, comme le code de l’application est packagé en utilisant l’API standardisée de MLflow — permettant par exemple d’intégrer directement l’étape de prétraitement dans chaque appel API — le code d’inférence reste largement uniforme, quel que soit le framework de ML sous-jacent utilisé. Ce processus de déploiement est résumé dans Figure 4.
4.3.3 Construction d’une pipeline intégrée
L’architecture construite à ce stade reflète déjà certains principes importants du MLOps. L’utilisation de la conteneurisation pour déployer l’API, ainsi que celle de MLflow pour suivre les expérimentations pendant le développement du modèle, garantit la reproductibilité des prédictions. L’utilisation de l’entrepôt central de modèles fourni par MLflow facilite la gestion du cycle de vie des modèles de manière collaborative. De plus, la modularité de l’architecture laisse de la place pour des améliorations ultérieures, puisque des composants modulaires peuvent être ajoutés ou modifiés facilement sans casser la structure du projet dans son ensemble. Comme nous le verrons dans les sections suivantes, cette propriété s’est avérée essentielle pour construire le projet de manière itérative, permettant d’ajouter une couche de surveillance du modèle (Section 4.3.4) et un composant d’annotation (Section 4.3.6) afin de favoriser l’amélioration continue du modèle en intégrant “l’humain dans le cycle de vie du modèle de ML” (human in the loop).
Cependant, la capacité à affiner l’architecture de base de manière itérative nécessite également une plus grande continuité dans le processus. À ce stade, le processus de déploiement implique plusieurs opérations manuelles. Par exemple, l’ajout d’une nouvelle fonctionnalité à l’API nécessiterait de construire une nouvelle image, de la taguer, de mettre à jour les manifests Kubernetes utilisés pour déployer l’API et de les appliquer sur le cluster afin de remplacer l’instance existante avec un temps d’arrêt minimal. De même, un changement de modèle servi via l’API nécessiterait une simple modification du code, mais plusieurs étapes manuelles pour mettre à jour la version sur le cluster. En conséquence, les data scientists ne sont pas totalement autonomes pour prototyper et tester des versions mises à jour du modèle ou de l’API, ce qui limite le potentiel d’amélioration continue.
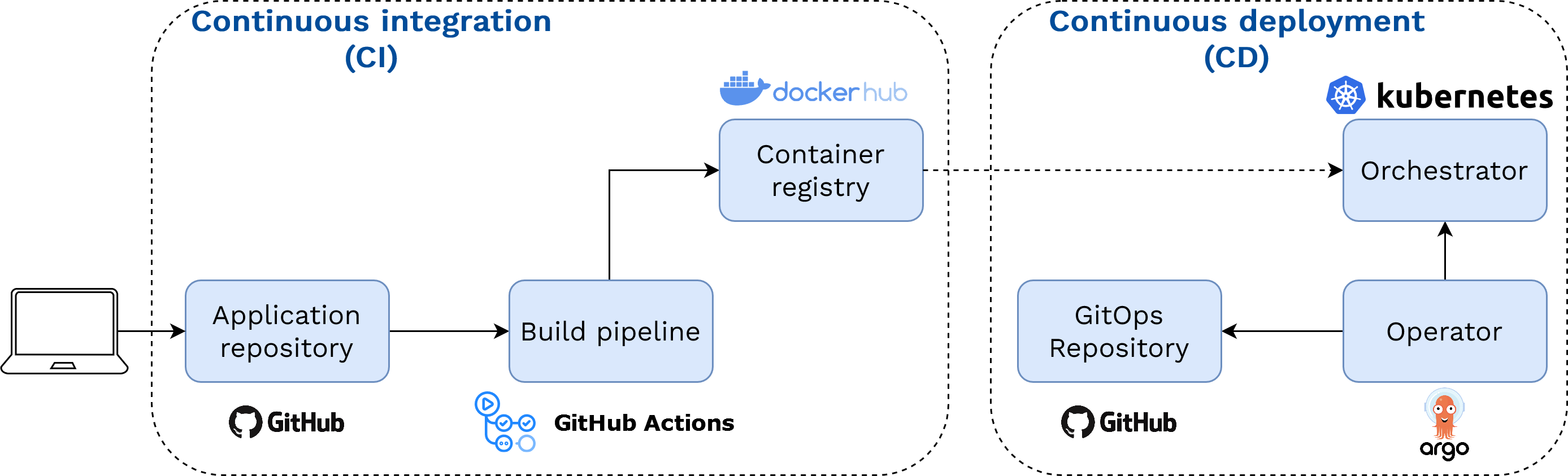
Afin d’automatiser ce processus, nous avons construit une pipeline CI/CD — un concept déjà présenté dans Section 4.2.1 — intégrant ces différentes étapes. Figure 5 illustre notre implémentation spécifique de la pipeline CI/CD. Toute modification du code du dépôt de l’API, associée à un nouveau tag, déclenche un processus de build CI (implémenté avec GitHub Actions) de l’image Docker, qui est ensuite publiée sur un hub public de conteneurs (DockerHub). Cette image peut ensuite être récupérée et déployée par l’orchestrateur de conteneurs (Kubernetes) en spécifiant et en appliquant manuellement de nouveaux manifests pour mettre à jour les ressources Kubernetes de l’API.
Cependant, cette approche présente un inconvénient : elle limite la reproductibilité du déploiement, car chaque ressource est gérée indépendamment par l’orchestrateur, et le cycle de vie du déploiement de l’API dans son ensemble n’est pas contrôlé. Pour pallier cette lacune, nous avons intégré la partie déploiement dans une pipeline CD basée sur l’approche GitOps : les manifests des ressources de l’API sont stockés dans un dépôt Git. L’état de ce dépôt “GitOps” est surveillé par un opérateur Kubernetes (ArgoCD), de sorte à ce que toute modification des manifests de l’application soit directement propagée au déploiement sur le cluster. Dans cette pipeline intégrée, la seule action nécessaire pour que le data scientist déclenche une mise à jour de l’API est de modifier le tag de l’image de l’API indiquant la version à déployer.
4.3.4 Surveillance d’un modèle en production
Une fois la phase initiale de développement du projet terminée — incluant l’entraînement, l’optimisation et le déploiement du modèle pour les utilisateurs —, il est crucial de comprendre que les responsabilités du data scientist ne s’arrêtent pas là. Traditionnellement, le rôle du data scientist se limite souvent à l’entraînement et à la sélection du modèle à déployer, le déploiement étant généralement délégué au département informatique. Cependant, une spécificité des projets de ML est que, une fois en production, le modèle n’a pas encore atteint la fin de son cycle de vie : il doit être surveillé en permanence afin d’éviter toute dégradation indésirable des performances. La surveillance continue du modèle déployé est essentielle pour garantir la conformité des résultats aux attentes, anticiper les changements dans les données et améliorer le modèle de manière itérative. Même en production, les compétences du data scientist sont nécessaires.
Le concept de surveillance peut avoir différentes significations selon le contexte de l’équipe impliquée. Pour les équipes informatiques, il s’agit principalement de vérifier l’efficacité technique de l’application, notamment en termes de latence, de consommation de mémoire ou d’utilisation du disque de stockage. En revanche, pour les data scientists ou les équipes métier, la surveillance est davantage centrée sur le suivi méthodologique du modèle. Cependant, le suivi en temps réel des performances d’un modèle de ML est souvent une tâche complexe, car la vérité terrain (ground truth) n’est généralement pas connue au moment de la prédiction. Il est donc courant d’utiliser des proxys pour détecter les signes éventuels de dégradation des performances. Deux types principaux de dégradation d’un modèle ML sont généralement distingués. Le premier est le data drift, qui se produit lorsque les données utilisées pour l’inférence en production diffèrent significativement des données utilisées lors de l’entraînement. Le second est le concept drift, qui survient lorsqu’un changement dans la relation statistique entre les variables explicatives et la variable cible est observé au fil du temps. Par exemple, le mot “Uber” était habituellement associé à des codes liés aux services de taxis. Cependant, avec l’apparition des services de livraison de repas comme “Uber Eats”, cette relation entre le libellé et le code associé a changé. Il est donc nécessaire de repérer au plus tôt ces changements afin de ne pas dégrader la codification.
Dans le cadre de notre projet, l’objectif est d’atteindre le taux le plus élevé possible de libellés correctement classifiés, tout en minimisant le nombre de descriptions nécessitant une intervention manuelle. Ainsi, notre objectif est de distinguer les prédictions correctes des prédictions incorrectes sans avoir accès au préalable à la vérité terrain. Pour y parvenir, nous calculons un indice de confiance, défini comme la différence entre les deux scores de confiance les plus élevés parmi les résultats renvoyés par le modèle. Pour une description textuelle donnée, si l’indice de confiance dépasse un seuil déterminé, la description est automatiquement codée. Sinon, elle est codée manuellement par un agent de l’Insee. Cette tâche de codification manuel est néanmoins assistée par le modèle ML : via une application qui interroge l’API, l’agent visualise les cinq codes les plus probables selon le modèle. Le seuil choisi pour l’indice de confiance est un paramètre que l’équipe métier peut utiliser pour arbitrer entre la charge de travail qu’elle est disposée à assumer pour la reprise gestionnaire et le taux d’erreurs qu’elle est prête à tolérer.
4.3.5 Définition du seuil de codification automatique et surveillance en production
La définition du seuil pour la codification automatique des descriptions textuelles a été une étape cruciale de ce processus, nécessitant un compromis entre un taux élevé de codification automatique et une performance optimale de celle-ci. Pour surveiller le comportement du modèle en production, nous avons développé un tableau de bord interactif permettant de visualiser plusieurs métriques d’intérêt pour les équipes métier. Parmi ces métriques figurent le nombre de requêtes par jour et le taux de codification automatique quotidien, pour un seuil donné pour l’indice de confiance. Cette visualisation permet aux équipes métier de connaître le taux de codification automatique qu’elles auraient obtenu si elles avaient choisi différents seuils. Le tableau de bord représente également la distribution des indices de confiance obtenus et compare des fenêtres temporelles afin de détecter des changements dans les distributions des prédictions renvoyées par le modèle7. Enfin, les indices de confiance peuvent être analysés à des niveaux de granularité plus fins, basés sur les niveaux d’agrégation de la classification statistique, pour identifier les classes les plus difficiles à prédire et celles qui sont plus ou moins fréquentes.
7 Ces changements de distribution sont généralement vérifiés en calculant des distances statistiques — telles que la distance de Bhattacharyya, la divergence de Kullback-Leibler ou la distance de Hellinger — et/ou en effectuant des tests statistiques — tels que le test de Kolmogorov–Smirnov ou le test du khi-deux.
8 Idéalement, les frameworks existants devraient être privilégiés par rapport aux solutions sur mesure pour adopter des routines standardisées. Lors de la construction de ce composant du pipeline, nous avons constaté que les frameworks cloud existants pour l’analyse des logs présentaient d’importantes limites. Cela constitue une piste d’amélioration pour le projet.
9 Successeur de R Markdown, Quarto est devenu un outil essentiel. Il unifie les fonctionnalités de plusieurs packages très utiles de l’écosystème R Markdown tout en offrant une prise en charge native de plusieurs langages de programmation, dont Python et Julia en plus de R. Il est de plus en plus utilisé à l’Insee pour produire des documents reproductibles et les exporter dans divers formats.
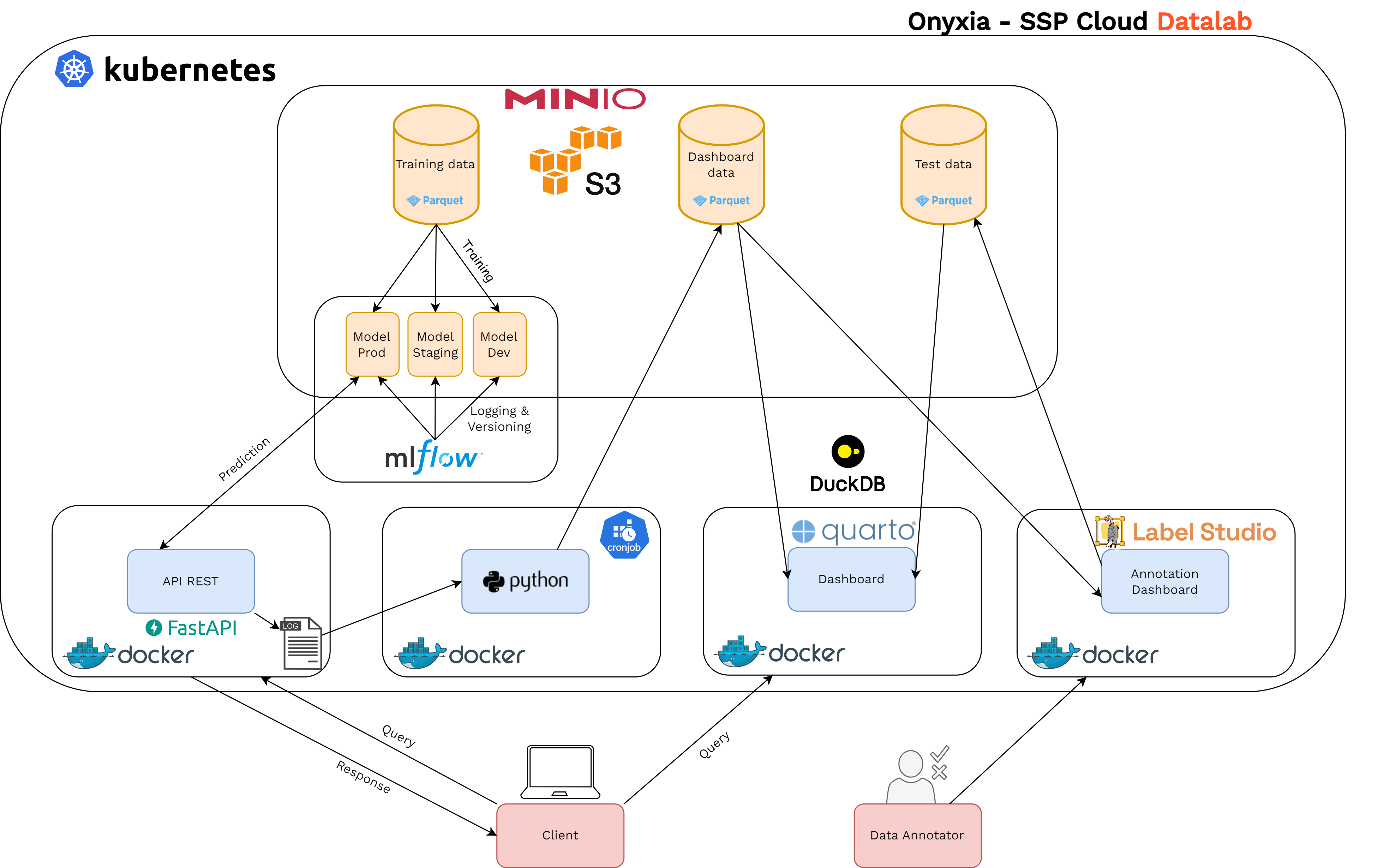
Figure 6 présente les composants ajoutés à l’architecture du projet pour fournir le tableau de bord de surveillance décrit ci-dessus. Tout d’abord, nous avons mis en place un processus simple en Python (deuxième composant de la rangée inférieure), qui récupère quotidiennement les logs de l’API et les transforme en fichiers partitionnés au format Parquet8. Ensuite, nous avons utilisé Quarto9 pour construire un tableau de bord interactif (troisième composant de la rangée inférieure). Pour calculer les diverses métriques présentées dans le tableau de bord, les fichiers Parquet sont interrogés via le moteur optimisé DuckDB. À l’instar de l’API, le tableau de bord est construit et déployé sous forme de conteneur sur le cluster Kubernetes, et ce processus est également automatisé grâce à une pipeline CI/CD. Le composant d’annotation (quatrième composant de la rangée inférieure) est discuté dans la section suivante.
4.3.6 Favoriser l’amélioration continue du modèle
La composante de surveillance de notre modèle fournit une vue détaillée et essentielle de l’activité du modèle en production. En raison de la nature dynamique des données de production, les performances des modèles de ML ont tendance à diminuer avec le temps. Pour favoriser l’amélioration continue du modèle, il est donc essentiel de mettre en place des stratégies permettant de surmonter ces pertes de performance. Une stratégie couramment utilisée est le réentraînement périodique du modèle, nécessitant la collecte de nouvelles données d’entraînement plus récentes et donc plus proches de celle observées en production.
Plusieurs mois après le déploiement de la première version du modèle en production, le besoin de mettre en œuvre un processus d’annotation continue est devenu de plus en plus évident pour deux raisons principales. Premièrement, un échantillon de référence (gold standard) n’était pas disponible lors de la phase d’expérimentation. Nous avons donc utilisé un sous-ensemble des données d’entraînement pour l’évaluation, tout en sachant que la qualité de la labelisation n’était pas optimale. La collecte continue d’un échantillon de référence permettrait ainsi d’obtenir une vue réaliste des performances du modèle en production sur des données réelles, en particulier sur les données codifiées automatiquement. Deuxièmement, la refonte de la nomenclature statistique APE prévue en 2025 impose aux INS d’adopter la dernière version. Cette révision, qui introduit des changements importants, nécessite une adaptation du modèle et surtout la création d’un nouveau jeu de données d’entraînement. L’annotation de l’ancien jeu de données d’entraînement selon la nouvelle nomenclature statistique est donc indispensable.
Dans ce contexte, une campagne d’annotation a été lancée début 2024 pour construire de manière continue un jeu de données de référence. Cette campagne est réalisée sur le SSP Cloud10 en utilisant le service Label Studio, un outil open source d’annotation offrant une interface ergonomique et disponible dans le catalogue d’Onyxia. Figure 6 montre comment le composant d’annotation (quatrième composant de la rangée inférieure) a pu être intégré facilement dans l’architecture du projet grâce à sa nature modulaire. En pratique, un échantillon de descriptions textuelles est tiré aléatoirement des données passées par l’API au cours des trois derniers mois. Cet échantillon est ensuite soumis à l’annotation par des experts APE via l’interface de Label Studio. Les résultats de l’annotation sont automatiquement sauvegardés sur MinIO, transformés au format Parquet, puis intégrés directement dans le tableau de bord de surveillance pour calculer et observer diverses métriques de performance du modèle. Ces métriques offrent une vision beaucoup plus précise des performances réelles du modèle sur les données de production, et permet notamment de détecter les cas les plus problématiques.
En parallèle, une campagne d’annotation pour construire un nouveau jeu d’entraînement adapté à la NAF 2025 a également été réalisée. En exploitant à la fois les nouvelles données d’entraînement et les métriques de performance dérivées de l’échantillon de référence, nous visons à améliorer la précision du modèle de manière itérative grâce à des réentraînements périodiques et automatique dès lors que le moteur de codification aura migré sur le cluster Kubernetes de production.