Atelier pour découvrir la récupération de données via des API
Les API (Application Programming Interface) sont un mode d’accès aux données en expansion. Grâce aux API, l’automatisation de scripts est facilitée puisqu’il n’est plus nécessaire de stocker un fichier, et gérer ses versions, mais uniquement de requêter une base et laisser au producteur de données le soin de gérer les mises à jour de la base.
![]()
Source d’inspiration
Cet atelier s’inspire fortement du chapitre consacré aux API dans le cours de Python pour la data science de l’ENSAE. Les principales différences avec celui-ci sont dans la partie relative aux API authentifiées : nous proposons ici l’utilisation d’une API de l’Insee plutôt que de l’INPI.
Pour installer toutes les dépendances nécessaires pour ce tutoriel, vous pouvez taper, en ligne de commande:
uv pip install -r pyproject.toml --system
Regarder le replay de la session live du 09 Avril 2025:
1 Introduction : Qu’est-ce qu’une API ?
Vous êtes certainement habitué à récupérer vos données depuis des fichiers type CSV ou par webscraping1. Le webscraping est un pis-aller pour accéder à de la donnée.
Heureusement, il existe d’autres manières d’accéder à des données : les API de données. En informatique, une API est un ensemble de protocoles permettant à deux logiciels de communiquer entre eux. Par exemple, on parle parfois d’API Pandas ce qui désigne le fait que Pandas est une interface entre votre code Python et un langage compilé plus efficace (C) qui fait les calculs que vous demandez au niveau de Python. L’objectif d’une API est ainsi de fournir un point d’accès à une fonctionnalité qui soit facile à utiliser et qui masque les détails de la mise en oeuvre.
Dans cet atelier, nous nous intéressons principalement aux API de données. Ces dernières sont simplement une façon de mettre à disposition des données : plutôt que de laisser l’utilisateur consulter directement des bases de données (souvent volumineuses et complexes), l’API lui propose de formuler une requête qui est traitée par le serveur hébergeant la base de données, puis de recevoir des données en réponse à sa requête.
L’utilisation accrue d’API dans le cadre de stratégies open-data est l’un des piliers des 15 feuilles de route ministérielles françaises en matière d’ouverture, de circulation et de valorisation des données publiques.
Illustration avec l’API BAN
Imaginons ce qui se passe lorsqu’on requête l’API BAN (Base d’Adresses Nationale), en prenant la métaphore d’un restaurant :
💬 Via
Python, on passe une commande à l’API: des adresses plus ou moins complètes avec des instructions annexes comme le code commune. Ces instructions annexes peuvent s’apparenter à des informations fournies au serveur du restaurant comme des interdits alimentaires qui vont personnaliser la recette.🧑🍳 A partir de ces instructions, la confection du plat est lancée. En l’occurrence, il s’agit de faire tourner sur les serveurs d’Etalab une routine qui va chercher dans un référentiel d’adresses celle qui est la plus similaire à celle qu’on a demandée en adaptant éventuellement en fonction des instructions annexes qu’on a fournies.
🍕 Une fois que la cuisine a fini la préparation du plat, on le renvoie au client. En l’occurrence, le plat sera constitué des coordonnées géographiques qui correspondent à l’adresse la plus similaire.
Le client n’a donc qu’à se préoccuper de faire une bonne requête et d’apprécier le plat qui lui est fourni. L’intelligence dans la mise en oeuvre est laissée aux spécialistes qui ont conçu l’API. Peut-être que d’autres spécialistes, par exemple Google Maps, mettent en oeuvre une recette différente pour ce même plat (des coordonnées géographiques) mais ils vous proposeront probablement un résultat très similaire. Ce mode de fonctionnement vous simplifie beaucoup la vie : pour changer de restaurant, il vous suffit généralement de changer quelques lignes de code d’appel à une API plutôt que de modifier un ensemble long et complexe de méthodes d’identification d’adresses.
2 Découverte des concepts principaux avec l’API BAN
Une API a donc vocation à servir d’intermédiaire entre un client et un serveur. Ce client peut être de deux types : une interface web ou un logiciel de programmation. L’API ne fait pas d’a priori sur l’outil qui sert lui passe une commande, elle lui demande seulement de respecter un standard (en général une requête http), une structure de requête (les arguments) et d’attendre le résultat.
2.1 Comprendre le principe avec un exemple interactif
Le premier mode (accès par un navigateur) est principalement utilisé lorsqu’une interface web permet à un utilisateur de faire des choix afin de lui renvoyer des résultats correspondant à ceux-ci. Prenons à nouveau l’exemple de l’API de géolocalisation que nous utiliserons dans ce chapitre. Imaginons une interface web permettant à l’utilisateur deux choix : un code postal et une adresse. Cela sera injecté dans la requête et le serveur répondra avec la géolocalisation adaptée.
🔎 Allons voir ce que cela donne dans l’onglet Réseau des outils de développement de notre navigateur (dans firefox, raccourci CTRL+MAJ+K).
Ce qui nous donne un output au format JSON, le format de sortie d’API le plus commun.
Si on veut un beau rendu, comme la carte ci-dessus, il faudra que le navigateur retravaille cet output, ce qui se fait normalement avec Javascript, le langage de programmation embarqué par les navigateurs.
2.3 Comment connaître les inputs et outputs des API ?
Ici on a pris l’API BAN comme un outil magique dont on connaissait les principaux inputs (le endpoint, les paramètres et leur formattage…). Mais comment faire, en pratique, pour en arriver là ? Tout simplement en lisant la documentation lorsqu’elle existe et en testant celle-ci via des exemples.
Les bonnes API proposent un outil interactif qui s’appelle le swagger. C’est un site web interactif où sont décrites les principales fonctionnalités de l’API et où l’utilisateur peut tester des exemples interactivement. Ces documentations sont souvent créées automatiquement lors de la construction d’une API et mises à disposition par le biais d’un point d’entrée /docs. Elles permettent souvent d’éditer certains paramètres dans le navigateur, voir le JSON obtenu (ou l’erreur générée) et récupérer la requête formattée qui permet d’obtenir celui-ci. Ces consoles interactives dans le navigateur permettent de répliquer le tâtonnement qu’on peut faire par ailleurs dans des outils spécialisés comme postman.
Concernant l’API BAN, la documentation se trouve sur https://adresse.data.gouv.fr/api-doc/adresse. Elle n’est pas interactive, malheureusement. Mais elle présente de nombreux exemples qui peuvent être testés directement depuis le navigateur. Il suffit d’utiliser les URL proposées comme exemple. Ceux-ci sont présentés par le biais de curl (un équivalent de requests en ligne de commande Linux ):
curl "https://api-adresse.data.gouv.fr/search/?q=8+bd+du+port&limit=15"Il suffit de copier l’URL en question (https://api-adresse.data.gouv.fr/search/?q=8+bd+du+port&limit=15), d’ouvrir un nouvel onglet et vérifier que cela produit bien un résultat. Puis de changer un paramètre et vérifier à nouveau, jusqu’à trouver la structure qui convient. Et après, on peut passer à Python comme le propose l’exercice suivant.
2.4 Application
Pour la prochaine application, nous allons utiliser l’adresse suivante :
adresse = "88 Avenue Verdier"
Exercice 1 : Structurer un appel à une API depuis
Python
- Tester sans aucun autre paramètre, le retour de notre API. Transformer en
DataFramele résultat. - Se restreindre à Montrouge avec le paramètre ad hoc et la recherche du code insee ou code postal adéquat sur Google.
- (Optionnel) : Représenter l’adresse trouvée sur une carte.
Correction question 1
import requests
import pandas as pd
ban_root = "https://api-adresse.data.gouv.fr"
ban_search_endpoint = "search"
api_ban_q1 = f"{ban_root}/{ban_search_endpoint}?q={adresse.replace(" ", "+")}"
output_api_ban = requests.get(api_ban_q1).json().get('features')
df_avenue_verdier = pd.DataFrame(
[out['properties'] for out in output_api_ban]
)Les deux premières lignes du dataframe obtenu à la question 1 devraient être
df_avenue_verdier.head(2)| label | score | housenumber | id | banId | name | postcode | citycode | x | y | city | context | type | importance | street | _type | locality | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 88 Avenue Verdier 92120 Montrouge | 0.973564 | 88 | 92049_9625_00088 | 92dd3c4a-6703-423d-bf09-fc0412fb4f89 | 88 Avenue Verdier | 92120 | 92049 | 649270.67 | 6857572.24 | Montrouge | 92, Hauts-de-Seine, Île-de-France | housenumber | 0.7092 | Avenue Verdier | address | NaN |
| 1 | Avenue Verdier 44500 La Baule-Escoublac | 0.719373 | NaN | 44055_3690 | NaN | Avenue Verdier | 44500 | 44055 | 291884.83 | 6701220.48 | La Baule-Escoublac | 44, Loire-Atlantique, Pays de la Loire | street | 0.6006 | Avenue Verdier | address | NaN |
A la question 2, la requête ne renvoie cette fois qu’une seule observation, qu’on pourrait retravailler avec GeoPandas pour vérifier qu’on a bien placé ce point sur une carte
Correction question 2
import pandas as pd
import geopandas as gpd
api_ban_q2 = f"{ban_root}/{ban_search_endpoint}?q={adresse.replace(" ", "+")}&postcode=92120"
output_q2 = requests.get(api_ban_q2).json()
output_q2 = pd.DataFrame(
[output_q2.get("features")[0]['properties']]
)
output_q2 = gpd.GeoDataFrame(
output_q2,
geometry=gpd.points_from_xy(output_q2.x, output_q2.y), crs="EPSG:2154"
).to_crs(4326)
output_q2| label | score | housenumber | id | banId | name | postcode | citycode | x | y | city | context | type | importance | street | _type | geometry | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 88 Avenue Verdier 92120 Montrouge | 0.973564 | 88 | 92049_9625_00088 | 92dd3c4a-6703-423d-bf09-fc0412fb4f89 | 88 Avenue Verdier | 92120 | 92049 | 649270.67 | 6857572.24 | Montrouge | 92, Hauts-de-Seine, Île-de-France | housenumber | 0.7092 | Avenue Verdier | address | POINT (2.30914 48.81622) |
Enfin, à la question 3, on obtient cette carte (plus ou moins la même que précédemment) :
Correction question 3
import folium
# Extraire la longitude et la latitude
longitude = output_q2.geometry.x.iloc[0]
latitude = output_q2.geometry.y.iloc[0]
# Créer une carte Folium centrée sur le point
m = folium.Map(location=[latitude, longitude], zoom_start=16)
# Définir le contenu de la popup
popup_content = f"""
<b>{output_q2['name'].iloc[0]}</b> has been found!
"""
# Ajouter le marqueur
folium.Marker(
location=[latitude, longitude],
popup=folium.Popup(popup_content, max_width=300),
icon=folium.Icon(color='blue', icon='info-sign')
).add_to(m)
# Afficher la carte dans le notebook (si utilisé dans un Jupyter Notebook)
mMake this Notebook Trusted to load map: File -> Trust Notebook
Quelques exemples d’API à connaître
Les principaux fournisseurs de données officielles proposent des API. C’est le cas notamment de l’Insee, d’Eurostat, de la BCE, de la FED, de la Banque Mondiale…
Néanmoins, la production de données par les institutions publiques est loin d’être restreinte aux producteurs de statistiques publiques. Le portail API gouv est le point de référencement principal pour les API produites par l’administration centrale française ou des administrations territoriales. De nombreuses villes publient également des données sur leurs infrastructures par le biais d’API, par exemple la ville de Paris.
Les producteurs de données privées proposent également des API. Par exemple, la SNCF ou la RATP proposent des API pour certains usages. Les grands acteurs du numérique, par exemple Spotify proposent généralement des API pour intégrer certains de leurs services à des applications externes.
Cependant, il faut être conscient des limites de certaines API. En premier lieu, les données partagées ne sont pas forcément très riches pour ne pas compromettre la confidentialité des informations partagées par les utilisateurs du service ou la part de marché du producteur qui n’a pas intérêt à vous partager ses données à forte valeur. Il faut également être conscient du fait qu’une API peut disparaître ou changer de structure du jour au lendemain. Les codes de restructuration de données étant assez adhérents à une structure d’API, on peut se retrouver à devoir changer un volume conséquent de code si une API critique change substantiellement.
3 Plus d’exemples de requêtes GET
3.1 Source principale
Nous allons utiliser comme base principale pour ce tutoriel la base permanente des équipements, un répertoire d’équipements publics accueillant du public.
On va commencer par récupérer les données qui nous intéressent. On ne récupère pas toutes les variables du fichier mais seulement celles qu’ils nous intéressent : quelques variables sur l’équipement, son adresse et sa commune d’appartenance.
Nous allons nous restreindre aux établissements d’enseignement primaire, secondaire et supérieur du département de la Haute-Garonne (le département 31). Ces établissements sont identifiés par un code particulier, entre C1 et C5.
import duckdb
query = """
FROM read_parquet('https://minio.lab.sspcloud.fr/lgaliana/diffusion/BPE23.parquet')
SELECT NOMRS, NUMVOIE, INDREP, TYPVOIE, LIBVOIE,
CADR, CODPOS, DEPCOM, DEP, TYPEQU,
concat_ws(' ', NUMVOIE, INDREP, TYPVOIE, LIBVOIE) AS adresse, SIRET
WHERE DEP = '31'
AND starts_with(TYPEQU, 'C')
AND NOT (starts_with(TYPEQU, 'C6') OR starts_with(TYPEQU, 'C7'))
"""
bpe = duckdb.sql(query)
bpe = bpe.to_df()
bpe.head(2)| NOMRS | NUMVOIE | INDREP | TYPVOIE | LIBVOIE | CADR | CODPOS | DEPCOM | DEP | TYPEQU | adresse | SIRET | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | ECOLE PRIMAIRE PUBLIQUE DENIS LATAPIE | LD | LA BOURDETTE | 31230 | 31001 | 31 | C108 | LD LA BOURDETTE | 21310001900024 | |||
| 1 | ECOLE MATERNELLE PUBLIQUE | 21 | CHE | DE L AUTAN | 31280 | 31003 | 31 | C107 | 21 CHE DE L AUTAN | 21310003500038 |
3.2 Récupérer des données à façon grâce aux API
Nous avons vu précédemment le principe général d’une requête d’API. Pour illustrer, de manière plus massive, la récupération de données par le biais d’une API, essayons de récupérer des données complémentaires à notre source principale. Nous allons utiliser l’annuaire de l’éducation qui fournit de nombreuses informations sur les établissements scolaires. Nous utiliserons le SIRET pour croiser les deux sources de données.
L’exercice suivant viendra illustrer l’intérêt d’utiliser une API pour avoir des données à façon et la simplicité à récupérer celles-ci via Python. Néanmoins, cet exercice illustrera également une des limites de certaines API, à savoir la volumétrie des données à récupérer.
Exercice 2
- Visiter le swagger de l’API de l’Annuaire de l’Education nationale sur api.gouv.fr/documentation, et plus particulièrement sa “documentation externe” qui permet de générer les urls souhaitées en prototypant interactivement les requêtes. Tester une première récupération de données en utilisant le endpoint
recordssans aucun paramètre. - Puisqu’on n’a conservé que les données de la Haute Garonne dans notre base principale, on désire ne récupérer que les établissements de ce département par le biais de notre API. Faire une requête avec le paramètre ad hoc, sans en ajouter d’autres.
- Augmenter la limite du nombre de paramètres, voyez-vous le problème ?
- On va tenter de récupérer ces données par le biais de l’API tabular de
data.gouv. Sa documentation est ici et l’identifiant de la ressource estb22f04bf-64a8-495d-b8bb-d84dbc4c7983(source). Avec l’aide de la documentation, essayer de récupérer des données par le biais de cette API en utilisant le paramètreCode_departement__exact=031pour ne garder que le département d’intérêt. - Voyez-vous le problème et comment nous pourrions automatiser la récupération de données ?
Réponse question 1
import requests
url_annuaire_education = "https://data.education.gouv.fr/api/explore/v2.1/catalog/datasets/fr-en-annuaire-education/records"
school_q1_exo2 = pd.DataFrame(
requests
.get(url_annuaire_education)
.json()
.get("results")
)
school_q1_exo2.head(2)| identifiant_de_l_etablissement | nom_etablissement | type_etablissement | statut_public_prive | adresse_1 | adresse_2 | adresse_3 | code_postal | code_commune | nom_commune | ... | libelle_nature | code_type_contrat_prive | pial | etablissement_mere | type_rattachement_etablissement_mere | code_circonscription | code_zone_animation_pedagogique | libelle_zone_animation_pedagogique | code_bassin_formation | libelle_bassin_formation | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0331364D | Ecole primaire | Ecole | Public | 47 Route des maurins | 47 Route des maurins | 33240 VERAC | 33240 | 33542 | Vérac | ... | ECOLE DE NIVEAU ELEMENTAIRE | 99 | 0332706M | None | None | 0332529V | 033100 | ZAP 033100 AMBITION NORD GIRONDE | 04204 | LIBOURNE |
| 1 | 0400656W | Ecole maternelle | Ecole | Public | 280 boulevard des Sports | None | 40350 POUILLON | 40350 | 40233 | Pouillon | ... | ECOLE MATERNELLE | 99 | 0400032T | None | None | 0401054D | 040020 | ZAP 040020 DAX | 04301 | LANDES OCEANES |
2 rows × 72 columns
Néanmoins, on a deux problèmes : le nombre de lignes et le département d’intérêt. Essayons déjà avec la question 2 de changer ce dernier.
Réponse question 2
url_31_limite10 = "https://data.education.gouv.fr/api/explore/v2.1/catalog/datasets/fr-en-annuaire-education/records?where=code_departement%20like%20%22031%22"
school_q2_exo2 = pd.DataFrame(
requests
.get(url_31_limite10)
.json()
.get("results")
)
school_q2_exo2.head()| identifiant_de_l_etablissement | nom_etablissement | type_etablissement | statut_public_prive | adresse_1 | adresse_2 | adresse_3 | code_postal | code_commune | nom_commune | ... | libelle_nature | code_type_contrat_prive | pial | etablissement_mere | type_rattachement_etablissement_mere | code_circonscription | code_zone_animation_pedagogique | libelle_zone_animation_pedagogique | code_bassin_formation | libelle_bassin_formation | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0310169R | Ecole maternelle publique des capucins | Ecole | Public | Impasse des Capucins | None | 31220 CAZERES | 31220 | 31135 | Cazères | ... | ECOLE MATERNELLE | 99 | 0310012V | None | None | 0311109M | None | None | 16106 | COMMINGES |
| 1 | 0310173V | Ecole primaire publique la Bastide | Ecole | Public | Rue de l'Egalité | None | 31330 GRENADE | 31330 | 31232 | Grenade | ... | ECOLE DE NIVEAU ELEMENTAIRE | 99 | 0310008R | None | None | 0312789N | None | None | 16127 | TOULOUSE NORD-OUEST |
| 2 | 0310180C | Ecole maternelle publique Jacques Prévert | Ecole | Public | 11 rue Désiré | None | 31120 PORTET SUR GARONNE | 31120 | 31433 | Portet-sur-Garonne | ... | ECOLE MATERNELLE | 99 | 0311093V | None | None | 0311105H | None | None | 16108 | TOULOUSE SUD-OUEST |
| 3 | 0310183F | Ecole maternelle publique le pilat | Ecole | Public | 1 rue du Dr Ferrand | None | 31800 ST GAUDENS | 31800 | 31483 | Saint-Gaudens | ... | ECOLE MATERNELLE | 99 | 0310083X | None | None | 0311108L | None | None | 16106 | COMMINGES |
| 4 | 0310189M | Ecole maternelle publique Jean Macé | Ecole | Public | 9 chemin de Duroux | None | 31500 TOULOUSE | 31500 | 31555 | Toulouse | ... | ECOLE MATERNELLE | 99 | 0310085Z | None | None | 0312825C | None | None | 16109 | TOULOUSE CENTRE |
5 rows × 72 columns
C’est mieux, mais nous avons toujours seulement 10 observations. Si on essaie d’ajuster le nombre de lignes (question 3), on obtient le retour suivant de l’API :
Question 3
url_31_limite200 = "https://data.education.gouv.fr/api/explore/v2.1/catalog/datasets/fr-en-annuaire-education/records?where=code_departement%20like%20%22031%22&limit=200"
requests.get(url_31_limite200).json(){'error_code': 'InvalidRESTParameterError',
'message': 'Invalid value for limit API parameter: 200 was found but -1 <= limit <= 100 is expected.'}Essayons avec des données plus exhaustives : le fichier brut sur data.gouv. Comme on peut le voir dans les métadonnées, on sait qu’on a plus de 1000 écoles dont on peut récupérer des données, mais qu’on en a ici extrait seulement 20. Le champ next nous donne directement l’URL à utiliser pour récupérer les 20 pages suivantes : c’est grâce à lui qu’on a une chance de récupérer toutes nos données d’intérêt.
Réponse question 4
url_api_datagouv = "https://tabular-api.data.gouv.fr/api/resources/b22f04bf-64a8-495d-b8bb-d84dbc4c7983/data/?Code_departement__exact=031"
call_api_datagouv = requests.get(url_api_datagouv).json()Le problème de la récupération de données via l’API vient du fait que nous ne récupérons qu’un petit échantillon à chaque requête. Pour y remédier, nous allons devoir faire plusieurs appels successifs. Dans le JSON obtenu ci-dessus, la partie intéressante pour automatiser la récupération de nos données est la clé links. En bouclant sur celui-ci pour parcourir la liste des URL accessibles, on peut récupérer des données.
Réponse question 5
import requests
import pandas as pd
# Initialize the initial API URL
url_api_datagouv = "https://tabular-api.data.gouv.fr/api/resources/b22f04bf-64a8-495d-b8bb-d84dbc4c7983/data/?Code_departement__exact=031&page_size=50"
# Initialize an empty list to store all data entries
all_data = []
# Initialize the URL for pagination
current_url = url_api_datagouv
# Loop until there is no next page
while current_url:
try:
# Make a GET request to the current URL
response = requests.get(current_url)
response.raise_for_status() # Raise an exception for HTTP errors
# Parse the JSON response
json_response = response.json()
# Extract data and append to the all_data list
page_data = json_response.get('data', [])
all_data.extend(page_data)
print(f"Fetched {len(page_data)} records from {current_url}")
# Get the next page URL
links = json_response.get('links', {})
current_url = links.get('next') # This will be None if there's no next page
except requests.exceptions.RequestException as e:
print(f"An error occurred: {e}")
breakschools_dep31 = pd.DataFrame(all_data)
schools_dep31.head()| __id | Identifiant_de_l_etablissement | Nom_etablissement | Type_etablissement | Statut_public_prive | Adresse_1 | Adresse_2 | Adresse_3 | Code_postal | Code_commune | ... | libelle_nature | Code_type_contrat_prive | PIAL | etablissement_mere | type_rattachement_etablissement_mere | code_circonscription | code_zone_animation_pedagogique | libelle_zone_animation_pedagogique | code_bassin_formation | libelle_bassin_formation | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 48 | 0312140H | Collège René Cassin | Collège | Public | Avenue des Carabenes | None | None | 31650 | 31506 | ... | COLLEGE | 99 | 0311850T | None | None | None | None | None | 16128 | TOULOUSE EST |
| 1 | 49 | 0311266H | Collège Jean Jaurès | Collège | Public | Place Clémence Isaure | BP 22508 | None | 31325 | 31113 | ... | COLLEGE | 99 | 0311633G | None | None | None | None | None | 16128 | TOULOUSE EST |
| 2 | 55 | 0312071H | Collège Jules Verne | Collège | Public | 1 avenue Marcel Pagnol | None | None | 31830 | 31424 | ... | COLLEGE | 99 | 0312071H | None | None | None | None | None | 16108 | TOULOUSE SUD-OUEST |
| 3 | 61 | 0311632F | Collège Les Violettes de Aucamville | Collège | Public | 3 avenue des Pins | None | None | 31140 | 31022 | ... | COLLEGE | 99 | 0312139G | None | None | None | None | None | 16110 | TOULOUSE NORD |
| 4 | 62 | 0311332E | Collège Anatole France | Collège | Public | 4 avenue de Lespinet | None | None | 31400 | 31555 | ... | COLLEGE | 99 | 0310085Z | None | None | None | None | None | 16109 | TOULOUSE CENTRE |
5 rows × 73 columns
On peut fusionner ces nouvelles données avec nos données précédentes pour enrichir celles-ci. Pour faire une production fiable, il faudrait faire attention aux écoles qui ne s’apparient pas, mais ce n’est pas grave pour cette série d’exercices.
bpe_enriched = bpe.merge(
schools_dep31,
left_on = "SIRET",
right_on = "SIREN_SIRET"
)
bpe_enriched.head(2)| NOMRS | NUMVOIE | INDREP | TYPVOIE | LIBVOIE | CADR | CODPOS | DEPCOM | DEP | TYPEQU | ... | libelle_nature | Code_type_contrat_prive | PIAL | etablissement_mere | type_rattachement_etablissement_mere | code_circonscription | code_zone_animation_pedagogique | libelle_zone_animation_pedagogique | code_bassin_formation | libelle_bassin_formation | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | ECOLE PRIMAIRE PUBLIQUE DENIS LATAPIE | LD | LA BOURDETTE | 31230 | 31001 | 31 | C108 | ... | ECOLE DE NIVEAU ELEMENTAIRE | 99 | 0310003K | None | None | 0311108L | None | None | 16106 | COMMINGES | |||
| 1 | ECOLE MATERNELLE PUBLIQUE | 21 | CHE | DE L AUTAN | 31280 | 31003 | 31 | C107 | ... | ECOLE MATERNELLE | 99 | 0311335H | None | None | 0311102E | None | None | 16128 | TOULOUSE EST |
2 rows × 85 columns
Cela nous donne des données enrichies de nouvelles caractéristiques sur les établissements. Il y a des coordonnées géographiques dans celles-ci, mais nous allons faire comme s’il n’y en avait pas pour réutiliser notre API de géolocalisation et ainsi avoir un alibi pour utiliser les requêtes POST.
4 Découverte des requêtes POST
4.1 Logique
Nous avons jusqu’à présent évoqué les requêtes GET. Nous allons maintenant présenter les requêtes POST qui permettent d’interagir de manière plus complexe avec des serveurs de l’API.
Pour découvrir celles-ci, nous allons reprendre l’API de géolocalisation précédente mais utiliser un autre point d’entrée qui nécessite une requête POST.
Ces dernières sont généralement utilisées quand il est nécessaire d’envoyer des données particulières pour déclencher une action. Par exemple, dans le monde du web, si vous avez une authentification à mettre en oeuvre, une requête POST permettra d’envoyer un token au serveur qui répondra en acceptant votre authentification.
Dans notre cas, nous allons envoyer des données au serveur, ce dernier va les recevoir, les utiliser pour la géolocalisation puis nous envoyer une réponse. Pour continuer sur la métaphore culinaire, c’est comme si vous donniez vous-mêmes à la cuisine un tupperware pour récupérer votre plat à emporter.
4.2 Principe
Prenons cette requête proposée sur le site de documentation de l’API de géolocalisation :
curl -X POST -F data=@path/to/file.csv -F columns=voie -F columns=ville -F citycode=ma_colonne_code_insee https://api-adresse.data.gouv.fr/search/csv/Ici l’objectif est d’obtenir des géolocalisations pour les adresses textuelles présentes dans un fichier .csv.
Comme nous avons pu l’évoquer précédemment, curl est un outil en ligne de commande qui permet de faire des requêtes API. L’option -X POST indique, de manière assez transparente, qu’on désire faire une requête POST.
Les autres arguments sont passés par le biais des options -F. En l’occurrence, on envoie un fichier et on ajoute des paramètres pour aider le serveur à aller chercher la donnée dedans. L’@ indique que file.csv doit être lu sur le disque et envoyé dans le corps de la requête comme une donnée de formulaire.
4.3 Application avec Python
Nous avions requests.get, il est donc logique que nous ayons requests.post. Cette fois, il faudra passer des paramètres à notre requête sous la forme d’un dictionnaire dont les clés sont le nom de l’argument et les valeurs sont des objets Python.
Le principal défi, illustré dans le prochain exercice, est le passage de l’argument data : il faudra renvoyer le fichier comme un objet Python par le biais de la fonction open.
Exercice 3 : une requête
POST pour géolocaliser en masse nos données
- Enregistrer au format CSV les colonnes
adresse,DEPCOMetNom_communede la base d’équipements fusionnée avec notre répertoire précédent (objetbpe_enriched). Il peut être utile, avant l’écriture au format CSV, de remplacer les virgules dans la colonneadressepar des espaces. - Créer l’objet
responseavecrequests.postet les bons arguments pour géocoder votre CSV. - Transformer votre output en objet
Pandasavec la commande suivante :
bpe_loc = pd.read_csv(io.StringIO(response.text))Réponse question 1
import pathlib
output_path = pathlib.Path("data/output")
output_path.mkdir(parents=True, exist_ok=True)
csv_file = output_path / "bpe_before_geoloc.csv"
bpe_enriched["adresse"] = bpe_enriched["adresse"].str.replace(",", "")
bpe_enriched.loc[:, ["adresse", "DEPCOM", "Nom_commune"]].to_csv(csv_file)Réponse question 2 et 3
import io
params = {
"columns": ["adresse", "Nom_commune"],
"citycode": "DEPCOM",
"result_columns": ["result_score", "latitude", "longitude"],
}
response = requests.post(
"https://api-adresse.data.gouv.fr/search/csv/",
data=params,
files={"data": open(csv_file, "rb")},
)
bpe_loc = pd.read_csv(io.StringIO(response.text))
bpe_loc = bpe_loc.rename({"Unnamed: 0": "index"}, axis = "columns")Les géolocalisations obtenues prennent cette forme
bpe_loc.head(2)| index | adresse | DEPCOM | Nom_commune | result_score | latitude | longitude | |
|---|---|---|---|---|---|---|---|
| 0 | 0 | LD LA BOURDETTE | 31001 | Agassac | 0.404609 | 43.374288 | 0.880679 |
| 1 | 1 | 21 CHE DE L AUTAN | 31003 | Aigrefeuille | 0.730293 | 43.567530 | 1.585745 |
On peut ensuite faire la jointure à nos données initiales :
Jointure aux données initiales
bpe_loc = bpe_loc.loc[:, ["index", "result_score", "latitude", "longitude"]]
bpe_enriched_geocoded = (
bpe_enriched
.reset_index()
.merge(bpe_loc, on = "index", suffixes = ["_annuaire", "_ban"])
.drop("index", axis = "columns")
)
bpe_enriched_geocoded.head(2)| NOMRS | NUMVOIE | INDREP | TYPVOIE | LIBVOIE | CADR | CODPOS | DEPCOM | DEP | TYPEQU | ... | etablissement_mere | type_rattachement_etablissement_mere | code_circonscription | code_zone_animation_pedagogique | libelle_zone_animation_pedagogique | code_bassin_formation | libelle_bassin_formation | result_score | latitude_ban | longitude_ban | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | ECOLE PRIMAIRE PUBLIQUE DENIS LATAPIE | LD | LA BOURDETTE | 31230 | 31001 | 31 | C108 | ... | None | None | 0311108L | None | None | 16106 | COMMINGES | 0.404609 | 43.374288 | 0.880679 | |||
| 1 | ECOLE MATERNELLE PUBLIQUE | 21 | CHE | DE L AUTAN | 31280 | 31003 | 31 | C107 | ... | None | None | 0311102E | None | None | 16128 | TOULOUSE EST | 0.730293 | 43.567530 | 1.585745 |
2 rows × 88 columns
Jointure aux données initiales
bpe_enriched_geocoded = (
bpe_enriched_geocoded
.dropna(subset=["longitude_ban","latitude_ban"])
)
bpe_enriched_geocoded = gpd.GeoDataFrame(
bpe_enriched_geocoded,
geometry=gpd.points_from_xy(
bpe_enriched_geocoded['longitude_ban'],
bpe_enriched_geocoded['latitude_ban']
),
crs="EPSG:4326"
)Pour profiter de nos données enrichies, on peut faire une carte. Pour ajouter un peu de contexte à celle-ci, on peut mettre un fond de carte des communes en arrière plan. Celui-ci peut être récupéré avec cartiflette :
Récupération du fond de carte (GEOJSON)
from cartiflette import carti_download
shp_communes = carti_download(
crs = 4326,
values = ["31"],
borders="COMMUNE",
vectorfile_format="topojson",
filter_by="DEPARTEMENT",
source="EXPRESS-COG-CARTO-TERRITOIRE",
year=2022
)
shp_communes.crs = 4326Code pour la carte interactive
import folium
from folium.plugins import MarkerCluster
import geopandas as gpd
department_border = shp_communes.dissolve(by="INSEE_DEP")
city_borders = shp_communes.copy()
longitude = bpe_enriched_geocoded.geometry.x.iloc[0]
latitude = bpe_enriched_geocoded.geometry.y.iloc[0]
m = folium.Map(location=[latitude, longitude], zoom_start=10)
# Add department border (black, bold)
folium.GeoJson(
data=department_border,
style_function=lambda x: {
"fill": False,
"color": "black",
"weight": 3 # Bold border
}
).add_to(m)
# Add city borders (blue, thin)
folium.GeoJson(
data=city_borders,
style_function=lambda x: {
"fill": False,
"color": "blue",
"weight": 1 # Thin border
}
).add_to(m)
# Initialize the MarkerCluster
marker_cluster = MarkerCluster().add_to(m)
def generate_popup(row):
# Initialiser le contenu avec le nom de l'école
popup_content = f"<b>Nom:</b> {row['NOMRS']}<br>"
# Ajouter "Ecole élémentaire" avec une icône ✅️ ou ❌️ selon la valeur
ecole_element_status = "✅️" if row.get('Ecole_elementaire', False) else "❌️"
popup_content += f"<b>Ecole élémentaire:</b> {ecole_element_status}<br>"
# Ajouter "Nombre d'élèves" si disponible
if not pd.isnull(row.get('Nombre_d_eleves')):
popup_content += f"<b>Nombre d'élèves :</b> {row['Nombre_d_eleves']}<br>"
# Ajouter "Voie générale" si disponible
if not pd.isnull(row.get('Voie_generale')):
popup_content += f"<b>Voie générale :</b> {row['Voie_generale']}<br>"
# Ajouter "Voie technologique" si disponible
if not pd.isnull(row.get('Voie_technologique')):
popup_content += f"<b>Voie technologique :</b> {row['Voie_technologique']}<br>"
return popup_content
# Add GeoDataFrame points to the MarkerCluster
for _, row in bpe_enriched_geocoded.iterrows():
# Create the popup content
popup_content = generate_popup(row)
popup = folium.Popup(popup_content, max_width=300)
# Add the marker to the cluster
folium.Marker(
location=[row.geometry.y, row.geometry.x], # Extract latitude and longitude
popup=popup,
icon=folium.Icon(color="blue", icon="info-sign")
).add_to(marker_cluster)
# Display the map inline (optional for Jupyter Notebooks)
mMake this Notebook Trusted to load map: File -> Trust Notebook
5 Gestion des secrets et des exceptions
Nous avons déjà utilisé plusieurs API. Néanmoins ces dernières étaient toutes sans authentification et présentent peu de restrictions, hormis le nombre d’échos. Ce n’est pas le cas de toutes les API. Il est fréquent que les API qui permettent d’aspirer plus de données ou d’accéder à des données confidentielles nécessitent une authentification pour tracer les utilisateurs de données.
Cela se fait généralement en utilisant un token. Ce dernier est une sorte de mot de passe, souvent utilisé dans les systèmes modernes d’authentification pour certifier de l’identité d’un.e utilisateur.trice (cf. chapitre Git).
Avant d’en présenter l’usage, nous allons faire un rapide aparté sur la confidentialité des tokens et la manière d’éviter de révéler ceux-ci dans votre code.
5.1 Bonnes pratiques pour utiliser un token dans un code sans le révéler 👮
Les tokens sont des informations personnelles qui ne doivent pas être partagées. Ils n’ont donc pas vocation à apparaître dans le code.
Comme ceci est évoqué à plusieurs reprises dans le cours de mise en production en 3e année de l’ENSAE, il est important de séparer le code des éléments de configuration :
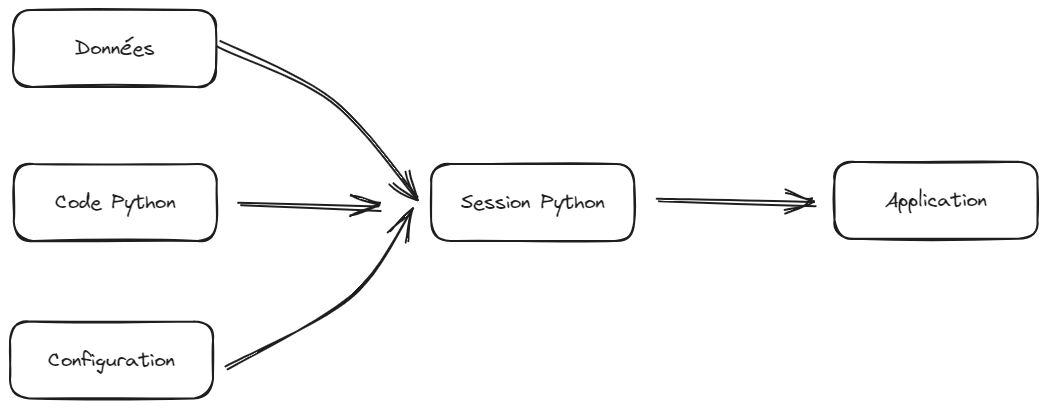
L’idée est de trouver une recette pour apporter les éléments de configuration avec le code mais sans mettre ceux-ci en clair dans le code. L’idée générale sera de stocker la valeur du token dans une variable mais ne jamais révéler celle-ci dans le code. Comment faire dès lors pour déclarer la valeur du jeton sans que celui-ci soit apparent dans le code ?
- Pour un code amené à fonctionner de manière interactive (par exemple par le biais d’un notebook), il est possible de créer une boite de dialogue qui injectera la valeur renseignée dans une variable. Cela se fait par le biais du package
getpass. - Pour le code qui tourne en non interactif, par exemple par le biais de la ligne de commande, l’approche par variable d’environnement est la plus fiable, à condition de faire attention à ne pas mettre le fichier de mot de passe dans
Git. Pour cela, le plus simple est d’utiliserdotenvsi vous faites tourner votre code ou des secrets si votre code tourne par le biais de l’intégration continue2.
Important
Il ne faut jamais mettre de token dans Git. Sinon, vous courrez le risque d’avoir votre identité usurpée : des robots scannent en continu Github à la recherche de jetons pour ensuite lancer des dénis de service en se faisant passer pour vous.
Si vous avez partagé par erreur un jeton : pas de panique, cela peut arriver ! L’avantage des jetons est qu’ils sont révocables : vous pouvez l’invalider et en créer un nouveau pour continuer à utiliser le service désiré. La bonne réaction consiste à révoquer le jeton le plus vite possible, une fois la fuite constatée. La meilleure parade pour éviter ce type de fuite est d’ajouter tout de suite le .env au .gitignore.
L’exercice 5 permettra de mettre en oeuvre ces deux méthodes. Ces méthodes nous serviront à ajouter de manière confidentielle un payload à des requêtes d’authentification, c’est-à-dire des informations confidentielles identifiantes en complément d’une requête.
5.2 Le portail des API de l’Insee
Pour illustrer l’utilisation des API authentifiées, nous proposons d’explorer le portail des API de l’Insee.
Nous allons nous concentrer sur l’API Sirene mais, sur ce portail, il en existe d’autres, notamment l’API Melodi consacrée à la récupération d’un certain nombre de sources open data de l’Insee. L’API Sirene est une version interrogeable des données Sirene open data.
Exercice 4 : API authentifiée par le biais du navigateur
- Se créer un compte sur le portail des API
- Aller voir l’espace
Mes applicationset en créer une nouvelle. Par simplicité, vous pouvez la nommer “Atelier SSPHub”. - Dans celle-ci, aller dans l’onglet “Clefs et jetons”.Créer un jeton (vous pouvez laisser la durée de validité proposée).
- Cliquer sur l’onglet Souscriptions. Choisir l’API Sirene.
- A droite, sélectionner l’application créée précédemment. Si vous allez voir votre application, elle devrait maintenant pouvoir interagir avec l’API Sirene.
Testons maintenant l’API Sirene grâce au swagger (onglet Console de l'API) :
- Plus bas, dans la documentation interactive se rendre au point d’entrée
/siren/{siren}(méthodeGET). - Remplir le champ
qavec le SIREN500569405(SIREN de Décathlon 😉) - Si vous avez l’erreur ci-dessous, comprenez-vous pourquoi ?
- Changer l’application via le menu déroulant : maintenant que vous avez un token valide, soumettez à nouveau la même requête.
Vous devriez maintenant avoir cette sortie :
5.3 Récupération des données via Python
Pour la prochaine application, à partir de la question 4, nous allons avoir besoin de créer une classe spéciale permettant à requests de surcharger notre requête d’un jeton d’authentification. Comme elle n’est pas triviale à créer sans connaissance préalable, la voici :
class BearerAuth(requests.auth.AuthBase):
def __init__(self, token):
self.token = token
def __call__(self, r):
r.headers["authorization"] = "Bearer " + self.token
return r
Exercice 5 : les tokens avec
Python
- Créer une variable
tokenpar le biais degetpass. - Utiliser cette structure de code pour récupérer la donnée voulue
requests.get(
url,
auth=BearerAuth(token)
)- Remplacer l’utilisation de
getpasspar l’approche variable d’environnement grâce àdotenv.
Correction de l’exercice
import os
from dotenv import load_dotenv
load_dotenv()
siren="500569405"
token = os.getenv("TOKEN_API_INSEE")
if token is not None:
print("Token has been retrieved from env var")
r = requests.get(
f"https://api.insee.fr/entreprises/sirene/V3.11/siren/{siren}",
auth=BearerAuth(token)
)
sortie_sirene_decathlon = r.json()
sortie_sirene_decathlonNous avons un dataframe avec de nombreux SIRET (bpe). On pourrait vouloir récupérer des infos sur ceux-ci par le biais de l’API. Néanmoins les conditions d’usage de celle-ci sont restrictives : pas plus de 30 appels par minute.
On ne peut donc faire une boucle sur notre dataframe sans contrôler le nombre d’appels à la minute. Idéalement, nous ferions de l’envoi par bash qui permet d’envoyer plusieurs enregistrement à la fois dans une seule requête (comme nous avons fait pour les géolocalisations) mais ce n’est pas possible : l’API Sirene est une API pour de la consultation de données ponctuelles, pas du traitement statistique sur de gros volumes.
L’autre approche possible, que nous allons adopter, est de mettre un temps d’attente entre chaque appel à l’API. Nous allons donc faire une boucle mais, entre chaque itération, mettre un temps de repos de 2 secondes.
Fonction utile pour cet exercice
siret = "21310001900024"
def get_ape(siret: str = "21310001900024", token: str = ""):
info_siret = requests.get(
f"https://api.insee.fr/entreprises/sirene/V3.11/siret/{siret}",
auth=BearerAuth(token)
).json()
ape = (info_siret
.get("etablissement", {})
.get("uniteLegale", {})
.get("activitePrincipaleUniteLegale", {})
)
return ape
get_ape(siret, token)
Exercice 6 : généraliser des appels à des API
Nous voulons récupérer l’activité pricnipal de nos établissements (le code APE, qui devrait normalement être 84.11Z).
Utiliser le package time et sa fonction sleep pour marquer un temps d’arrêt lorsqu’on itére sur les dix premières observations de notre dataframe pour récupérer ce code.
Correction de l’exercice
import time
first_siret = []
for index, row in bpe.head(10).iterrows():
first_siret += [get_ape(row['SIRET'], token)]
time.sleep(2)6 Conclusion
Les API sont pratiques pour récupérer des données ponctuelles, en particulier lorsque le consommateur de données n’a pas besoin d’accéder à la donnée brute mais plutôt à une version déjà transformée, filtrée ou mise à jour dynamiquement. Elles s’intègrent bien dans des applications interactives ou des scripts automatisés et permettent de déléguer la gestion des mises à jour et de la volumétrie au fournisseur de données.
Cependant, leur utilisation présente plusieurs inconvénients :
elles nécessitent souvent un code très spécifique à chaque source et à chaque langage, ce qui nuit à la portabilité (à l’inverse de solutions plus universelles comme SQL, dont nous parlerons dans la masterclass
Parquet) ;elles posent parfois des limites en termes de volumétrie ou de stabilité d’accès (API désactivées ou restructurées sans préavis), ce qui les rend moins adaptées pour un usage massif ou reproductible à long terme.
Les API sont donc surtout intéressantes pour récupérer des données ponctuelles ou embarquées dans une application, mais restent à manier avec prudence dans un contexte d’exploitation de données à grande échelle ou de production statistique robuste.
Notes de bas de page
Technique consistant à singer le comportement d’un navigateur web et de récupérer de l’information en moissonnant le HTML auquel accède un site web↩︎
C’est par exemple l’approche adoptée pour construire ces supports. Cela se fait de cette manière.↩︎
2.2 Comment faire avec
Python?Le principe est le même sauf que nous perdons l’aspect interactif. Il s’agira donc, avec
Python, de construire l’URL voulue et d’aller chercher via une requête HTTP le résultat.Pythoncommunique avec internet : via le packagerequests. Ce package suit le protocole HTTP où on retrouve principalement deux types de requêtes :GETetPOST:GETest utilisée pour récupérer des données depuis un serveur web. C’est la méthode la plus simple et courante pour accéder aux ressources d’une page web. Nous allons commencer par décrire celle-ci.POSTest utilisée pour envoyer des données au serveur, souvent dans le but de créer ou de mettre à jour une ressource. Sur les pages web, elle sert souvent à la soumission de formulaires qui nécessitent de mettre à jour des informations sur une base (mot de passe, informations clients, etc.). Nous verrons son utilité plus tard, lorsque nous commencerons à rentrer dans les requêtes authentifiées où il faudra soumettre des informations supplémentaires à notre requête.Faisons un premier test avec
Pythonen faisant comme si nous connaissions bien cette API.Qu’est-ce qu’on obtient ? Un code HTTP. Le code 200 correspond aux requêtes réussies, c’est-à-dire pour lesquelles le serveur est en mesure de répondre. Si ce n’est pas le cas, pour une raison x ou y, vous aurez un code différent.
Les codes de statut HTTP sont des réponses standard envoyées par les serveurs web pour indiquer le résultat d’une requête effectuée par un client (comme un navigateur ou un script Python). Ils sont classés en différentes catégories selon le premier chiffre du code :
Ceux à retenir sont : 200 (succès), 400 (requête mal structurée), 401 (authentification non réussie), 403 (accès interdit), 404 (ressource demandée n’existe pas), 503 (le serveur n’est pas en capacité de répondre)
Pour récupérer le contenu renvoyé par
requests, il existe plusieurs méthodes. Quand on un JSON bien formatté, le plus simple est d’utiliser la méthodejsonqui transforme cela en dictionnaire :En l’occurrence, on voit que les données sont dans un JSON imbriqué. Il faut donc développer un peu de code pour récupérer les informations voulues dans celui-ci:
C’est là l’inconvénient principal de l’usage des API : le travail ex post sur les données renvoyées est parfois important. Le code nécessaire est propre à chaque API puisque l’architecture du JSON dépend de chaque API.