Parquet, c’est quoi ?
Parquet est un format de fichier orienté colonne développé en 2013 par Cloudera et Twitter en 2013, avant d’être offert à la fondation Apache en 2014 en tant que projet open-source.
Pour bien définir ce qu’est un format de fichier orienté colonne, rappelons d’abord ce qu’est un format de fichier orienté ligne. Dans les formats de fichiers orientés ligne, les données sont enregistrées ligne par ligne ce qui rend le format de fichier optimisé pour les systèmes transactionnels quand il y a besoin de lire ou enregistrer l’intégrité d’un enregistrement.
Pour les formats de fichiers orientés colonne, la donnée est enregistrée par colonne. cela rend le format de fichier très intéressant pour les analyses. Ainsi, pour filtrer l’information sur une colonne précise, il n’y a pas besoin de charger toute une ligne mais seulement la colonne qui nous intéresse selon la requête effectuée, ce qui nous permet d’améliorer les performances. De plus, le format de fichiers orienté colonne permet le vectorized processing: les opérations sont effectuées par lots de valeurs de colonne au lieu de ligne à ligne. Les moteurs d’exécution (DuckDB, Trino, Spark) peuvent ainsi exécuter le même calcul sur des dizaines de valeurs au cours d’un cycle plutôt qu’une ligne à la fois. Enfin, les formats de fichiers orientés colonne sont des formats compressés ce qui permet un gain d’espace.
Composition d’un fichier parquet
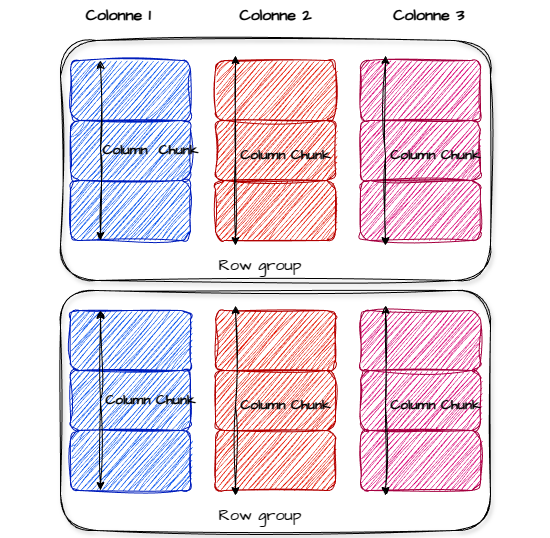
Quelques éléments composant un fichier parquet :
- row group : partition horizontale des données, chaque groupe contient toutes les colonnes d’un sous-ensemble de lignes. Il s’agit de la plus grande unité de travail.
- column chunk : colonne au sein d’un row group ce qui permet de réaliser une compression et encodage par colonne.
- page : plus petite unité de données au sein d’un column chunk.On y retrouve :
- Data Pages : valeur actuelle
- Footer : metadatas comme le schema, les row groups, des statistiques…