library(duckdb)
library(glue)
library(dplyr)
library(dbplyr)
library(mapview)Application 1 - Données spatiales
Pour lancer cette application, tout a été pré-automatisé avec le SSPCloud. Vous avez juste à cliquer sur le bouton ci-dessous.
ImportantPréparer son environnement pour ce TD
Les données ont été préparées en amont de ce TD. Un lien de lancement rapide est disponible ci-dessus qui met à disposition un environnement prêt à l’emploi sur le SSPCloud.
Après avoir cliqué sur le bouton en haut de cette page, il convient de créer un projet RStudio depuis le dossier appli1 (File > New Project) :
Git est normalement préconfiguré dans ce dossier, vous pourrez donc pusher votre travail sur Github si vous créez un dépôt dessus.
Si la récupération des données a échoué pour une raison x ou y, vous pouvez lancer la récupération des données en copiant ce code dans un terminal
#!/bin/bash
mkdir appli1
cd appli1
# Initializing git repo and renaming branch to main
git init
git branch -m main
mkdir data
echo "data/" >> .gitignore
# Download data from S3
curl https://minio.lab.sspcloud.fr/projet-formation/nouvelles-sources/data/geoparquet/dvf.parquet --output data/dvf.parquet --retry 5 --retry-all-errors --max-time 300
curl https://minio.lab.sspcloud.fr/projet-formation/nouvelles-sources/data/geoparquet/carreaux.parquet --output data/carreaux.parquet --retry 5 --retry-all-errors --max-time 300
curl https://minio.lab.sspcloud.fr/projet-formation/nouvelles-sources/data/triangle.geojson --output data/triangle.geojson --retry 5 --retry-all-errors --max-time 300
curl https://minio.lab.sspcloud.fr/projet-formation/nouvelles-sources/data/malakoff.geojson --output data/malakoff.geojson --retry 5 --retry-all-errors --max-time 300
curl https://minio.lab.sspcloud.fr/projet-formation/nouvelles-sources/data/montrouge.geojson --output data/montrouge.geojson --retry 5 --retry-all-errors --max-time 300Introduction
L’objectif de ce TP consiste à se familiariser à l’exploitation de données spatiale, notamment dans le cas où ces données seraient massives. Ainsi, le choix technique adopté porte sur la solution DuckDB.
DuckDB se distingue comme un système de gestion de base de données in-memory, léger et open source, conçu pour l’analyse de données analytiques. Sans être spécifique aux données spatiales, DuckDB est une solution parfaitement adaptée. Voici ses atouts clés :
- Adapté aux données volumineuses : DuckDB est conçu pour traiter des jeux de données volumineux sans les charger intégralement en mémoire vive (RAM). DuckDB utilise un moteur vectoriel et une exécution par colonnes, ce qui lui permet de ne lire et traiter que les parties nécessaires des fichiers (ex. : Parquet, CSV, GeoParquet). Les données restent stockées sur disque ou dans un stockage distant (comme S3), et seules les portions requises par la requête sont chargées en RAM.
- Performance : Optimisé pour des requêtes analytiques rapides, DuckDB rationalise et ordonnance les opérations, réduisant ainsi les risques de saturation mémoire, même avec des fichiers de plusieurs Go ou To (données géospatiales ou non)
- Simplicité : Pas besoin de serveur dédié ou de configuration complexe. DuckDB s’utilise comme une bibliothèque embarquée, idéale pour des analyses locales ou des pipelines légers.
- Interopérabilité : Compatible avec des formats courants (Parquet, GeoJSON, Shapefile), il s’intègre facilement dans des workflows Python, R ou CLI, et supporte les standards OGC (comme WKT/WKB).
- Extensibilité : Grâce à ses extensions, DuckDB permet de combiner des requêtes spatiales avec des analyses tabulaires classiques, offrant une solution unifiée pour des cas d’usage variés (ex. : agrégation de données géomarketing, analyse de réseaux).
A travers 3 applications, nous verrons comment requêter et exploiter des données avec DuckDB, en s’appuyant sur une syntaxe SQL native mais aussi une syntaxe plus proche de dplyr sur R.
Information sur les données
En premier lieu, ce TD utilise une source administrative nommée DVF (« Demandes de Valeurs Foncières »).
- Les données DVF recensent l’ensemble des ventes de biens fonciers réalisées au cours des dernières années, en métropole et dans les départements et territoires d’outre-mer — sauf à Mayotte et en Alsace-Moselle. Les biens concernés peuvent être bâtis (appartement et maison) ou non bâtis (parcelles et exploitations). Les données sont produites par la Direction générale des finances publiques (DGFip). Elles proviennent des actes enregistrés chez les notaires et des informations contenues dans le cadastre. Cette base a été filtrée de manière à être la plus pédagogique possible pour cette formation.
L’analyse de ces données sera complétée des données Filosofi produites par l’Insee :
- Les données spatiales carroyées à 200m, produites par l’Insee à partir du dispositif Filosofi, contentant des informations socio-économiques sur les ménages.
Enfin, nous proposons trois contours géographiques ad hoc :
- La commune de Malakoff
- La commune de Montrouge
- Le “Triangle d’or” de Malakoff (autrement dit, son centre-ville à peu de choses près)
L’objectif de ce TD est d’illustrer la manière dont peuvent être traitées des données spatiales de manière flexible avec duckdb.
Préparation de l’environnement
Les librairies suivantes seront utilisées dans ce TD, vous pouvez d’ores et déjà les charger dans votre environnement.
Si celles-ci ne sont pas installées, vous pouvez faire en console un install.packages (voir (note-bp-install?)).
Note
Les installations de packages sont à faire en console mais ne doivent pas être écrites dans le code. Bien que ce ne soit pas l’objet de ce cours, il est utile de suivre les bonnes pratiques recommandées à l’Insee et plus largement dans le monde .
Pour en savoir plus, vous pourrez explorer le portail de formation aux bonnes pratiques.
Nous allons avoir besoin des codes Insee suivants pour notre application :
cog_malakoff <- "92046"
cog_montrouge <- "92049"Import des données
L’import des contours en se fait assez naturellement grâce à sf.
triangle <- sf::st_read("data/triangle.geojson", quiet=TRUE)
malakoff <- sf::st_read("data/malakoff.geojson", quiet=TRUE)
montrouge <- sf::st_read("data/montrouge.geojson", quiet=TRUE)En premier lieu, on peut visualiser la ville de Malakoff :
mapview(malakoff) + mapview(triangle, col.regions = "#ffff00")Et ensuite les contours de Montrouge :
mapview(montrouge)Préparation de DuckDB
En principe, duckdb fonctionne à la manière d’une base de données. Autrement dit, on définit une base de données et effectue des requêtes (SQL ou verbes tidyverse) dessus. Pour créer une base de données, il suffit de faire un read_parquet avec le chemin du fichier.
La base de données se crée tout simplement de la manière suivante :
con <- dbConnect(duckdb::duckdb())
dbExecute(con, "INSTALL spatial;")
dbExecute(con, "LOAD spatial;")Nous verrons ultérieurement pourquoi nous avons besoin de cette extension spatiale.
Cette connexion duckdb peut être utilisée de plusieurs manières. En premier lieu, par le biais d’une requête SQL. dbGetQuery permet d’avoir le résultat sous forme de dataframe puisque la requête est déléguée à l’utilitaire duckdb qui est embarqué dans les fichiers de la librairie :
out <- dbGetQuery(
con,
'SELECT * EXCLUDE (geometry) FROM read_parquet("data/dvf.parquet") LIMIT 5'
)
outLa chaîne d’exécution ressemble ainsi à celle-ci :

Même si DuckDB simplifie l’utilisation du SQL en proposant de nombreux verbes auxquels nous sommes familier en R ou Python, SQL n’est néanmoins pas toujours le langage le plus pratique pour chaîner des opérations nombreuses. Pour ce type de besoin, le tidyverse offre une grammaire riche et cohérente. Il est tout à fait possible d’interfacer une base duckdb au tidyverse. Nous pourrons donc utiliser nos verbes préférés (mutate, filter, etc.) sur un objet duckdb : une phase préliminaire de traduction en SQL sera automatiquement mise en oeuvre :

table_logement <- tbl(con, 'read_parquet("data/dvf.parquet")')
table_logement %>% head(5)Partie 1 : Prix immobiliers à Malakoff et à Montrouge
Dans cette partie, l’objectif est d’extraire de l’informations d’une base de données volumineuse à l’aide de DuckDB. Pour le moment, le caractère spatial des données est mis de côté : on découvre et on traite les données via des requêtes attributaires classiques.
Tentons, par une première série d’exercices, de comparer la médiane des prix des transactions immobilières à Malakoff et à Montrouge.
Dans cette partie, nous allons pouvoir faire nos traitements de données avec SQL et/ou tidyverse. Cela illustre l’une des forces de duckdb, à savoir son excellente intégration avec d’autres écosystèmes dont nous sommes familiers.
Lorsque nous irons sur l’aspect spatial, nous passerons en SQL pur, l’écosystème tidyverse n’étant pas encore finalisé pour le traitement de données spatiales avec duckdb.
Premières requêtes SQL : description des données DVF
Tout d’abord, il convient de se familiariser avec les données. Les requêtes proposées pour l’exercice 1 permettent d’obtenir des informations primordiales de manière très rapide et sans nécessité de charger l’ensemble des données dans la mémoire vive.
ExerciceExercice 1
Cet exercice nous fera entrer progressivement dans les données à partir de quelques requêtes basiques.
- Lire les 10 premières lignes des données par l’approche SQL et par l’approche tidyverse.
- Afficher les noms des colonnes selon les deux approches.
- Regarder les valeurs uniques de la colonne
nature_mutationselon les deux approches. - Calculer les bornes min et max des prix des transactions selon ces deux approches.
À la question 1, vous devriez avoir :
A la question 2, la liste des colonnes donnera plutôt
[1] "id_mutation" "date_mutation"
[3] "numero_disposition" "nature_mutation"
[5] "valeur_fonciere" "adresse_numero"
[7] "adresse_suffixe" "adresse_nom_voie"
[9] "adresse_code_voie" "code_postal"
[11] "code_commune" "nom_commune"
[13] "code_departement" "ancien_code_commune"
[15] "ancien_nom_commune" "id_parcelle"
[17] "ancien_id_parcelle" "numero_volume"
[19] "lot1_numero" "lot1_surface_carrez"
[21] "lot2_numero" "lot2_surface_carrez"
[23] "lot3_numero" "lot3_surface_carrez"
[25] "lot4_numero" "lot4_surface_carrez"
[27] "lot5_numero" "lot5_surface_carrez"
[29] "nombre_lots" "code_type_local"
[31] "type_local" "surface_reelle_bati"
[33] "nombre_pieces_principales" "code_nature_culture"
[35] "nature_culture" "code_nature_culture_speciale"
[37] "nature_culture_speciale" "surface_terrain"
[39] "longitude" "latitude"
[41] "geometry" "__index_level_0__" Que contient le champ nature_mutation ? (il a été filtré aux ventes classiques pour simplifier cette application ; les vraies données sont plus riches).
A la question 4, vous devriez obtenir des statistiques similaires à celles-ci :
Nous venons de voir comment faire quelques requêtes basiques sur un fichier .parquet avec duckdb et l’équivalence entre les approches SQL et tidyverse. La dernière question était déjà une introduction au calcul à la volée de statistiques descriptives, ajoutons quelques statistiques avec ce nouvel exercice.
ExerciceExercice 2 : statistiques descriptives sur la dimension attributaire
Ne garder que les seules transactions effectuées à Montrouge ou Malakoff et faire une médiane par commune des montants des transactions
Faire ceci avec SQL et dplyr.
(Vous avez le droit d’utiliser votre assistant IA préféré ! Mais ne prenez pas pour argent comptant ce qu’il vous propose)
Avec l’approche SQL vous devriez obtenir
code_commune mediane_valeur_fonciere
1 92046 375000
2 92049 394500On peut se rassurer, on obtient la même chose l’approche dplyr :
On peut en conclure que les biens vendus à Montrouge (dans notre base) ont une médiane un peu plus élevée qu’à Malakoff.
Partie 2 : Part de ménages pauvres à Malakoff et à Montrouge
Pour finir, on se place dans le cas où :
- On souhaite extraire des informations d’un fichier volumineux (les données carroyées de l’Insee).
- Mais il n’est pas possible de filtrer les données par des requêtes attributaires (par exemple, il n’est pas possible de faire
code_commune = 92049).
Ainsi, nous allons :
- Utiliser les contours géographiques des deux communes
- Filtrer les données par intersections géographiques des carreaux et des communes, à l’aide de
DuckDB - Faire les calculs localement après l’extraction des carreaux d’intérêt.
Pour commencer, nous décrivons les données carroyées comme précédemment :
describe_dvf <- dbGetQuery(con, "DESCRIBE SELECT * FROM read_parquet('data/carreaux.parquet')")
describe_dvfpreview <- dbGetQuery(con, "SELECT * FROM read_parquet('data/carreaux.parquet') LIMIT 10")
previewOn va faire une petite transformation de données préliminaire à cet exercice afin que la géométrie du contour de Malakoff soit reconnue par DuckDB.
malakoff_2154 <- sf::st_transform(malakoff, 2154)
malakoff_wkt <- sf::st_as_text(sf::st_geometry(malakoff_2154))Voici comment faire une requête géographique sur les carreaux de Malakoff
geo_query <- glue("
FROM read_parquet('data/carreaux.parquet')
SELECT
*, ST_AsText(geometry) AS geom_text
WHERE ST_Intersects(
geometry,
ST_GeomFromText('{malakoff_wkt}')
)
")
carr_malakoff <- dbGetQuery(con, geo_query)
carr_malakoff <-
carr_malakoff |>
sf::st_as_sf(wkt = "geom_text", crs = 2154) |>
select(-geometry) |>
rename(geometry=geom_text)On peut les visualiser de la manière suivante
mapview(carr_malakoff) + mapview(sf::st_boundary(malakoff))
ExerciceExercice 3 : extraction des carreaux intersectant Malakoff
- Réitèrer l’opération pour Montrouge
- Calculer la proportion moyenne de ménages pauvre dans l’ensemble des carreaux extraits à partir des deux objets obtenus.
Le masque des carreaux de Montrouge est le suivant :
On obtient, in fine, les statistiques suivantes
Part de ménages pauvres dans les carreaux de Malakoff : 12.01Part de ménages pauvres dans les carreaux de Montrouge : 11.02Partie 3 : les prix immobiliers à Malakoff, dans le centre et en-dehors.
À présent, nous souhaitons avoir des informations sur les transactions effectuées dans le « glorieux » Triangle d’Or de Malakoff (plus prosaïquement, dans son centre-ville commerçant).
Il n’est pas possible de distinguer cette zone par requêtes attributaires : il n’existe pas de colonne permettant de distinguer cette zone :
ExerciceExercice 4
Via DuckDB, calculer la médiane des prix des transactions à l’intérieur et à l’extérieur du Triangle.
Démarche :
- 4.1 : Transformer l’objet sf1
triangleen WKT après l’avoir reprojeté en Lambert 2154 (même système de projection que les transactions DVF, voir Tip 1). - 4.2 : Faire un filtre attributaire sur la commune de Malakoff.
- 4.3 : Créer une colonne “in_triangle” booléenne et égale à TRUE pour les transactions présentes dans le triangle (utiliser la colonne “geometry”, au format WKB, voir Tip 2).
- 4.4 : Calculer les médianes en groupant sur la variable “in_triangle”.
Tip 1: Projection géographique
Pour se mettre dans des conditions proches du réel, nous mettons à disposition le triangle dans un système de projection différent des transactions. Cette situation arrive couramment en pratique et elle nécéssite de faire des reprojections adaptées avant toute opération géométrique entre deux sources de données spatiales.
Tip 2: Format des géométries (WKT, WKB)
Dans le fichier dvf.parquet, les coordonnées spatiales sont stockées dans un format binaire spécifique (Well-Known Binary - WKB). Ce format est efficace pour le stockage et les calculs, mais n’est pas directement lisible ou interprétable par les humains.
En revanche, le triangle est disponible sous forme d’objet sf (propre à notre environnement R) et nous devons le transformer en WKT (Well-Known Text - représentation texte lisible) avec sf::st_as_text() pour pouvoir être consommé par DuckDB.
4.1 : aide à la reprojection du Triangle
triangle_wkt <- triangle %>%
sf::st_transform(2154) %>% # Reprojection
sf::st_geometry() %>% # Extraction de la seule dimension spatiale
sf::st_as_text() # Transformation en WKT
triangle_wkt[1] "POLYGON ((648759.8 6858544, 648276.5 6857984, 649054.6 6857943, 648759.8 6858544))"Pour l’exercice 4.3, nous aurons besoin de la structure de requête suivante pour créer la variable “in_triangle” :
ST_Within(
..., # nom de la colonne spatiale du fichier des transactions
ST_GeomFromText(...) # Coordonnées du triangle en WKT
) as in_triangleVoici les transactions de Malakoff avec la colonne “in_triangle” (masque booléen).
Ces transactions sont importées en mémoire vive par souci pédagogique mais le calcul des médianes d’intérêt pourrait être directement réalisé dans la même requête.
Une fois que chaque transaction est identifiée comme étant à l’intérieur ou à l’extérieur du Triangle, le calcul de la médiane des prix se fait simplement par group_by (ici avec dplyr).
Médiane des prix dans le Triangle d'Or de Malakoff : 383500Médiane des prix dans le reste de Malakoff : 370000Quête secondaire : calculer directement les médianes avec une seul requête SQL (sans import des transactions en RAM).
La médiane des prix est un peu plus élevée dans le Triangle qu’en dehors. On peut aller au-delà et étudier la distribution des transactions. Bien que la taille d’échantillon soit réduite, on a ainsi une idée de la diversité des prix dans cette bucolique commune de Malakoff.
Produire la figure sur la distribution du prix des biens
library(ggplot2)
library(scales)
ggplot(
transactions_malakoff,
aes(y = valeur_fonciere, x = in_triangle, fill = in_triangle)
) +
geom_violin() +
scale_y_continuous(
trans = "log10",
labels = comma_format(),
breaks = scales::trans_breaks("log10", function(x) 10^x)
) +
geom_jitter(height = 0, width = 0.1) +
labs(y = "Valeur de vente (€)") +
theme_minimal()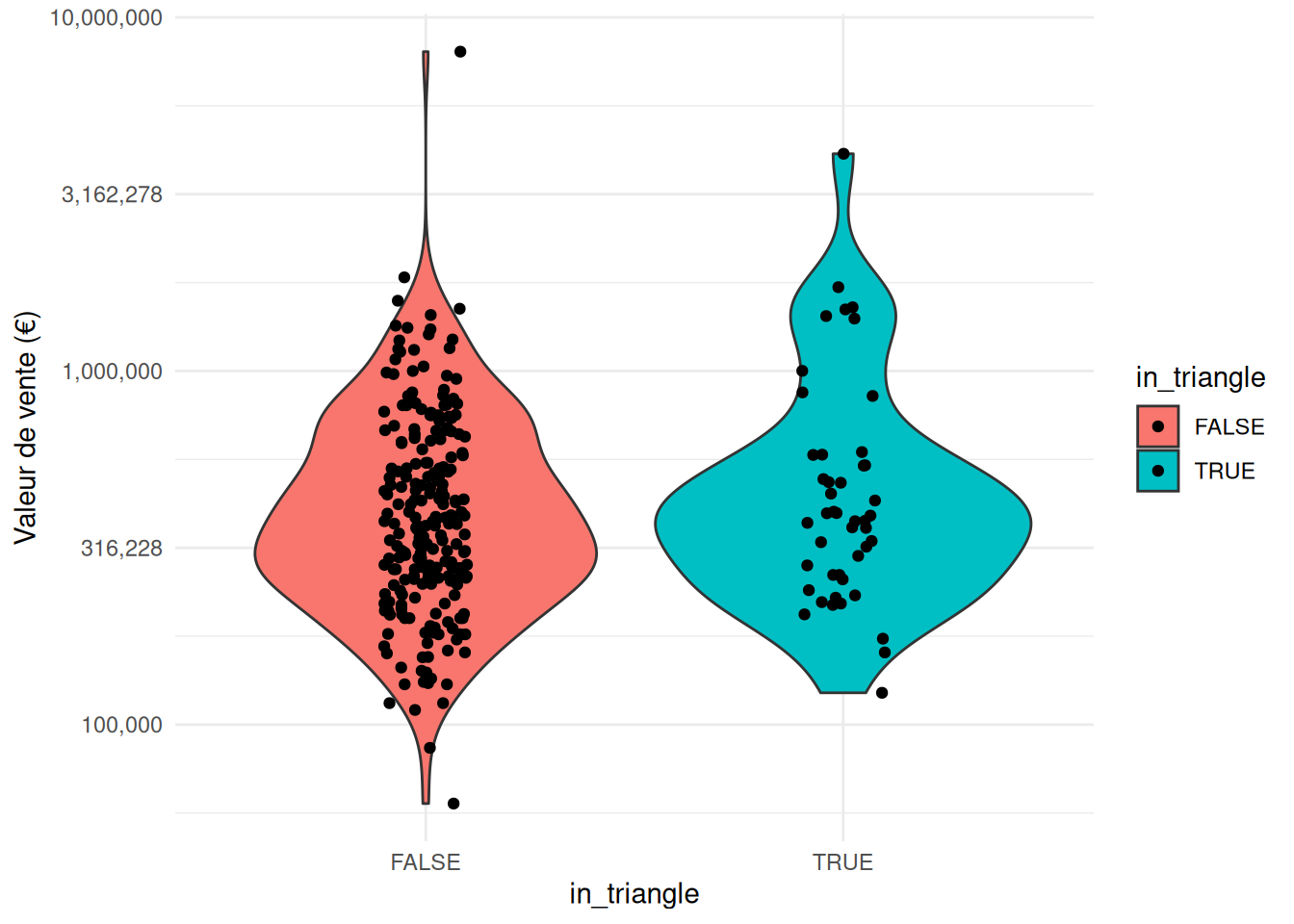
Tout ceci ne nous dit rien de la différence entre les biens dans le triangle et en dehors de celui-ci. Nous n’avons fait aucun contrôle sur les caractéristiques des biens. Nous laissons les curieux explorer la mine d’or qu’est cette base.
Conclusion
Nous avons donc réussi à lire des données avec DuckDB et à faire des statistiques dessus. Pourquoi est-ce pertinent de passer par DuckDB ? Car ce package permet de faire ceci de manière très efficace sur de gros volumes de données. Il passe très bien à l’échelle.
A noter que notre démarche est une introduction à ce sujet bien plus large qu’est l’analyse géographique. Notre approche serait améliorable sur plusieurs plans :
- rationalisation des requêtes,
- pertinence statistique des résultats
- réplicabilité du code
Footnotes
le package sf (simple features) permet de définir et exploiter des données spatiales facilement↩︎