html`
<div style="display: flex; flex-direction: column; gap: 1rem;">
<!-- Search bar at the top -->
<div>${viewof search}</div>
<!-- Two-column block -->
<div style="display: grid; grid-template-columns: 1fr 1fr; gap: 1rem; backgroundColor: '#293845';">
<div>${produce_histo(dvf)}</div>
<div>${viewof table_dvf}</div>
</div>
</div>
`Le format de données Parquet
Ateliers du SSPHub #2
16 avril 2025
“The obligatory intro slide”

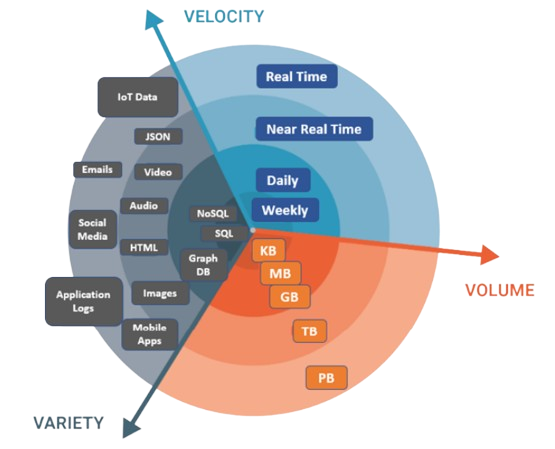
Enjeux
- Tendance à la massification des données
- Relatif aux capacités de stockage et de traitement
Limites du CSV
- Des performances limitées
- Stockage : non-compressé -> espace disque élevé
- Lecture : “orienté-ligne” -> performances faibles
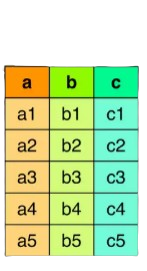
- Pas de typage des données à l’écriture du fichier
- Demande expertise et précaution à la lecture
- Exemple: 01004 pour le code commune d’Ambérieu-en-Bugey
Un format efficace
- Lecture :
- Jusqu’à 34x plus rapide qu’un CSV
- “Orienté colonne”
- Optimisé pour les traitements analytiques
- Limite la quantité de données à mettre en mémoire
- Conçu pour être écrit une fois mais lu fréquemment
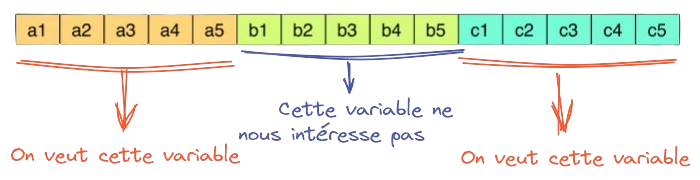
Pour optimiser la lecture
- Partitionner ou ordonner les données
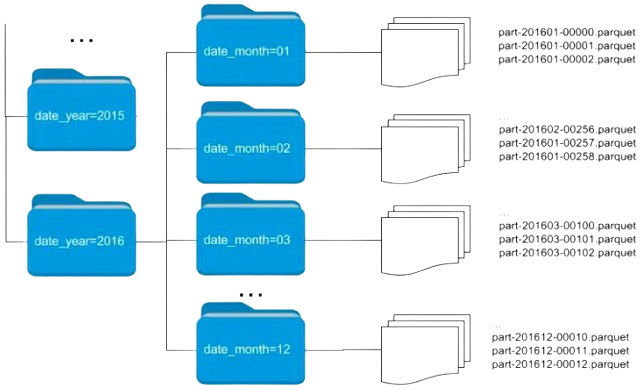
L’art de bien partitionner
- Partitionner par une/des variable(s) d’intérêt si gros fichier
- Eviter de créer de nombreux petits (< 128Mo) fichiers
- Sinon ordonner les données avant d’écrire le fichier (cf. Eric Mauvière)
Parquet: quels usages ?
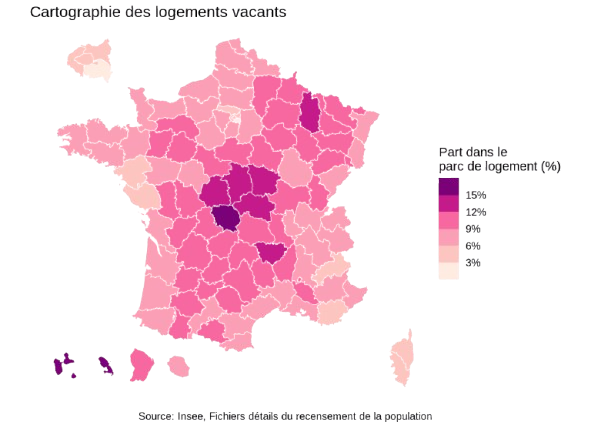

Exemples de cartes pouvant être produites simplement avec les données du recensement diffusées par l’Insee
Les frameworks
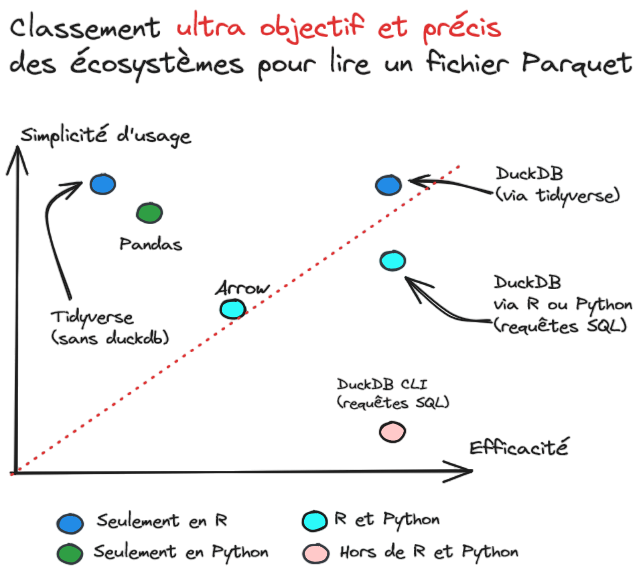
La lazy evaluation
- Voici le début du plan:
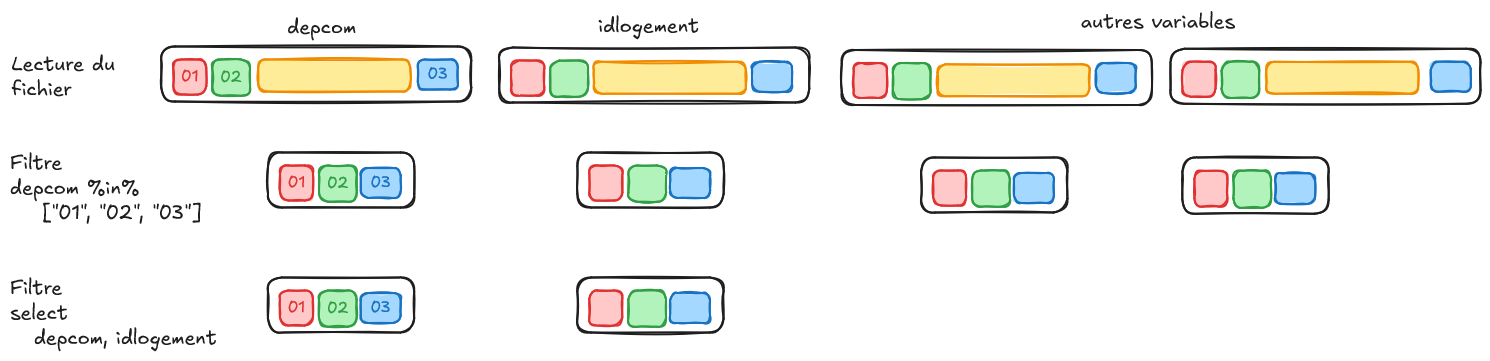
❓️ Pourrait-il être optimisé ?
La lazy evaluation
- Voici le plan plus optimal:
- Predicate pushdown
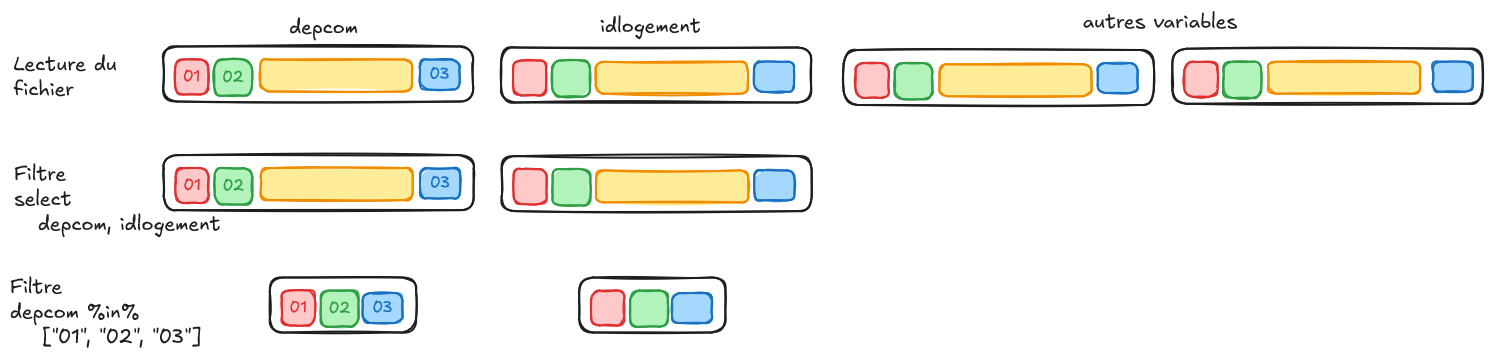
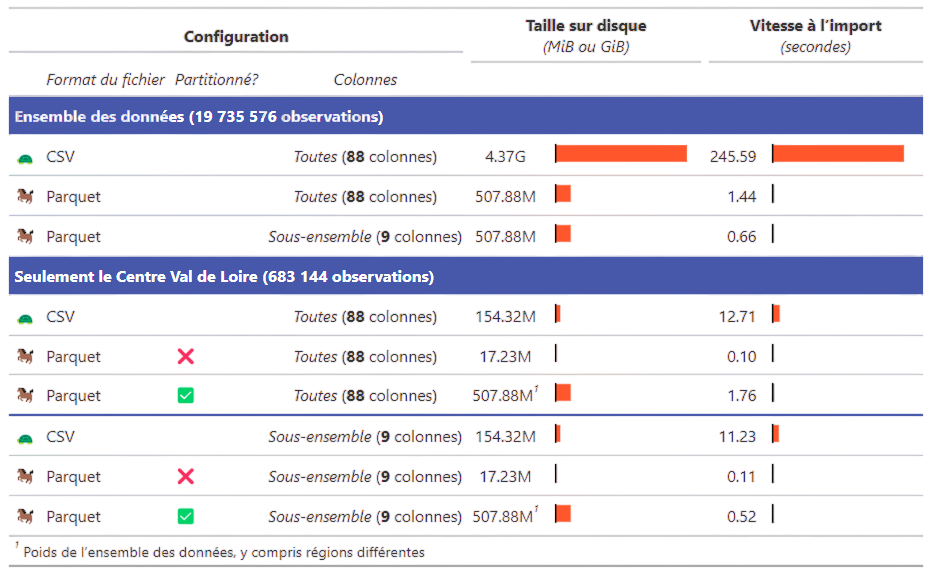
Parquet gagne sur tous les tableaux
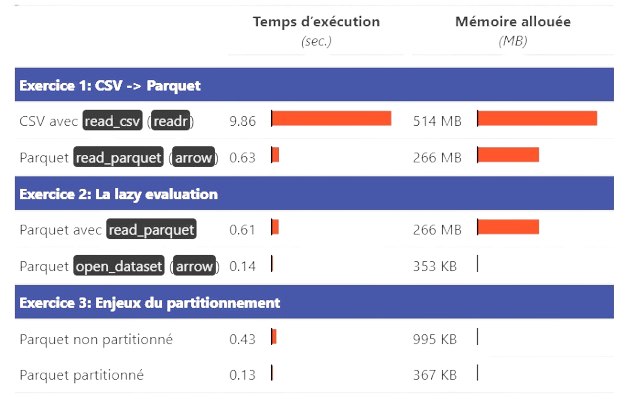
Applications
Ce n’est pas fini !

Des questions ?
