source("correction/R/create_data_list.R")Un tableau de bord du trafic aérien avec ou
| Niveau technique | Enjeux |
|---|---|
| Suivre les consignes, tester les exemples, reprendre et comprendre les corrections. Ne pas se préoccuper de la fin du tutoriel (l'ouverture vers la mise en production). | |
| Chercher à faire les exercices et ne regarder les aides que si nécessaire. Ne pas se préoccuper de la fin du tutoriel (l'ouverture vers la mise en production). | |
| Faire les premiers exercices en autonomie. L'objectif principal est de faire la partie mise en production. |
1 Introduction
1.1 Objectif
L’objectif de ce tutoriel est d’amener, pas à pas, à la conception voire à la mise à disposition d’un tableau de bord (dashboard) du trafic aérien avec ou . Ce tutoriel est également l’occasion d’apprendre quelques bonnes pratiques pour les projets et . Une démonstration de cette application est disponible sur
L’objectif est de construire progressivement cette application en suivant les étapes logiques du déroulement d’un projet de développement d’application interactive : découverte et exploration des données, création de statistiques descriptives et de visualisations simples sur un jeu de données, extension du nombre de visualisations accessibles par la création d’une application.
L’objectif secondaire de ce tutoriel est de faire découvrir quelques bonnes pratiques de programmation avec ou afin de rendre les projets plus fiables, évolutifs et lisibles. Comme vous pourrez le faire au cours de celui-ci, la différence entre ces deux langages est assez minime. L’un des objectifs de ce tutoriel est de vous amener à structurer votre projet selon la norme suivante:
Les exercices de conception pas à pas de l’application s’adressent aussi bien à des débutants qu’à des utilisateurs plus avancés. La mise à disposition, c’est-à-dire la mise en production de cette application, fait toutefois appel à des concepts et outils plus avancés et est donc moins accessible à des débutants.
Note
Afin de se concentrer sur la démarche, cette application interactive présentera un nombre limité de fonctionnalités.
Si vous disposez de temps supplémentaire, n’hésitez pas à ajouter des fonctionnalités à celle-ci et à les proposer pour un ajout dans la galerie du site web du funathon (inseefrlab.github.io/funathon2024/).
1.2 Pourquoi développer une application interactive ?
Cette question peut apparaître naïve. Pourtant, elle mérite d’être posée car elle permet de réfléchir:
- à l’objectif de l’application ;
- à son public cible.
Cette réflexion devrait être menée systématiquement car elle guide les choix techniques ultérieurs et la répartition des tâches entre les différents profils pouvant intervenir dans la vie du projet s’il est mis en production (statisticien ou data scientist, équipes informatiques…).
1.2.1 Une valorisation de données rapide et attractive
En général, on fait de la visualisation de données car les sources de données exploitées présentent tellement de dimensions pouvant intéresser un utilisateur qu’il est plus pertinent de le laisser explorer les données que de définir pour lui les statistiques à mettre en avant. L’interactivité permise par les sites web est particulièrement adaptée pour cela : le fait d’afficher ou masquer des visualisations en fonction de choix de l’utilisateur évite de noyer l’information par rapport à des supports figés.
Les frameworks Shiny (), Streamlit ou Dash () permettent de rapidement mettre en oeuvre ce type de site web. Pour une phase de construction d’un prototype, c’est un choix technique intéressant qui peut provoquer l’effet wahou attendu pour lancer le projet à plus grande échelle. En effet, ces solutions techniques permettent, avec les outils bien connus des praticiens de la donnée ( ou ) de créer rapidement un site web fonctionnel, ergonomique et effectuant des opérations en fonction d’actions de l’utilisateur sur la page web. Tout ceci sans avoir à maîtriser des notions complexes de développement web.
1.2.2 Une mise à disposition parfois complexe
Néanmoins, passée cette phase d’expérimentation, le partage de ces applications, au-delà d’un partage d’écran pour des démonstrations, n’est pas toujours évident (d’où le fait, nous y reviendrons, que la dernière partie de ce tutoriel s’adresse plutôt à un niveau expert). Cette difficulté est due au fait qu’assurer le bon fonctionnement d’un site web pérenne requiert la maîtrise de notions complexes, qui ne sont pas nécessaires au cours de la phase d’expérimentation. Celles-ci dépassent néanmoins le champ de compétence des statisticiens ou data scientists.
Autrement dit, si le projet a l’ambition d’être partagé à une audience large qui n’a pas les compétences techniques pour faire tourner elle-même le code, il convient de prendre en compte le fait qu’il faudra dans l’équipe projet des compétencess spécifiques de développement web. Si le projet est expérimental, c’est moins un problème : Shiny, Dash ou Streamlit permettront d’avoir rapidement un prototype viable.
Il existe heureusement des solutions techniques plus simples à mettre en oeuvre que Shiny, Streamlit ou Dash. Les sites web statiques font partie de cet éventail des possibles et représentent souvent une alternative pertinente aux applications interactives à condition qu’ils soient bien pensés. Ils sont notamment pertinents pour les applications de visualisation de données où cette dernière est déjà préparée en amont. Avoir un serveur R ou Python se justifie en effet si des étapes complexes de structuration de données interviennent. Inversement, si aucun traitement de données complexe n’est nécessaire, un simple enrobage avec un constructeur de site comme Quarto peut suffire, à condition que les productions graphiques ne soient pas trop complexes à créer. Pour des sites faisant intervenir des interactions multiples entre actions d’un utilisateur (bouton, menu déroulant, etc. ) et affichage, il faudra recourir à du Javascript (technologie utilisée par les sites spécialisés dans la dataviz), ce qui fait, à nouveau, appel à des compétences qui dépassent celles des data scientists ou statisticiens classiques.
En résumé, les éléments ci-dessus ont vocation à servir de mise en garde. Shiny, Dash ou Streamlit sont d’excellents outils techniques lorsqu’ils sont utilisés à bon escient. Ceci dit, leur simplicité d’usage ne dispense pas de se poser des questions cruciales comme celles du cycle de vie du projet, du public cible ou encore de la compétence des équipes amenées à maintenir le projet s’il perdure au-delà d’une phase d’expérimentation.
Site statique vs application réactive
La distinction principale entre ces deux approches est qu’elles s’appuient sur des serveurs différents. Un site statique repose sur un serveur web là où Shiny/Streamlit s’appuient sur des serveurs classiques en backend. La différence principale entre ces deux types de serveurs réside principalement dans leur fonction et leur utilisation :
- Un serveur web est spécifiquement conçu pour stocker, traiter et livrer des pages web aux clients. Cela inclut des fichiers HTML, CSS, JavaScript, images, etc. Les serveurs web écoutent les requêtes HTTP/HTTPS provenant des navigateurs des utilisateurs et y répondent en envoyant les données demandées.
- Un serveur backend classique est conçu pour effectuer des opérations en réponse à un front, en l’occurrence une page web. Dans le contexte d’une application
Streamlit(resp.Shiny), il s’agit d’un serveur avec l’environnementPython(resp.R) ad hoc pour exécuter le code nécessaire à répondre à toute action d’un utilisateur de l’application.
2 Exploration des données de trafic aérien
Pour pouvoir proposer un tableau de bord pertinent, le premier geste à avoir est d’explorer soi-même les données. L’objectif de cette partie est de guider le travail exploratoire. Le travail ultérieur sur l’application visera à consolider et généraliser ces explorations de données.
2.1 Préliminaire : récupérer le projet squelette avec Git
Si vous disposez d’un compte sur le sspcloud, la méthode recommandée pour se lancer dans ce tutoriel est de cliquer sur le bouton suivant
La démarche de récupération a été expliquée au cours de la présentation de l’environnement technique. Voici, en résumé, les gestes à faire:
- Forker le dépôt
InseeFrLab/funathon2024_sujet2 - Cliquer sur le bouton ci-dessous:
- Sur la page
SSPCloudqui s’ouvre, changer l’URL indiqué dans l’ongletGitpour mettre celui de votre fork
Revoir la vidéo de présentation sur https://inseefrlab.github.io/funathon2024 (à démarrer à partir de 1h29mn)
La démarche de récupération est assez similaire à celle expliquée pour . Voici, en résumé, les gestes à faire:
- Forker le dépôt
InseeFrLab/funathon2024_sujet2 - Cliquer sur le bouton ci-dessous:
- Sur la page
SSPCloudqui s’ouvre, changer l’URL indiqué dans l’ongletGitpour mettre celui de votre fork
Revoir la vidéo de présentation sur https://inseefrlab.github.io/funathon2024 (à démarrer à partir de 1h29mn)
Si vous avez utilisé le lien de lancement rapide mis à disposition sur la page inseefrlab.github.io/funathon2024/ ou ci-dessus ☝️, vous pouvez sauter l’étape de récupération du modèle de projet avec Git , cela a été fait automatiquement lors de la création de votre environnement RStudio ou VSCode. Cela ne vous dispense pas de faire du Git tout au long du tutoriel 😺, c’est une bonne pratique, même sur des projets ponctuels ou vous êtes seuls à travailler.
Récupérer le projet si vous n’avez pas utilisé le bouton proposé
La fiche utilitR sur l’utilisation de Git explicite la démarche générale pour récupérer du code grâce à Git. Il est recommandé de lire celle-ci si vous n’êtes pas familier de Git.
Les étapes suivantes permettront de récupérer le projet:
1️⃣ En premier lieu, dans RStudio, créer un nouveau projet et sélectionner Version Control.

2️⃣ Choisir Git, ce qui devrait ouvrir une fenêtre similaire à celle ci-dessous:

3️⃣ Dans la fenêtre Repository URL, passer la valeur
https://github.com/inseefrlab/funathon2024_sujet2.gitlaisser les valeurs par défaut qui viennent ensuite et créer le projet.
Après avoir ouvert un terminal dans RStudio, faire
git clone https://github.com/inseefrlab/funathon2024_sujet2.gitpuis, dans l’explorateur de fichiers (fenêtre en bas à droite), cliquer sur le fichier RTraffic.Rproj pour ouvrir le projet.
- Ouvrir un terminal depuis
VSCode(Terminal>New Terminal). - Récupérer, sur la page d’accueil de votre dépôt, l’url du dépôt distant. Il prend la forme suivante
https://github.com/<username>/<reponame>.git- Dans le terminal, taper
git clone repo_urloù repo_url est l’URL de votre fork
2.2 Se placer dans l’environnement du projet
A la racine du projet, on trouve notamment le fichier RTraffic.Rproj. Il s’agit d’un fichier de projet RStudio. Lorsqu’on travaille sur du code avec RStudio, il est généralement préférable de travailler dans le cadre d’un projet.
Entre autres raisons, évoquées dans la documentation utilitR, cela favorise la reproductibilité: lorsqu’on se situe dans un projet RStudio, tous les chemins peuvent être définis de manière relative (à la racine du projet) plutôt que de manière absolue (à la racine de la machine). Ainsi, le projet s’exécutera de la même manière qu’il soit exécuté depuis une machine Windows ou Linux par exemple, avec des noms d’utilisateurs différents ou s’ils se situent dans des dossiers différents au sein de “Mes Documents”.
Plus de détails dans
utilitR
Pour plus de détails sur les bénéfices d’utiliser les projets RStudio ou leur utilisation en pratique, n’hésitez pas à consulter la fiche utilitR dédiée.
Les utilisateurs de connaissent deux environnements de travail très différents: la ligne de commande pour exécuter des scripts ou les notebooks Jupyter pour avoir un environnement interactif.
Les seconds sont pratiques pour prototyper et expérimenter. Mais ils ne sont pas faits pour construire des applications. Nous proposons donc la méthode de travail suivante:
- Créer un
Jupyter Notebookà la racine du projet (au même niveau que leREADME.md)1. Celui-ci sera votre espace pour écrire du code expérimental. Lorsqu’il sera fonctionnel, vous pourrez le reporter dans des scripts comme indiqués dans les consignes. - Dans un terminal, faire
cd funathon2024_sujet2(ou remplacer par le nom de dossier différent si vous l’avez changé). C’est dans ce terminal que vous testerez vos scripts. Pour ouvrir un terminal, il suffit de cliquer sur le menu VScode en haut à gauche (les trois petites barres horizontales), puisTerminal > New Terminal.
2.3 Architecture du projet
Le projet récupéré comporte de nombreux fichiers. Nous allons progressivement les découvrir dans ce tutoriel. A l’heure actuelle, on peut se concentrer sur les fichiers suivants:
funathon_sujet2/
├── renv.lock
├── correction/R/
├── correction/global.R
├── correction/server.R
└── correction/ui.RLe premier fichier (renv.lock) correspond à la liste des packages nécessaires pour reproduire l’environnement. Il a été généré automatiquement grâce à un écosystème renv particulièrement adapté pour assurer la reproductibilité de projets (voir la suite).
Les fichiers server.R et ui.R constituent le coeur de notre application Shiny. Ils représentent, respectivement, le moteur de calcul (le serveur) et l’interface utilisateur de notre application. Nous reviendrons sur ce concept. Le fichier global.R stocke un certain nombre d’objets utiles à l’application mais qui n’ont pas besoin d’être recalculés à chaque action sur l’interface graphique. Nous allons progressivement construire ces fichiers pendant les différents exercices. De nombreuses fonctions sont reportées dans les fichiers au sein du dossier R/.
Observer la composition de ce fichier (100 premières lignes)
renv.lock
{
"R": {
"Version": "4.3.3",
"Repositories": [
{
"Name": "CRAN",
"URL": "https://packagemanager.posit.co/cran/latest"
}
]
},
"Packages": {
"BH": {
"Package": "BH",
"Version": "1.84.0-0",
"Source": "Repository",
"Repository": "CRAN",
"Hash": "a8235afbcd6316e6e91433ea47661013"
},
"DBI": {
"Package": "DBI",
"Version": "1.2.2",
"Source": "Repository",
"Repository": "CRAN",
"Requirements": [
"R",
"methods"
],
"Hash": "164809cd72e1d5160b4cb3aa57f510fe"
},
"DT": {
"Package": "DT",
"Version": "0.33",
"Source": "Repository",
"Repository": "RSPM",
"Requirements": [
"crosstalk",
"htmltools",
"htmlwidgets",
"httpuv",
"jquerylib",
"jsonlite",
"magrittr",
"promises"
],
"Hash": "64ff3427f559ce3f2597a4fe13255cb6"
},
"KernSmooth": {
"Package": "KernSmooth",
"Version": "2.23-22",
"Source": "Repository",
"Repository": "CRAN",
"Requirements": [
"R",
"stats"
],
"Hash": "2fecebc3047322fa5930f74fae5de70f"
},
"MASS": {
"Package": "MASS",
"Version": "7.3-60.0.1",
"Source": "Repository",
"Repository": "CRAN",
"Requirements": [
"R",
"grDevices",
"graphics",
"methods",
"stats",
"utils"
],
"Hash": "b765b28387acc8ec9e9c1530713cb19c"
},
"Matrix": {
"Package": "Matrix",
"Version": "1.6-5",
"Source": "Repository",
"Repository": "CRAN",
"Requirements": [
"R",
"grDevices",
"graphics",
"grid",
"lattice",
"methods",
"stats",
"utils"
],
"Hash": "8c7115cd3a0e048bda2a7cd110549f7a"
},
"R6": {
"Package": "R6",
"Version": "2.5.1",
"Source": "Repository",
"Repository": "RSPM",
"Requirements": [
"R"
],
"Hash": "470851b6d5d0ac559e9d01bb352b4021"
},
"RColorBrewer": {funathon_sujet2/
├── requirements.txt
├── correction/src/
└── correction/app.pyLe premier fichier (requirements.txt) correspond à la liste des packages nécessaires pour reproduire l’environnement. Il s’agit d’un outil particulièrement adapté pour assurer la reproductibilité de projets (voir la suite).
Le fichier app.py constitue le coeur de notre application Streamlit. Ils représentent, respectivement, le moteur de calcul (le serveur) et l’interface utilisateur de notre application. Nous reviendrons sur ce concept. Par ailleurs, de nombreuses fonctions utiles pour l’application sont reportées dans les fichiers au sein du dossier src/ (abréviation de “source”).
Observer la composition de ce fichier
requirements.txt
pandas
geopandas
pyyaml
plotly
plotnine
great_tables
folium
streamlit
streamlit-folium2.4 Installer les packages nécessaires pour ce tutoriel
2.4.1 Principe
Pour progresser dans ce tutoriel, un certain nombre de packages doivent être installés. Sans eux, même avec le code de l’application, vous ne serez pas en mesure de reproduire celle-ci.
Les bonnes pratiques pour la gestion de l’environnement sont assez proches en et . Le principal général est qu’il existe des outils qui permettent à un utilisateur de lister l’ensemble des packages dans son environnement avec leur version. Grâce à cette liste, d’autres personnes pourront reproduire l’application si elles disposent des mêmes inputs (le code, les données…).
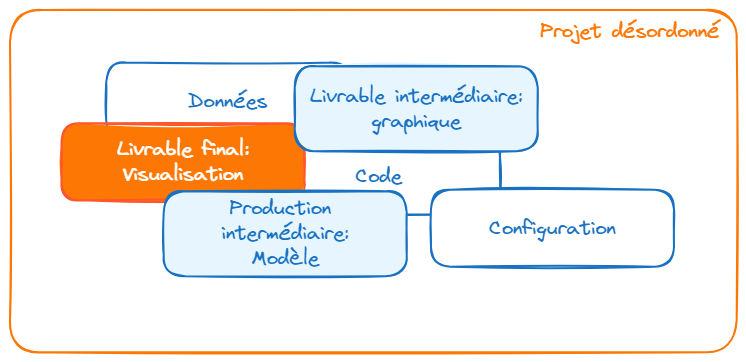
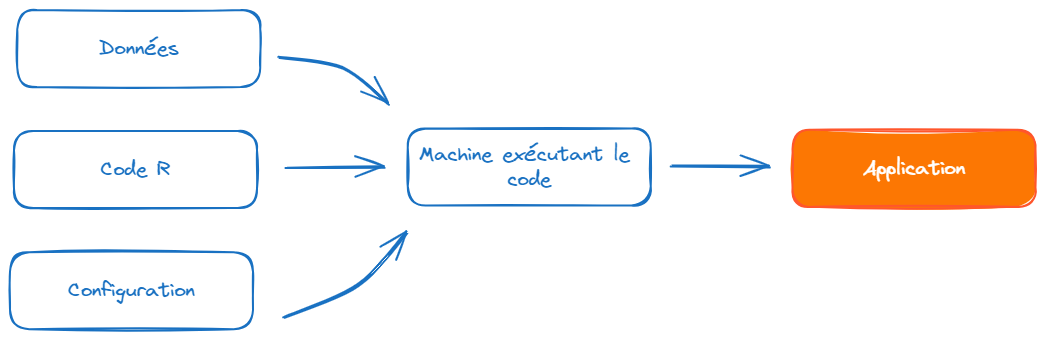
En effet, il est important de voir l’application comme le résultat de la combinaison de plusieurs ingrédients. Dans notre cas, nous en avons trois:
- Du code ou : celui-ci a été récupéré grâce à
Gitlors du lancement du projet; - Des éléments de configuration:
- Des données : nous évoquerons celles-ci lors de la prochaine partie.

De manière générale, c’est une bonne pratique de structurer son projet comme une combinaison de ces facteurs. Cela vous amènera à faire des projets plus reproductibles mais aussi à la structure plus lisible.
Pour les utilisateurs de R, la formation de l’Insee aux bonnes pratiques consacre une partie aux environnements reproductibles avec renv. Pour les utilisateurs de Python, le cours de mise en production de projets data science consacre un chapitre au sujet.
2.4.2 Créer l’environnement
Si vous avez déjà tenté de partager un code qui fonctionnait chez vous, il est presque certain que la personne ayant voulu le réutiliser a rencontré une erreur si elle a tenté de le faire tourner. C’est tout à fait normal car vous avez distribué votre code, éventuellement vos données, mais pas le troisième pilier de l’image précédente, à savoir la configuration de l’environnement dans lequel votre code fonctionnait. La solution la plus fiable, mais peu pratique, serait de donner votre ordinateur à la personne qui tente de réutiliser votre code. En livrant votre ordinateur, vous fournissez votre environnement de travail mais également beaucoup d’éléments supplémentaires qui ne sont pas indispensables à l’application.
Une solution plus simple est de fournir les spécifications qui ont permis à votre code de fonctionner. Dans un monde idéal, il s’agit de fournir la liste des packages et leur version. Si la personne à qui vous partagez votre code et vos données a cette même liste de versions de packages, et pas de packages supplémentaires venant polluer l’environnement, les chances d’avoir la même application que vous sont très élevées.
Les solutions techniques pour restaurer un environnement et sont légèrement différentes et sont décrites ci-dessous.
renv est un gestionnaire de packages qui permet de faire ces deux opérations :
- Enregistrer la liste de packages après avoir fait tourner un code
- Restaurer l’environnement à partir de cette liste
En l’occurrence, pour vous, l’important est le second point: pouvoir recréer l’environnement nécessaire au bon fonctionnement de l’application. Ceci est très simple grâce à la commande
A lancer dans la console R
renv::restore()Cette commande doit être lancée depuis la console R ouverte dans le projet qui a été récupéré3. L’environnement créé n’est pas figé. Il est tout à fait possible, ensuite, d’installer des packages supplémentaires par le biais de install.packages. L’environnement proposé par notre fichier renv.lock est le minimum requis pour reproduire l’application mais ce n’est pas un environnement figé. Si vous ajoutez des packages utiles pour votre application, avant la phase de mise en production, n’oubliez pas de faire renv::snapshot() pour mettre à jour le fichier renv.lock (c’est le point 1. évoqué précédemment).
Ce que
renv évite
On retrouve parfois sur internet un code similaire à celui-ci :
# A ne pas reproduire chez vous 😨
if (!requireNamespace("dplyr", quietly = TRUE)) {
install.packages("dplyr")
}C’est une gestion artisanale de l’environnement qui n’est pas conseillée. renv sera plus simple et plus fiable. De manière générale, ce n’est pas une bonne pratique de gérer l’installation des packages dans le script. En effet, c’est un élément de configuration et, comme nous l’avons dit, celle-ci doit se faire en dehors du script.
Maintenant que nous disposons d’un environnement fonctionnel, nous pouvons avancer sur la conception du projet. La première étape est d’explorer les jeux de données que nous utiliserons dans l’application.
Pour faire les choses bien, il faudrait repartir d’un environnement vierge et installer toutes les dépendances du projet (comme le fait la solution ).
Néanmoins, si vous êtes sur le SSPCloud, c’est presque de l’excès de zèle de faire cela car l’application a été développé à partir de l’environnement du SSPCloud duquel elle ne diverge que très peu. Il suffit donc d’ajouter à l’environnement existant un nombre restreint de packages qui sont listés dans requirements.txt.
Dans le terminal, il suffit donc de faire un pip install adéquat:
pip install -r requirements.txt
Ce que ce fichier
requirements.txt évite
On retrouve parfois dans des notebooks partagés sur internet un code similaire à celui-ci :
# A ne pas reproduire chez vous 😨
!pip install geopandasvoire parfois dans des scripts, ce type de code:
# A ne pas reproduire chez vous 😨
import subprocess
subprocess.run(["pip install geopandas"]) C’est une gestion artisanale de l’environnement qui n’est pas conseillée. De manière générale, ce n’est pas une bonne pratique de gérer l’installation des packages dans le script. En effet, c’est un élément de configuration et, comme nous l’avons dit, celle-ci doit se faire en dehors du script.
3 Récupérer les données
3.1 Objectifs
Dans cette partie, vous allez explorer les données utilisées pour construire le tableau de bord, avec trois objectifs:
- vous familiariser avec les sources statistiques sur le trafic aérien;
- développer des fonctions permettant d’importer automatiquement ces données;
- découvrir comment vous pouvez organiser ces fonctions pour qu’elles puissent être facilement utilisées par l’application web (spoiler alert: c’est là que le dossier
R/ousrc/va servir).
3.2 Sources
Les sources statistiques utilisées dans ce tutoriel sont listées dans le fichier sources.yaml. Il y a quatre sources différentes:
- Le trafic au niveau de chaque aéroport (format CSV);
- Le nombre de passagers pour différentes liaisons (format CSV);
- Le trafic pour différentes compagnies (format CSV);
- Les localisations des aéroports (format geojson).
Une bonne pratique, lorsqu’on utilise plusieurs sources, est de lister celles-ci dans un fichier YAML plutôt que de les inscrire en brut dans le code. Ce dernier sera plus lisible grâce à cette approche.
Voir le fichier sources.yml
sources.ymlsources.yml
# Jeux de données
# https://www.data.gouv.fr/fr/datasets/trafic-aerien-commercial-mensuel-francais-par-paire-daeroports-par-sens-depuis-1990/
airports:
2018: "https://www.data.gouv.fr/fr/datasets/r/3b7646ea-276c-4c9b-8151-1e96af2adbf9"
2019: "https://www.data.gouv.fr/fr/datasets/r/e8efa154-045e-4f8f-a1d7-76a39fa03b7b"
2020: "https://www.data.gouv.fr/fr/datasets/r/6717f107-be00-4b4b-9706-fa0e5190fb69"
2021: "https://www.data.gouv.fr/fr/datasets/r/2f9f6e54-e2d7-4e85-b811-2e5e68fa5bca"
2022: "https://www.data.gouv.fr/fr/datasets/r/f1bd931e-c99e-41ce-865e-9e9785c903ec"
liaisons:
2018: "https://www.data.gouv.fr/fr/datasets/r/9c5354ad-31cb-4217-bc88-fb7c9be22655"
2019: "https://www.data.gouv.fr/fr/datasets/r/0c0a451e-983b-4f06-9627-b5ff1bccd2fc"
2020: "https://www.data.gouv.fr/fr/datasets/r/dad30bed-7276-4a67-a1ab-a856e6e01788"
2021: "https://www.data.gouv.fr/fr/datasets/r/bbf6492d-86ac-43a0-9260-7df2ffdb5a77"
2022: "https://www.data.gouv.fr/fr/datasets/r/af8950bc-e90a-4b7e-bb81-70c79d4c3846"
compagnies:
2018: "https://www.data.gouv.fr/fr/datasets/r/ddfea6a0-df7e-4402-99fc-165f573f2e10"
2019: "https://www.data.gouv.fr/fr/datasets/r/8421e029-c8c7-410d-b38c-54455ac3265d"
2020: "https://www.data.gouv.fr/fr/datasets/r/818eec10-6122-4788-8233-482e779ab837"
2021: "https://www.data.gouv.fr/fr/datasets/r/0b954774-ccd1-43ec-9b5a-f958fba03e87"
2022: "https://www.data.gouv.fr/fr/datasets/r/bcec3e1e-940a-4772-bc28-0d7b2b53c718"
geojson:
airport: "https://minio.lab.sspcloud.fr/projet-funathon/2024/sujet2/aeroports.geojson"
3.3 Importer la liste des sources disponibles
Les consignes de cet exercice sont quasiment identiques selon le langage car les librairies R et Python pour lire des fichiers YAML portent le même nom.
Voir la solution à cet exercice
#' Creates a 2-levels list of urls, pointing to open source data
#'
#' @param source_file yaml file containing data urls
#' @return list (level 1 = concepts, level 2 = year).
#'
#' @examples
#' create_data_list("sources.yml")
#'
create_data_list <- function(source_file){
catalogue <- yaml::read_yaml(source_file)
return(catalogue)
}La fonction-solution de cet exercice est dans le fichier correction/R/create_data_list.R. Elle peut être importée dans l’environnement global grâce à la commande:
Voir la solution à cet exercice
import yaml
def create_data_list(source_file):
"""
Reads a YAML file and returns the contents as a dictionary.
Args:
source_file (str): The path to the YAML file.
Returns:
dict: The contents of the YAML file.
"""
with open(source_file, 'r') as file:
catalogue = yaml.safe_load(file)
return catalogueLa fonction-solution de cet exercice est dans le fichier correction/src/create_data_list.py.
Une fois que vous avez créé et rempli le fichier src/create_data_list.py, vous pouvez importer la fonction create_data_list dans l’environnement global grâce à la commande:
from src.create_data_list import create_data_listCet exemple simple vous montre ce que sera l’organisation finale de l’application: l’application web qui sera construite plus tard dans les fichiers server.R et ui.R () ou app.py () pourra facilement appeler des fonctions utilitaires stockées dans R/ ou dans src/. Cette organisation est très pratique car elle sépare l’application web stricto sensu des fonctions génériques de manipulation de données et contribue à rendre les codes faciles à comprendre et à maintenir.
3.4 Importer les premières bases
Nous pouvons maintenant utiliser cette fonction pour lister tous nos URL des sources.
urls <- create_data_list("sources.yml")urls = create_data_list("sources.yml")La carte leaflet que vous devriez avoir obtenue à la fin de l’exercice est la suivante:
leaflet(airports_location) %>%
addTiles() %>%
addMarkers(popup = ~Nom)A l’issue de l’exercice, le code centralisé dans le script R/import_data.R peut être importé via le code suivant
source("R/import_data.R")Vous pouvez initier un script nommé main.R avec les lignes suivante:
main.R
MONTHS_LIST = 1:12
# Load data ----------------------------------
urls <- create_data_list("./sources.yml")
pax_apt_all <- import_airport_data(unlist(urls$airports))
pax_cie_all <- import_compagnies_data(unlist(urls$compagnies))
pax_lsn_all <- import_liaisons_data(unlist(urls$liaisons))
airports_location <- st_read(urls$geojson$airport)en les faisant précéder de l’import des scripts que nous avons déjà créés dans le dossier R:
source("R/create_data_list.R")
source("R/import_data.R")
source("R/clean_dataframe.R")Une bonne pratique est de tester son script dans une session vierge. Cela amène à construire pas à pas une chaine plus reproductible. Pour cela,
- Aller dans les options de via
Tools > Global Optionset décocher la caseRestore .RData into workspace at setup - Redémarrer votre session via le menu
Session > Restart Rou le raccourci CTRL+SHIFT+F10 - Exécuter votre fichier
main.R. Vous devriez rencontrer des erreurs car nous n’avons pas géré les import de librairies dans ce script puisque notre session actuelle ne bénéficie plus des import antérieurs.
Une bonne pratique pour comprendre cette exigence de reproductibilité est d’itérativement ajouter les librairies utiles à mesure qu’on rencontre des erreurs (notre code étant très rapide à tourner, cette logique d’essai-erreur n’est pas très coûteuse). Si vous ne désirez pas faire ceci (dommage, c’est un bon exercice), vous pouvez trouver les imports de packages à faire pour que notre script soit reproductible.
L’environnement minimal de reproductibilité pour que le script main.R fonctionne
library(readr)
library(dplyr)
library(stringr)
library(sf)Ces librairies sont à écrire au début de main.R.
A l’issue de l’exercice, le code centralisé dans le script src/import_data.py peut être importé via le code suivant
import src.import_data as sid4 Exploration des données
4.1 Objectifs
Dans cette partie, vous allez exploiter les données pour produire trois valorisations qui seront ensuite intégrées dans l’application web:
- un graphique dynamique présentant le trafic pour un aéroport donné;
- un tableau HTML affichant des données sur le trafic;
- une carte des aéroports.
Une fois que ces valorisations seront prêtes, nous pourrons nous pencher sur leur intégration dans une application interactive.
4.2 Prérequis: créer le script main
Pour commencer, vous allez créer un fichier fichier main.R () ou main.py () à la racine du dépôt. Ensuite, vous pouvez y copier le code suivant.
library(readr)
library(dplyr)
library(stringr)
library(sf)
library(plotly)
source("correction/R/import_data.R")
source("correction/R/create_data_list.R")
source("correction/R/clean_dataframe.R")
source("correction/R/figures.R")
# Load data ----------------------------------
urls <- create_data_list("./sources.yml")
pax_apt_all <- import_airport_data(unlist(urls$airports))
pax_cie_all <- import_compagnies_data(unlist(urls$compagnies))
pax_lsn_all <- import_liaisons_data(unlist(urls$liaisons))
airports_location <- st_read(urls$geojson$airport)
liste_aeroports <- unique(pax_apt_all$apt)
default_airport <- liste_aeroports[1]import pandas as pd
import geopandas as gpd
import plotly.express as px
from plotnine import ggplot, geom_line, aes
import src.import_data as sid
from src.create_data_list import create_data_list
# Load data ----------------------------------
urls = create_data_list("./sources.yml")
pax_apt_all = sid.import_airport_data(urls['airports'].values())
pax_cie_all = sid.import_airport_data(urls['compagnies'].values())
pax_lsn_all = sid.import_airport_data(urls['liaisons'].values())
airports_location = gpd.read_file(
urls['geojson']['airport']
)
liste_aeroports = pax_apt_all['apt'].unique()
default_airport = liste_aeroports[0]4.3 Valorisation 1: Le trafic par aéroport
La première valorisation qui sera intégrée dans l’application web est un graphique décrivant le trafic aérien au niveau d’un aéroport. Nous allon d’abord créer une figure minimale (avec ggplot ou son équivalent plotnine) pour vérifier que nos données ont bien la dimension temporelle attendue. Cependant, comme Shiny est un système interactif, nous allons ensuite utiliser la librairie Plotly pour faire des figures dynamiques: il s’agit d’une librairie Javascript qui peut être appelée grâce à des librairies clientes en ou .
Exercice 3: Produire un graphique de fréquentation des aéroports
Dans le script main.R ou main.py:
- Créer une variable
traficégaleapt_pax_dep + apt_pax_tr + apt_pax_arr; - Ne conserver que les données relatives à l’aéroport
default_airport; - Créer une variable
datequi utilise les colonnesanetmois. Cette variable de date doit être au formatdate, pas au formatchr.
Enchaînement des opérations attendues à cette étape
library(readr)
library(dplyr)
library(stringr)
library(sf)
library(plotly)
source("correction/R/import_data.R")
source("correction/R/create_data_list.R")
source("correction/R/clean_dataframe.R")
source("correction/R/figures.R")
# Load data ----------------------------------
urls <- create_data_list("./sources.yml")
pax_apt_all <- import_airport_data(unlist(urls$airports))
pax_cie_all <- import_compagnies_data(unlist(urls$compagnies))
pax_lsn_all <- import_liaisons_data(unlist(urls$liaisons))
airports_location <- st_read(urls$geojson$airport)
liste_aeroports <- unique(pax_apt_all$apt)
default_airport <- liste_aeroports[1]
trafic_aeroports <- pax_apt_all %>%
mutate(trafic = apt_pax_dep + apt_pax_tr + apt_pax_arr) %>%
filter(apt %in% default_airport) %>%
mutate(
date = as.Date(paste(anmois, "01", sep=""), format = "%Y%m%d")
)import pandas as pd
import geopandas as gpd
import plotly.express as px
from plotnine import ggplot, geom_line, aes
import src.import_data as sid
from src.create_data_list import create_data_list
# Load data ----------------------------------
urls = create_data_list("./sources.yml")
pax_apt_all = sid.import_airport_data(urls['airports'].values())
pax_cie_all = sid.import_airport_data(urls['compagnies'].values())
pax_lsn_all = sid.import_airport_data(urls['liaisons'].values())
airports_location = gpd.read_file(
urls['geojson']['airport']
)
liste_aeroports = pax_apt_all['apt'].unique()
default_airport = liste_aeroports[0]
pax_apt_all['trafic'] = pax_apt_all['apt_pax_dep'] + \
pax_apt_all['apt_pax_tr'] + \
pax_apt_all['apt_pax_arr']
trafic_aeroports = (
pax_apt_all
.loc[pax_apt_all['apt'] == default_airport]
)
trafic_aeroports['date'] = pd.to_datetime(
trafic_aeroports['anmois'] + '01', format='%Y%m%d'
)- Faire une figure statique pour observer la dynamique des données:
- Pour les utilisateurs de , ce sera bien sûr avec
ggplot; - Pour les utilisateurs de , vous pouvez utiliser le module graphique de votre choix:
matplotlib,seabornouplotnine. Nous recommandons néanmoinsplotnine, la transposition en de la grammaire des graphiquesggplot.
Vous devriez obtenir une figure similaire à celle-ci:

Il est inutile d’aller plus loin sur la mise en forme de cette figure, car l’application interactive comportera in fine des figures dynamiques (qui se modifient en fonction des demandes de l’utilisateur) plutôt que des figures statiques comme celle que vous venez de produire.
- Nous allons maintenant faire une figure dynamique avec la librairie
Plotly. Pour cela, vous pouvez vous inspirer de cette page () ou celle-ci (). La figure que vous devriez avoir est la suivante:
Aide: le code pour générer la figure
figure_ggplot <- trafic_aeroports %>%
ggplot(.) + geom_line(aes(x = date, y = trafic))
figure_plotly <- plot_airport_line(trafic_aeroports, default_airport)figure_plotly = px.line(
trafic_aeroports, x="date", y="trafic",
text="apt_nom"
)
figure_plotly.update_traces(
mode="markers+lines", type = "scatter",
hovertemplate="<i>Aéroport:</i> %{text}<br>Trafic: %{y}"
)Le code complet pour répliquer cet exercice est donné ci-dessous.
Code de l’exercice
library(readr)
library(dplyr)
library(stringr)
library(sf)
library(plotly)
source("correction/R/import_data.R")
source("correction/R/create_data_list.R")
source("correction/R/clean_dataframe.R")
source("correction/R/figures.R")
# Load data ----------------------------------
urls <- create_data_list("./sources.yml")
pax_apt_all <- import_airport_data(unlist(urls$airports))
pax_cie_all <- import_compagnies_data(unlist(urls$compagnies))
pax_lsn_all <- import_liaisons_data(unlist(urls$liaisons))
airports_location <- st_read(urls$geojson$airport)
liste_aeroports <- unique(pax_apt_all$apt)
default_airport <- liste_aeroports[1]
trafic_aeroports <- pax_apt_all %>%
mutate(trafic = apt_pax_dep + apt_pax_tr + apt_pax_arr) %>%
filter(apt %in% default_airport) %>%
mutate(
date = as.Date(paste(anmois, "01", sep=""), format = "%Y%m%d")
)
# VALORISATIONS ----------------------------------------------
figure_ggplot <- trafic_aeroports %>%
ggplot(.) + geom_line(aes(x = date, y = trafic))
figure_plotly <- plot_airport_line(trafic_aeroports, default_airport)import pandas as pd
import geopandas as gpd
import plotly.express as px
from plotnine import ggplot, geom_line, aes
import src.import_data as sid
from src.create_data_list import create_data_list
# Load data ----------------------------------
urls = create_data_list("./sources.yml")
pax_apt_all = sid.import_airport_data(urls['airports'].values())
pax_cie_all = sid.import_airport_data(urls['compagnies'].values())
pax_lsn_all = sid.import_airport_data(urls['liaisons'].values())
airports_location = gpd.read_file(
urls['geojson']['airport']
)
liste_aeroports = pax_apt_all['apt'].unique()
default_airport = liste_aeroports[0]
pax_apt_all['trafic'] = pax_apt_all['apt_pax_dep'] + \
pax_apt_all['apt_pax_tr'] + \
pax_apt_all['apt_pax_arr']
trafic_aeroports = (
pax_apt_all
.loc[pax_apt_all['apt'] == default_airport]
)
trafic_aeroports['date'] = pd.to_datetime(
trafic_aeroports['anmois'] + '01', format='%Y%m%d'
)
# VALORISATIONS ----------------------------------------------
figure_ggplot = (
ggplot(trafic_aeroports) +
geom_line(aes(x = "date", y = "trafic"))
)
figure_plotly = px.line(
trafic_aeroports, x="date", y="trafic",
text="apt_nom"
)
figure_plotly.update_traces(
mode="markers+lines", type = "scatter",
hovertemplate="<i>Aéroport:</i> %{text}<br>Trafic: %{y}"
)Nous proposons de le transformer en fonction, ce sera plus simple à intégrer ultérieurement dans notre application
Fichier R/figures.R à l’issue de cet exercice
R/figures.R
plot_airport_line <- function(df, selected_airport){
trafic_aeroports <- df %>%
mutate(trafic = apt_pax_dep + apt_pax_tr + apt_pax_arr) %>%
filter(apt %in% selected_airport) %>%
mutate(
date = as.Date(paste(anmois, "01", sep=""), format = "%Y%m%d")
)
figure_plotly <- trafic_aeroports %>%
plot_ly(
x = ~date, y = ~trafic,
text = ~apt_nom,
hovertemplate = paste("<i>Aéroport:</i> %{text}<br>Trafic: %{y}") ,
type = 'scatter', mode = 'lines+markers')
return(figure_plotly)
}Par la suite, nous pouvons ajouter la ligne suivante au début de notre fichier main.R:
source("R/figures.R")et utiliser cette fonction à la fin du fichier.
Par la suite, nous pouvons ajouter la ligne suivante au début de notre fichier main.py:
from src.figures import plot_airport_lineet utiliser cette fonction à la fin du fichier.
Fichier main.py à l’issue de cet exercice
main.py
import pandas as pd
import geopandas as gpd
import plotly.express as px
from plotnine import ggplot, geom_line, aes
import src.import_data as sid
from src.create_data_list import create_data_list
# Load data ----------------------------------
urls = create_data_list("./sources.yml")
pax_apt_all = sid.import_airport_data(urls['airports'].values())
pax_cie_all = sid.import_airport_data(urls['compagnies'].values())
pax_lsn_all = sid.import_airport_data(urls['liaisons'].values())
airports_location = gpd.read_file(
urls['geojson']['airport']
)
liste_aeroports = pax_apt_all['apt'].unique()
default_airport = liste_aeroports[0]
# OBJETS NECESSAIRES A L'APPLICATION ------------------------
pax_apt_all['trafic'] = pax_apt_all['apt_pax_dep'] + \
pax_apt_all['apt_pax_tr'] + \
pax_apt_all['apt_pax_arr']
trafic_aeroports = (
pax_apt_all
.loc[pax_apt_all['apt'] == default_airport]
)
trafic_aeroports['date'] = pd.to_datetime(
trafic_aeroports['anmois'] + '01', format='%Y%m%d'
)
# VALORISATIONS ----------------------------------------------
from src.figures import plot_airport_line
figure_plotly = plot_airport_line(trafic_aeroports, default_airport)4.4 Valorisation 2: Tableau HTML pour afficher des données
La deuxième valorisation qui sera intégrée dans l’application web est un tableau permettant de visualiser certaines données directement dans le dashboard. Il existe plusieurs packages pour faire cela, que ce soit en ou .
L’écosystème le plus complet pour construire ce tableau est développé par Posit et est quasi équivalent qu’on fasse du ou du (il est plus complet en car plus ancien dans ce langage). Il s’agit du package GT () ou Great Tables (). En peu de temps, ces packages sont devenus incontournables et proposent des fonctionnalités bien plus complètes que les solutions qui existaient par le passé, notamment DT.
Pour le prochain exercice, vous pourrez utiliser les objets suivants. Copiez-les à la fin de votre script main.
YEARS_LIST <- as.character(2018:2022)
MONTHS_LIST <- 1:12YEARS_LIST = [str(year) for year in range(2018, 2023)]
MONTHS_LIST = list(range(1, 13))Voici une proposition de script main.R (resp. main.py) à l’issue de cet exercice
Code de l’exercice
library(readr)
library(dplyr)
library(stringr)
library(sf)
library(ggplot2)
library(plotly)
library(leaflet)
source("correction/R/import_data.R")
source("correction/R/create_data_list.R")
source("correction/R/clean_dataframe.R")
source("correction/R/divers_functions.R")
source("correction/R/figures.R")
YEARS_LIST <- as.character(2018:2022)
MONTHS_LIST <- 1:12
year <- YEARS_LIST[1]
month <- MONTHS_LIST[1]
# Load data ----------------------------------
urls <- create_data_list("./sources.yml")
pax_apt_all <- import_airport_data(unlist(urls$airports))
pax_cie_all <- import_compagnies_data(unlist(urls$compagnies))
pax_lsn_all <- import_liaisons_data(unlist(urls$liaisons))
airports_location <- st_read(urls$geojson$airport)
liste_aeroports <- unique(pax_apt_all$apt)
default_airport <- liste_aeroports[1]
# OBJETS NECESSAIRES A L'APPLICATION ------------------------
trafic_aeroports <- pax_apt_all %>%
mutate(trafic = apt_pax_dep + apt_pax_tr + apt_pax_arr) %>%
filter(apt %in% default_airport) %>%
mutate(
date = as.Date(paste(anmois, "01", sep=""), format = "%Y%m%d")
)
stats_aeroports <- summary_stat_airport(
create_data_from_input(pax_apt_all, year, month)
)
# VALORISATIONS ----------------------------------------------
figure_plotly <- plot_airport_line(trafic_aeroports,default_airport)
Code de l’exercice
import pandas as pd
import geopandas as gpd
import plotly.express as px
from plotnine import ggplot, geom_line, aes
import src.import_data as sid
from src.create_data_list import create_data_list
from src.divers_functions import (
create_data_from_input,
summary_stat_airport
)
YEARS_LIST = [str(year) for year in range(2018, 2023)]
MONTHS_LIST = list(range(1, 13))
year = YEARS_LIST[0]
month = MONTHS_LIST[0]
# Load data ----------------------------------
urls = create_data_list("./sources.yml")
pax_apt_all = sid.import_airport_data(urls['airports'].values())
pax_cie_all = sid.import_airport_data(urls['compagnies'].values())
pax_lsn_all = sid.import_airport_data(urls['liaisons'].values())
airports_location = gpd.read_file(
urls['geojson']['airport']
)
liste_aeroports = pax_apt_all['apt'].unique()
default_airport = liste_aeroports[0]
# OBJETS NECESSAIRES A L'APPLICATION ------------------------
pax_apt_all['trafic'] = pax_apt_all['apt_pax_dep'] + \
pax_apt_all['apt_pax_tr'] + \
pax_apt_all['apt_pax_arr']
trafic_aeroports = (
pax_apt_all
.loc[pax_apt_all['apt'] == default_airport]
)
trafic_aeroports['date'] = pd.to_datetime(
trafic_aeroports['anmois'] + '01', format='%Y%m%d'
)
# VALORISATIONS ----------------------------------------------
from src.figures import plot_airport_line
figure_plotly = plot_airport_line(trafic_aeroports, default_airport)Nous avons maintenant tous les ingrédients pour faire un tableau de statistiques descriptives lisibles et esthétiques. Avant de créer cette table, nous allons créer une colonne supplémentaire:
stats_aeroports_table <- stats_aeroports %>%
mutate(name_clean = paste0(str_to_sentence(apt_nom), " _(", apt, ")_")
) %>%
select(name_clean, everything())stats_aeroports['name_clean'] = stats_aeroports['apt_nom'].str.title() + " _(" + stats_aeroports['apt'] + ")_"
stats_aeroports = stats_aeroports[ ['name_clean'] + [ col for col in stats_aeroports.columns if col != 'name_clean' ] ]Celle-ci nous permettra, une fois mise en forme, d’avoir une colonne plus esthétique.
Les réponses aux différentes questions sont données de manière successives ci-dessous. La table finale, obtenue à l’issue de l’exercice est la suivante:
Réponse question 1
library(gt)
table_aeroports <- gt(stats_aeroports_table)
table_aeroportsRéponse question 2
table_aeroports <- table_aeroports %>%
cols_hide(columns = starts_with("apt"))
table_aeroportsRéponse question 3
table_aeroports <- table_aeroports %>%
fmt_number(columns = starts_with("pax"), suffixing = TRUE)
table_aeroportsRéponse question 4
table_aeroports <- table_aeroports %>%
fmt_markdown(columns = "name_clean")
table_aeroportsRéponse question 5
table_aeroports <- table_aeroports %>%
cols_label(
name_clean = md("**Aéroport**"),
paxdep = md("**Départs**"),
paxarr = md("**Arrivée**"),
paxtra = md("**Transit**")
) %>%
tab_header(
title = md("**Statistiques de fréquentation**"),
subtitle = md("Classement des aéroports")
) %>%
tab_style(
style = cell_fill(color = "powderblue"),
locations = cells_title()
) %>%
tab_source_note(source_note = md("_Source: DGAC, à partir des données sur data.gouv.fr_"))
table_aeroportsRéponse question 6
table_aeroports <- table_aeroports %>%
opt_interactive()
table_aeroportsStatistiques de fréquentation
Classement des aéroports
Source: DGAC, à partir des données sur data.gouv.fr
Solution suggérée pour l’exercice ci-dessus
table_gt = (
GT(stats_aeroports.head(15))
.cols_hide(columns = stats_aeroports.filter(like = "apt").columns.tolist())
.fmt_number(columns = stats_aeroports.filter(like = "pax").columns.tolist(), compact = True)
.fmt_markdown(columns = "name_clean")
.cols_label(
name_clean = md("**Aéroport**"),
paxdep = md("**Départs**"),
paxarr = md("**Arrivée**"),
paxtr = md("**Transit**")
)
.tab_header(
title = md("**Statistiques de fréquentation**"),
subtitle = md("Classement des aéroports")
)
.tab_source_note(
source_note = md("_Source: DGAC, à partir des données sur data.gouv.fr_")
)
)Nous proposons de transformer ce code en fonction, cela facilitera l’utilisation ultérieure de celui-ci dans notre application.
Code de R/tables.R
R/tables.R
create_table_airports <- function(stats_aeroports){
stats_aeroports_table <- stats_aeroports %>%
mutate(name_clean = paste0(str_to_sentence(apt_nom), " _(", apt, ")_")
) %>%
select(name_clean, everything())
table_aeroports <- gt(stats_aeroports_table)
table_aeroports <- table_aeroports %>%
cols_hide(columns = starts_with("apt"))
table_aeroports <- table_aeroports %>%
fmt_number(columns = starts_with("pax"), suffixing = TRUE)
table_aeroports <- table_aeroports %>%
fmt_markdown(columns = "name_clean")
table_aeroports <- table_aeroports %>%
cols_label(
name_clean = md("**Aéroport**"),
paxdep = md("**Départs**"),
paxarr = md("**Arrivée**"),
paxtra = md("**Transit**")
) %>%
tab_header(
title = md("**Statistiques de fréquentation**"),
subtitle = md("Classement des aéroports")
) %>%
tab_style(
style = cell_fill(color = "powderblue"),
locations = cells_title()
) %>%
tab_source_note(source_note = md("_Source: DGAC, à partir des données sur data.gouv.fr_"))
table_aeroports <- table_aeroports %>%
opt_interactive()
return(table_aeroports)
}
Code de main.R
main.R
library(readr)
library(dplyr)
library(stringr)
library(sf)
library(ggplot2)
library(plotly)
library(gt)
library(leaflet)
source("correction/R/import_data.R")
source("correction/R/create_data_list.R")
source("correction/R/clean_dataframe.R")
source("correction/R/divers_functions.R")
source("correction/R/tables.R")
source("correction/R/figures.R")
YEARS_LIST <- as.character(2018:2022)
MONTHS_LIST <- 1:12
year <- YEARS_LIST[1]
month <- MONTHS_LIST[1]
# Load data ----------------------------------
urls <- create_data_list("./sources.yml")
pax_apt_all <- import_airport_data(unlist(urls$airports))
pax_cie_all <- import_compagnies_data(unlist(urls$compagnies))
pax_lsn_all <- import_liaisons_data(unlist(urls$liaisons))
airports_location <- st_read(urls$geojson$airport)
liste_aeroports <- unique(pax_apt_all$apt)
default_airport <- liste_aeroports[1]
# OBJETS NECESSAIRES A L'APPLICATION ------------------------
trafic_aeroports <- pax_apt_all %>%
mutate(trafic = apt_pax_dep + apt_pax_tr + apt_pax_arr) %>%
filter(apt %in% default_airport) %>%
mutate(
date = as.Date(paste(anmois, "01", sep=""), format = "%Y%m%d")
)
stats_aeroports <- summary_stat_airport(
create_data_from_input(pax_apt_all, year, month)
)
# VALORISATIONS ----------------------------------------------
figure_plotly <- plot_airport_line(trafic_aeroports,default_airport)
table_airports <- create_table_airports(stats_aeroports)
Code de src/tables.py
stc/tables.py
from great_tables import GT, md
def create_table_airports(stats_aeroports):
stats_aeroports['name_clean'] = stats_aeroports['apt_nom'].str.title() + " _(" + stats_aeroports['apt'] + ")_"
stats_aeroports = stats_aeroports[ ['name_clean'] + [ col for col in stats_aeroports.columns if col != 'name_clean' ] ]
table_gt = (
GT(stats_aeroports.head(15))
.cols_hide(columns = stats_aeroports.filter(like = "apt").columns.tolist())
.fmt_number(columns = stats_aeroports.filter(like = "pax").columns.tolist(), compact = True)
.fmt_markdown(columns = "name_clean")
.cols_label(
name_clean = md("**Aéroport**"),
paxdep = md("**Départs**"),
paxarr = md("**Arrivée**"),
paxtr = md("**Transit**")
)
.tab_header(
title = md("**Statistiques de fréquentation**"),
subtitle = md("Classement des aéroports")
)
.tab_source_note(source_note = md("_Source: DGAC, à partir des données sur data.gouv.fr_"))
)
return table_gt
Code de main.py
main.py
import pandas as pd
import geopandas as gpd
import plotly.express as px
import src.import_data as sid
from src.create_data_list import create_data_list
from src.divers_functions import (
create_data_from_input,
summary_stat_airport
)
from src.tables import create_table_airports
YEARS_LIST = [str(year) for year in range(2018, 2023)]
MONTHS_LIST = list(range(1, 13))
year = YEARS_LIST[0]
month = MONTHS_LIST[0]
# Load data ----------------------------------
urls = create_data_list("./sources.yml")
pax_apt_all = sid.import_airport_data(urls['airports'].values())
pax_cie_all = sid.import_airport_data(urls['compagnies'].values())
pax_lsn_all = sid.import_airport_data(urls['liaisons'].values())
airports_location = gpd.read_file(
urls['geojson']['airport']
)
liste_aeroports = pax_apt_all['apt'].unique()
default_airport = liste_aeroports[0]
# OBJETS NECESSAIRES A L'APPLICATION ------------------------
pax_apt_all['trafic'] = pax_apt_all['apt_pax_dep'] + \
pax_apt_all['apt_pax_tr'] + \
pax_apt_all['apt_pax_arr']
trafic_aeroports = (
pax_apt_all
.loc[pax_apt_all['apt'] == default_airport]
)
trafic_aeroports['date'] = pd.to_datetime(
trafic_aeroports['anmois'] + '01', format='%Y%m%d'
)
stats_aeroports = summary_stat_airport(
create_data_from_input(pax_apt_all, year, month)
)
# VALORISATIONS ----------------------------------------------
from src.figures import plot_airport_line
figure_plotly = plot_airport_line(trafic_aeroports, default_airport)
table_airports = create_table_airports(stats_aeroports)4.5 Valorisation 3: Carte des aéroports
La troisième valorisation qui sera intégrée dans l’application web est une carte interactive du trafic de nos aéroports. Cette carte va être assez basique. Si vous désirez mettre en oeuvre des visualisations plus complexes, vous pouvez tout à fait le faire.
Pour cet exercice, nous allons fixer une date pour prototyper notre code. Cela nous facilitera la transformation ultérieure en fonction.
month <- 1
year <- 2019Voici également une palette de couleurs qui sera utile à la fin de l’exercice.
palette <- c("green", "blue", "red")month = 1
year = 2019Voici également une palette de couleurs qui sera utile à la fin de l’exercice.
palette = c("green", "blue", "red")Question 1
trafic_date <- pax_apt_all %>%
mutate(
date = as.Date(paste(anmois, "01", sep=""), format = "%Y%m%d")
) %>%
filter(mois == month, an == year)
trafic_aeroports <- airports_location %>%
inner_join(trafic_date, by = c("Code.OACI" = "apt"))Question 2
library(leaflet)
leaflet(trafic_aeroports) %>% addTiles() %>%
addMarkers(popup = ~paste0(Nom, ": ", trafic)) Question 3
trafic_aeroports <- trafic_aeroports %>%
mutate(
volume = ntile(trafic, 3)
) %>%
mutate(
color = palette[volume]
)Question 4
icons <- awesomeIcons(
icon = 'plane',
iconColor = 'black',
library = 'fa',
markerColor = trafic_aeroports$color
)
carte_interactive <- leaflet(trafic_aeroports) %>% addTiles() %>%
addAwesomeMarkers(
icon=icons[],
label=~paste0(Nom, "", " (",Code.OACI, ") : ", trafic, " voyageurs")
)Voir la solution de l’exercice suivant
Comme précédemment, nous proposons de transformer la production de cette carte en fonction, cela nous permettra d’avoir une application légère. Là encore c’est un exercice optionnel mais intéressant à faire pour découvrir la logique de la programmation fonctionnelle.
Code de R/figures.R à reprendre
R/figures.R (fin du fichier)
map_leaflet_airport <- function(df, airports_location, months, years){
palette <- c("green", "blue", "red")
trafic_date <- df %>%
mutate(
date = as.Date(paste(anmois, "01", sep=""), format = "%Y%m%d")
) %>%
filter(mois == months, an == years)
trafic_aeroports <- airports_location %>%
select(Code.OACI, Nom, geometry) %>%
inner_join(trafic_date, by = c("Code.OACI" = "apt"))
trafic_aeroports <- trafic_aeroports %>%
mutate(
trafic = apt_pax_dep + apt_pax_tr + apt_pax_arr,
volume = ntile(trafic, 3)
) %>%
mutate(
color = palette[volume]
)
icons <- awesomeIcons(
icon = 'plane',
iconColor = 'black',
library = 'fa',
markerColor = trafic_aeroports$color
)
carte_interactive <- leaflet(trafic_aeroports) %>% addTiles() %>%
addAwesomeMarkers(
icon=icons[],
label=~paste0(Nom, "", " (",Code.OACI, ") : ", trafic, " voyageurs")
)
return(carte_interactive)
}
Code de main.R à reprendre
main.R
library(readr)
library(dplyr)
library(stringr)
library(sf)
library(ggplot2)
library(plotly)
library(gt)
library(leaflet)
source("correction/R/import_data.R")
source("correction/R/create_data_list.R")
source("correction/R/clean_dataframe.R")
source("correction/R/divers_functions.R")
source("correction/R/tables.R")
source("correction/R/figures.R")
YEARS_LIST <- as.character(2018:2022)
MONTHS_LIST <- 1:12
year <- YEARS_LIST[1]
month <- MONTHS_LIST[1]
# Load data ----------------------------------
urls <- create_data_list("./sources.yml")
pax_apt_all <- import_airport_data(unlist(urls$airports))
pax_cie_all <- import_compagnies_data(unlist(urls$compagnies))
pax_lsn_all <- import_liaisons_data(unlist(urls$liaisons))
airports_location <- st_read(urls$geojson$airport)
liste_aeroports <- unique(pax_apt_all$apt)
default_airport <- liste_aeroports[1]
# OBJETS NECESSAIRES A L'APPLICATION ------------------------
trafic_aeroports <- pax_apt_all %>%
mutate(trafic = apt_pax_dep + apt_pax_tr + apt_pax_arr) %>%
filter(apt %in% default_airport) %>%
mutate(
date = as.Date(paste(anmois, "01", sep=""), format = "%Y%m%d")
)
stats_aeroports <- summary_stat_airport(
create_data_from_input(pax_apt_all, year, month)
)
stats_liaisons <- summary_stat_liaisons(
create_data_from_input(pax_lsn_all, year, month)
)
# VALORISATIONS ----------------------------------------------
figure_plotly <- plot_airport_line(trafic_aeroports,default_airport)
table_airports <- create_table_airports(stats_aeroports)
carte_interactive <- map_leaflet_airport(
pax_apt_all, airports_location,
month, year
)
Code de src/figures.py à reprendre
src/figures.py (fin du fichier)
Code de main.py à reprendre
main.py
import pandas as pd
import geopandas as gpd
import plotly.express as px
import src.import_data as sid
from src.create_data_list import create_data_list
from src.divers_functions import (
create_data_from_input,
summary_stat_airport
)
from src.tables import create_table_airports
from src.figures import plot_airport_line, map_leaflet_airport
YEARS_LIST = [str(year) for year in range(2018, 2023)]
MONTHS_LIST = list(range(1, 13))
year = YEARS_LIST[0]
month = MONTHS_LIST[0]
# Load data ----------------------------------
urls = create_data_list("./sources.yml")
pax_apt_all = sid.import_airport_data(urls['airports'].values())
pax_cie_all = sid.import_airport_data(urls['compagnies'].values())
pax_lsn_all = sid.import_airport_data(urls['liaisons'].values())
airports_location = gpd.read_file(
urls['geojson']['airport']
)
liste_aeroports = pax_apt_all['apt'].unique()
default_airport = liste_aeroports[0]
# OBJETS NECESSAIRES A L'APPLICATION ------------------------
pax_apt_all['trafic'] = pax_apt_all['apt_pax_dep'] + \
pax_apt_all['apt_pax_tr'] + \
pax_apt_all['apt_pax_arr']
trafic_aeroports = (
pax_apt_all
.loc[pax_apt_all['apt'] == default_airport]
)
trafic_aeroports['date'] = pd.to_datetime(
trafic_aeroports['anmois'] + '01', format='%Y%m%d'
)
stats_aeroports = summary_stat_airport(
create_data_from_input(pax_apt_all, year, month)
)
# VALORISATIONS ----------------------------------------------
figure_plotly = plot_airport_line(trafic_aeroports, default_airport)
table_airports = create_table_airports(stats_aeroports)
carte_interactive = map_leaflet_airport(
pax_apt_all, airports_location,
month, year
)5 Création de l’application
Maintenant tous les ingrédients sont là pour transformer cette chaîne en application interactive. L’architecture de notre application sera la suivante :

Comme toute application web, Shiny ou Streamlit reposent sur deux piliers :
- l’interface utilisateur (UI) qui présente au navigateur des actions possibles et affiche des output adaptés;
- le serveur qui répond à ces actions de l’utilisateur, produit les outputs et les envoie à l’interface.
Shiny ou Streamlit fonctionnent un peu différemment dans la manière de faire interagir ces deux éléments:
Shinynécessite deux fichiers: un pour l’interface graphique (ui.R) et l’autre pour le serveur (server.R). L’aller-retour entre ces deux fichiers se fait par des objets communs, les inputs du serveur (qui sont les éléments de l’interface graphique) et les outputs du serveur (le résultat des calculs, à afficher sur la page web) ;Streamlitpropose de tout mettre dans un fichier. Les éléments de l’interface graphique sont à la fois des widgets qui seront représentés sur la page et des objetsPythonayant une valeur correspondant à celle sélectionnée sur la page.
Exercice 6: Créer la structure de l’application
- Créer le fichier
global.Rà partir demain.Ren ne conservant que les lignes jusqu’à la création (incluse); de l’objettrafic_aeroports.
Le fichier global.R attendu
# Environment ----------------------------------
library(readr)
library(dplyr)
library(lubridate)
library(stringr)
library(sf)
library(ggplot2)
library(plotly)
library(gt)
library(leaflet)
library(bslib)
source("correction/R/import_data.R")
source("correction/R/create_data_list.R")
source("correction/R/clean_dataframe.R")
source("correction/R/divers_functions.R")
source("correction/R/tables.R")
source("correction/R/figures.R")
# Global variables ---------------------------
YEARS_LIST <- 2018:2022
MONTHS_LIST = 1:12
# Load data ----------------------------------
urls <- create_data_list("./sources.yml")
pax_apt_all <- import_airport_data(unlist(urls$airports))
pax_cie_all <- import_compagnies_data(unlist(urls$compagnies))
pax_lsn_all <- import_liaisons_data(unlist(urls$liaisons))
airports_location <- st_read(urls$geojson$airport)
liste_aeroports <- unique(pax_apt_all$apt)
default_airport <- liste_aeroports[1]
# OBJETS NECESSAIRES A L'APPLICATION ------------------------
trafic_aeroports <- pax_apt_all %>%
mutate(trafic = apt_pax_dep + apt_pax_tr + apt_pax_arr) %>%
filter(apt %in% default_airport) %>%
mutate(
date = as.Date(paste(anmois, "01", sep=""), format = "%Y%m%d")
)L’objectif de la suite de l’exercice est de comprendre comment fonctionne une application. Celle-ci sera enrichie ensuite de nos productions graphiques.
Créer les fichiers ui.R et server.R à partir des modèles ci-dessous
Code de ui.R à reprendre
ui.R
main_color <- "black"
input_date <- shinyWidgets::airDatepickerInput(
"date",
label = "Mois choisi",
value = "2019-01-01",
view = "months",
minView = "months",
minDate = "2018-01-01",
maxDate = "2022-12-01",
dateFormat = "MMMM yyyy",
language = "fr"
)
input_airport <- selectInput(
"select",
"Aéroport choisi",
choices = liste_aeroports,
selected = default_airport
)
ui <- page_navbar(
title = "Tableau de bord des aéroports français",
bg = main_color,
inverse = TRUE,
header = em("Projet issu du funathon 2024, organisé par l'Insee et la DGAC"),
layout_columns(
card(
input_date,
textOutput("date1")
# table viendra ici
),
layout_columns(
card(
# carte viendra ici
textOutput("date2")
),
card(card_header("Fréquentation d'un aéroport", class = "bg-dark"),
input_airport,
textOutput("airport")
# figure viendra ici
),
col_widths = c(12,12)
),
cols_widths = c(12,12,12)
)
)
Code de server.R à reprendre
server.R
function(input, output) {
output$date1 <- renderText(input$date)
output$date2 <- renderText(input$date)
output$airport <- renderText(input$select)
}Lancer l’application en lançant shiny::runApp() depuis la console R. Si firefox affiche un message de blocage de l’ouverture d’une fenêtre, autoriser celle-ci.
- Observer votre console, notamment les messages lors du lancement de l’application
- Jouer avec les inputs et observer la manière dont l’affichage s’ajuste
Maintenant, se pencher sur le code source et observer l’aller-retour entre les objets du script ui.R et server.R.
Tuer l’application avec le bouton stop de la console.
- Renommer le fichier
main.pyenapp.py - Vous devriez avoir besoin des éléments suivants dans l’application, à ajouter en début de script:
import streamlit as st
import streamlit.components.v1 as components
from streamlit_folium import st_foliumGlobalement, le fichier app.py va avoir la structure suivante:
- Import des packages ;
- Import et restructuration des données ;
- Création de la mise en page (layout) de l’application ;
- Création des inputs (les sélecteurs) et utilisation pour produire nos valorisations graphiques.
Après la dernière ligne de création de base de données, créer le layout de l’application
# Streamlit Layout -------------------------------------- st.set_page_config( page_title="Tableau de bord des aéroports français", layout="wide", page_icon="✈️" ) col1, col2 = st.columns(2)Pour le moment, nous proposons de ne pas se préoccuper des deux colonnes, nous remettrons en forme ultérieurement notre application.
Créer un objet
selected_dateà partir dest.date_inputayant pour étiquette “Mois choisi” et prenant par défaut la valeurpd.to_datetime("2019-01-01"). L’utiliser pour créer des objetsyearetmonth.Utiliser ces objets
yearetmonth, qui sont donc maintenant réactifs et non plus figés, pour créerstats_aeroports, puistable_airports. Pour que la table rende bien sur l’application, vous pouvez ajouter, par rapport à précédemment, la méthodeas_raw_htmlaprès l’application de la fonctioncreate_table_airports. On va supposer que cette table HTML s’appelletable_airports.Pour intégrer cette table dans l’application, insérer le code suivant dans
app.py:components.html(table_airports, height=600)Faire tourner l’application avec la commande suivante dans un terminal:
streamlit run app.py --server.port=5000 --server.address=0.0.0.0La commande suivante devrait s’afficher sur votre terminal:
Collecting usage statistics. To deactivate, set browser.gatherUsageStats to false. You can now view your Streamlit app in your browser. URL: http://0.0.0.0:5000Et
VSCodedevrait vous proposer d’ouvrir cette fenêtre. Ne le faites pas car une redirection plus persistante vers le localhost de votre service (http://0.0.0.0:5000) va être nécessaire.Retourner sur la page “Mes services” du SSPCloud et cliquer sur le lien du port personnalisé

Observer la page web et l’évolution de votre console.
Stopper votre application avec CTRL+C. Ajouter le code suivant à votre application:
st.subheader("Carte des aéroports") carte_interactive = map_leaflet_airport( pax_apt_all, airports_location, month, year ) st_folium(carte_interactive, height=300) # Line Plot Output st.subheader("Fréquentation d'un aéroport") selected_airport = st.selectbox( "Aéroport choisi", options=liste_aeroports, index=0 ) figure_plotly = plot_airport_line(pax_apt_all, selected_airport) st.plotly_chart(figure_plotly)Exécuter à nouveau la commande
streamlit runci-dessus. Observer l’évolution de votre application et jouez avec les paramètres de celle-ci. Ajouter, à la fin de celle-ci, unprint(year). Jouer avec le widget de date dans votre application web et observer la valeur affichée dans l’application et dans votre terminal. Comprenez-vous pourquoi l’année ne s’affiche pas dans la page web mais dans la console ?
Explication
Comme nous l’avons évoqué précédemment, il convient de distinguer l’interface utilisateur du serveur. Les commandes Python sont exécutées au niveau du serveur, en l’occurrence votre terminal Python dans VSCode. Pour afficher des éléments dans l’interface utilisateur, il faut indiquer à Streamlit de les remonter, par exemple par le biais de st.plotly_chart. Sinon, elles restent au niveau du serveur.
En l’occurrence, le print est une commande qui permet d’afficher la valeur au niveau de la console Python. Mais on ne dit pas à Streamlit d’afficher cette valeur sur la page web (l’interface utilisateur).
A noter que cette distinction n’est pas propre à Streamlit. Dans le monde du développement JavaScript, on distingue aussi l’affichage du widget (sa vue) de sa valeur réelle. Pour s’y retrouver lorsqu’ils développent, les développeurs web affichent souvent dans la console Javascript la valeur de l’objet par le biais de console.log. Vous pouvez d’ailleurs retrouver cette console JavaScript dans vos outils de développement de votre navigateur (par exemple sur Firefox par le biais de CTRL+MAJ+K). Si vous voyez des valeurs s’afficher, c’est que les développeurs du site ont utilisé des console.log de temps en temps.
6 Partager cette application : une ouverture vers la mise en production
Difficulté technique de cette partie
Cette partie est plus avancée car elle fait appel à des notions techniques assez complexes dont certaines sortent, à proprement parler, du champ de compétences des data scientists.
Il est néanmoins fort utile de découvrir celles-ci afin d’être autonome dans la mise à disposition de ses applications, un format de valorisation de plus en plus commun.
Dans cette partie, on propose de déployer l’application sur le SSPCloud et de la rendre accessible depuis Internet. L’exercice constitue une introduction à la mise en production d’applications dans un environnement cloud. Pour aller plus loin, n’hésitez pas à consulter ce cours de 3e année de l’ENSAE.
6.1 Conteneurisation de l’application
Pour déployer son application, la première étape consiste à la conteneuriser, ce qui signifie la mettre dans une sorte de boîte virtuelle contenant tout ce dont l’application a besoin pour fonctionner. Le conteneur sépare l’application de son environnement extérieur, ce qui permet d’éviter les conflits avec d’autres applications ou dépendances sur le même système. Puisque le conteneur contient tout ce dont l’application a besoin (comme les bibliothèques et les dépendances), l’application peut être déplacée et exécutée sur n’importe quel système qui supporte les conteneurs, sans se soucier des différences entre ces systèmes.
Ainsi, conteneuriser une application permet de la rendre plus facile à déployer, plus fiable et plus portable (en utilisant efficacement les ressources du système). Docker est un outil populaire pour créer et gérer des conteneurs. Le fichier Dockerfile contient le code nécessaire pour construire l’image Docker de l’application finale située dans le répertoire correction. Vous pouvez consulter la documentation Docker pour tenter de comprendre comment l’image est construite.
Nous ne vous demandons pas de construire l’image vous-même, l’image est déjà publique sur Dockerhub et peut-être utilisée pour déployer l’application. Néanmoins, il est intéressant, pour comprendre la logique de fonctionnement de Docker, de regarder la recette de construction de cette image
Dockerfile
FROM inseefrlab/onyxia-rstudio:r4.3.2-2024.02.13
# Add files necessary for the running app
ADD correction/global.R .
ADD correction/ui.R .
ADD correction/server.R .
ADD correction/sources.yml .
COPY correction/R R/
ADD renv.lock .
ADD renv .
# Expose port where shiny app will broadcast
ARG SHINY_PORT=3838
EXPOSE $SHINY_PORT
RUN echo "local({options(shiny.port = ${SHINY_PORT}, shiny.host = '0.0.0.0')})" >> /usr/local/lib/R/etc/Rprofile.site
RUN Rscript -e "renv::restore()"
# Endpoint
CMD ["Rscript", "-e", "shiny::runApp()"]Dockerfile
FROM inseefrlab/onyxia-jupyter-python:py3.10.9
# Add files necessary for the running app
ADD correction/app.py .
ADD correction/sources.yml .
ADD requirements.txt .
# Move directories to the project root
COPY correction/src src/
COPY correction/.streamlit .streamlit/
# Install dependencies
RUN pip install -r requirements.txt
EXPOSE 8000
CMD ["streamlit", "run", "app.py", "--server.port=8000", "--server.address=0.0.0.0"]Les principales étapes de cette construction d’image sont les suivantes :
- 1️⃣ On part d’une image de base qui correspond à celle dans laquelle on a développé notre application et qui fonctionnait. On pourrait partir d’un environnement plus minimaliste (une machine Linux avec seulement
Rinstallé, comme les imagesrocker) mais nous aurions peut-être à installer des librairies système en plus par un processus d’essai-erreur coûteux en temps.
Partie du Dockerfile en question
Dockerfile
FROM inseefrlab/onyxia-rstudio:r4.3.2-2024.02.13
Partie du Dockerfile en question
Dockerfile
FROM inseefrlab/onyxia-jupyter-python:py3.10.9- 2️⃣ On ajoute dans le conteneur les fichiers indispensables au fonctionnement de notre application. Le conteneur, par défaut, n’a pas les fichiers de notre projet, on doit donc dire à
Dockerquels fichiers on désire avoir dans notre application.
Partie du Dockerfile en question
Dockerfile
# Add files necessary for the running app
ADD correction/global.R .
ADD correction/ui.R .
ADD correction/server.R .
ADD correction/sources.yml .
COPY correction/R R/
ADD renv.lock .
ADD renv .
Partie du Dockerfile en question
Dockerfile
# Add files necessary for the running app
ADD correction/app.py .
ADD correction/sources.yml .
ADD requirements.txt .
# Move directories to the project root
COPY correction/src src/
COPY correction/.streamlit .streamlit/- 3️⃣ On définit des paramètres sur le routage de notre application dans le conteneur (seulement nécessaire pour la solution ). Ces paramètres nous seront utiles ultérieurement, lors du déploiement.
Partie du Dockerfile en question
Dockerfile
# Expose port where shiny app will broadcast
ARG SHINY_PORT=3838
EXPOSE $SHINY_PORT
RUN echo "local({options(shiny.port = ${SHINY_PORT}, shiny.host = '0.0.0.0')})" >> /usr/local/lib/R/etc/Rprofile.siteCette étape n’est pas nécessaire.
- 4️⃣ On restaure l’environnement avec
renv() oupip(). De cette manière, on est assuré que l’application aura le même environnement que celui que nous avons prévu lors de la phase de développement.
Partie du Dockerfile en question
Dockerfile
RUN Rscript -e "renv::restore()"
Partie du Dockerfile en question
Dockerfile
# Install dependencies
RUN pip install -r requirements.txt- 5️⃣ On définit la commande qui sera exécutée au lancement de notre application. En l’occurrence, c’est une ligne de commande Linux pour lancer l’application
ShinyouStreamlit
Partie du Dockerfile en question
Dockerfile
# Endpoint
CMD ["Rscript", "-e", "shiny::runApp()"]
Partie du Dockerfile en question
Dockerfile
EXPOSE 8000
CMD ["streamlit", "run", "app.py", "--server.port=8000", "--server.address=0.0.0.0"]Si le Dockerfile est la recette pour créer notre application, où se trouve la cuisine pour préparer notre plat ? En général, on passe par des systèmes d’intégration continue, des serveurs mis à disposition en complément de forges Git pour tester le Dockerfile. Pour en savoir plus sur l’intégration continue, vous pouvez consulter le cours de 3e année de l’ENSAE.
Voici le fichier .github/workflows/app.yaml qui contient la suite d’instruction donnée aux serveurs de Github pour exécuter notre chaine de production de l’image Docker. Celui-ci est quasiment une reprise mot pour mot de l’exemple de la documentation Github.
Le workflow Github en question ( et )
.github/workflows/app.yaml
name: Dockerize
on:
push:
tags:
- "*"
branches:
- main
jobs:
docker-shiny:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Docker meta
id: docker_meta
uses: docker/metadata-action@v5
with:
images: inseefrlab/funathon2024-sujet2
- name: Set up QEMU
uses: docker/setup-qemu-action@v3
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v3
- name: Login to DockerHub
if: github.event_name != 'pull_request'
uses: docker/login-action@v3
with:
username: ${{ secrets.DOCKERHUB_USERNAME }}
password: ${{ secrets.DOCKERHUB_TOKEN }}
- name: Build and push
uses: docker/build-push-action@v6
with:
context: .
file: ./docker/Dockerfile
push: ${{ github.event_name != 'pull_request' }}
tags: |
${{ steps.docker_meta.outputs.tags }}
${{ github.ref == 'refs/heads/main' && 'inseefrlab/funathon2024-sujet2:shiny-test3' || '' }}
labels: ${{ steps.docker_meta.outputs.labels }}
- name: Image digest
run: echo ${{ steps.docker_build.outputs.digest }}
docker-streamlit:
runs-on: ubuntu-latest
steps:
- uses: actions/checkout@v4
- name: Docker meta
id: docker_meta
uses: docker/metadata-action@v5
with:
images: inseefrlab/funathon2024-sujet2
- name: Set up QEMU
uses: docker/setup-qemu-action@v3
- name: Set up Docker Buildx
uses: docker/setup-buildx-action@v3
- name: Login to DockerHub
if: github.event_name != 'pull_request'
uses: docker/login-action@v3
with:
username: ${{ secrets.DOCKERHUB_USERNAME }}
password: ${{ secrets.DOCKERHUB_TOKEN }}
- name: Build and push
uses: docker/build-push-action@v6
with:
context: .
file: ./docker/Dockerfile_python
push: ${{ github.event_name != 'pull_request' }}
tags: |
${{ steps.docker_meta.outputs.tags }}
${{ github.ref == 'refs/heads/main' && 'inseefrlab/funathon2024-sujet2:streamlit-test2' || '' }}
labels: ${{ steps.docker_meta.outputs.labels }}
- name: Image digest
run: echo ${{ steps.docker_build.outputs.digest }}6.2 Utilisation de l’image Docker pour mettre à disposition le Shiny ou Streamlit
Nous avons créé une image Docker qui est disponible sur Dockerhub, le réseau social de Docker. Pour rendre celle-ci vivante, nous devons la déployer dans un conteneur.
Footnotes
Pour le créer, vous pouvez taper F1 et dans la barre qui s’ouvre, taper notebook et cliquer sur
Create: New Jupyter Notebook. Enregistrer le fichier↩︎Ces fichiers ne sont pas générés manuellement. Ce sont des outils adaptés (
renvpourR,pippourPython) qui font ce travail de versionnage de l’environnement.↩︎Si vous utilisez
renvdans vos futurs projets, ce que nous vous recommandons, cette commande n’est pas à inscrire dans vos scripts. Vous pouvez indiquer que cette commande est nécessaire dans leREADMEde votre projet.↩︎Si vous êtes peu familier avec ce type de fichiers, vous pouvez consulter la fiche
utilitRsur le sujet ()↩︎Si vous êtes peu familier avec les données géographiques, vous pouvez retenir l’idée qu’il s’agit de données traditionnelles auxquelles s’ajoute une dimension spatiale. Cette dernière vise à localiser les données sur la terre. La localisation se fait dans un espace à deux dimensions (espace cartésien) alors que notre planète est une sphère en trois dimensions. Le principe d’un système de projection est de faire ce passage en deux dimensions des positions. Le plus connu est le système GPS, qui est un héritier lointain de la représentation du monde par Mercator. Ce système est connu sous le nom de WGS 84 et porte le code EPSG 4326. L’autre système à retenir est le Lambert 93 (code EPSG 2154) qui est la projection légale en France (celle-ci, a contrario du Mercator, ne déforme pas la France sur une carte). Pour en savoir plus sur les systèmes de représentation, les avantages et inconvénients de chacun, il existe de nombreuses ressources en ligne. Des éléments introductifs, et des démonstrations interactives, en lien avec la librairie
GeopandasdePythonsont disponibles ici.↩︎Vous perdrez la mise en forme du header du tableau qui n’est pas conciliable avec l’interactivité.↩︎