Notations
Pour les données continues, formellement :
\(I_1,\dots, I_n\), \(n\) enregistrements individuels
\(Z_1,..,Z_p\), \(p\) données continues
\(X\) la matrice de données originale, \(X^{'}\) la matrice de données protégée
Distance entre matrices
-
Erreur quadratique moyenne : somme des différences au carré entre les deux matrices, composante par compasante, divisée par le nombre de coefficients d’une matrice (même pour les deux) \[\frac{1}{np}\sum_{j=1}^p\sum_{i=1}^n(x_{ij}-x^{'}_{ij})^2\]
Distance entre matrices
-
Erreur absolue moyenne : somme des différences absolues entre les deux matrices, composante par composante, divisée par le nombre de coefficients d’une matrice (même pour les deux) \[\frac{1}{np}\sum_{j=1}^p\sum_{i=1}^n|x_{ij}-x^{'}_{ij}|\]
Distance entre matrices
-
Variation moyenne : somme des variations absolues en pourcentage des composantes de la matrice protégée par rapport à la matrice de données originale \[\frac{1}{np}\sum_{j=1}^p\sum_{i=1}^n\frac{|x_{ij}-x^{'}_{ij}|}{|x_{ij}|}\]
Avec \(x_{ij} \ne 0\).
“En moyenne, chaque cellule a été modifiée de x% par rapport à la valeur d’origine.”
Un exemple
-
Erreur quadratique moyenne =
\(\frac{(36-34)^2+(41-48)^2+(52-58)^2+(17-23)^2+(35-35)^2+(5-2)^2}{6}=22\)
\(\frac{|36-34|+|41-48|+|52-58|+|17-23|+|35-35|+|5-2|}{6}=4\)
\(\frac{\frac{|36-34|}{36}+\frac{|41-48|}{41}+\frac{|52-58|}{52}+\frac{|17-23|}{17}+\frac{|35-35|}{35}+\frac{|5-2|}{5}}{6}=0.15\)
Effet de taille variation moyenne
La variation moyenne dépend de la taille de \(x_{ij}\) :
\(x_{ij}\) grande \(\rightarrow\) même une différence importante \(|x_{ij} - x^{'}_{ij}|\) donne un ratio faible
\(x_{ij}\) petite \(\rightarrow\) même un petit écart absolu \(|x_{ij} - x^{'}_{ij}|\) donne un ratio élevé
Corriger l’effet de taille
Pour que le ratio ne dépende pas de la taille de \(x_{ij}\) on utilise une autre mesure : \[\frac{1}{np}\sum_{j=1}^p\sum_{i=1}^n\frac{|x_{ij}-x^{'}_{ij}|}{\sqrt{2}S_j}\] avec \(S_j\) l’écart type de la \(j\)-ème variable
Permet de comparer les variations à variabilité “normale” de la variable.
Mesures spécifiques
Comparaisons univariées (comparaison de la distribution d’une variable avant et après perturbation).
Comparaisons bivariées: Corrélations linéaires par exemple.
Comparaison multivariées: Comparaison des plans d’une analyse en composante principale.
Comparaison des paramètres d’une régression, etc.


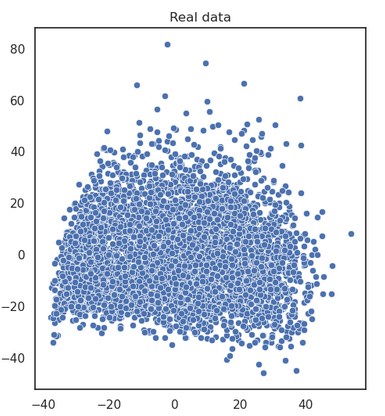
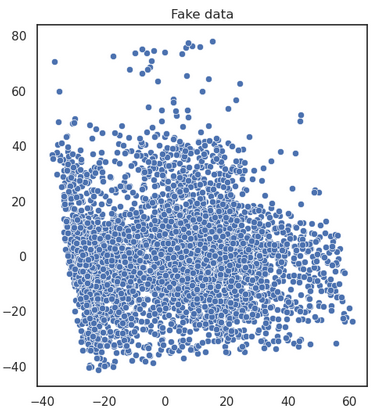
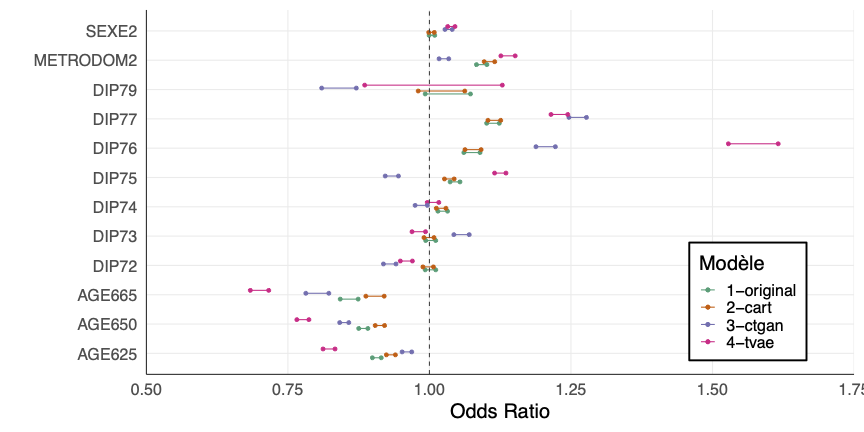
Comment la définir ?