Code
library(readr)
library(purrr)
library(dplyr)
library(ptable)
library(cellKey)Cette fiche présente la manière d’appliquer la méthode des clés aléatoires avec le package cellKey.
L’objectif principal consiste à bien maîtriser les étapes successives permettant d’appliquer la méthode.
Les détails de cette méthode sont présentés ici.
Pour installer les packages nécessaires, vous trouverez les instructions à suivre dans la fiche Ressources / Installer les packages et les outils sur R.
library(readr)
library(purrr)
library(dplyr)
library(ptable)
library(cellKey)source("../R/fun_import_data.R")
lfs_2023 <- import_lfs() |>
mutate(across(where(is.factor), as.character))head(lfs_2023) REG DEP ARR SEXE AGE AGE6 ACTEU DIP7 PCS1Q ANCCHOM HHID
<char> <char> <char> <char> <int> <char> <char> <char> <char> <char> <int>
1: 28 76 761 1 53 50 1 4 30 99 3558
2: 28 76 761 2 43 25 1 7 52 99 3558
3: 28 76 761 2 17 15 3 5 99 99 3558
4: 28 76 761 1 17 15 3 4 99 99 3558
5: 11 92 922 1 42 25 1 7 62 99 5973
6: 11 92 922 2 54 50 1 7 62 99 5973
HH_TAILLE HH_AGE HH_DIP HH_PCS IS_CHOM
<char> <char> <char> <char> <int>
1: 4 53 4 30 0
2: 4 53 4 30 0
3: 4 53 4 30 0
4: 4 53 4 30 0
5: 2 54 7 62 0
6: 2 54 7 62 0Pour plus d’informations sur les données, on pourra se reporter à la fiche “Présentation des données”.
A partir des données individuelles, on souhaite diffuser l’ensemble des tableaux:
tableau1: REG*SEXE*AGE6*ACTEU
tableau2: REG*SEXE*AGE6*DIP7
tableau3: REG*SEXE*AGE6*PCS1Q
cellKey
Pour pouvoir reproduire la même perturbation éventuellement plus tard, il est important de choisir une graine aléatoire (seed). Cet argument intégré à la fonction cellKey::ck_generate_rkeys permet de regénérer les mêmes nombres aléatoires à chaque fois.
En production, il serait préférable de générer les clés une fois et de stocker le jeu de données avec les clés créées une fois. L’argument seed permet de générer la même séquence de nombres aléatoires, mais cette reproductibilité dépend du type de machine sur laquelle cette séquence est générée: sur une machine Linux, il n’est pas garantie que le résultat soit identique à une machine Windows.
Les clés aléatoires sont le seul élément vraiement aléatoire dans la méthode dite des clés aléatoires (CKM), il est donc important de les conserver de manière sécurisée avec le jeu de données individuelles et de ne les transmettre qu’aux personnes disposant des droits.
lfs_2023$rk <- ck_generate_rkeys(dat = lfs_2023, nr_digits = 7, seed=441960)Cette opération crée une colonne supplémentaire, ici appelée rk(pour record key), dont la distribution est uniforme, comme souhaitée:
hist(lfs_2023$rk)
Avec le package cellKey, il faut spécifier chaque variable: modalités, emboîtements éventuels et la modalité du total.
dim_reg <- hier_create(
root = "Total",
nodes = sort(unique(lfs_2023$REG))
)
hier_display(dim_reg)Total
├─11
├─28
├─76
└─94dim_sexe <- hier_create(
root = "Total",
nodes = sort(unique(lfs_2023$SEXE))
)
hier_display(dim_sexe)Total
├─1
└─2dim_age6 <- hier_create(
root = "Total",
nodes = sort(unique(lfs_2023$AGE6))
)
hier_display(dim_age6)Total
├─15
├─25
├─50
├─65
└─90dim_acteu <- hier_create(
root = "Total",
nodes = sort(unique(lfs_2023$ACTEU))
)
hier_display(dim_acteu)Total
├─1
├─2
└─3dims_vars <- list(REG=dim_reg, SEXE=dim_sexe, AGE6=dim_age6, ACTEU = dim_acteu)tableau1 <- ck_setup(
x = lfs_2023,
rkey = "rk",
dims = dims_vars
)tableau1est un objet R6, et non directement un tableau.
class(tableau1)[1] "cellkey_obj" "R6" L’ensemble des méthodes (fonctions qui s’appliquent à un objet) sont disponibles en utilisant la fonction str(tableau1).
On peut, par exemple, contruire le tableau des comptages originaux :
tableau1$freqtab() |> head() REG SEXE AGE6 ACTEU vname uwc wc puwc pwc
<char> <char> <char> <char> <char> <num> <num> <num> <num>
1: Total Total Total Total total 34053 34053 NA NA
2: Total Total Total 1 total 16878 16878 NA NA
3: Total Total Total 2 total 1362 1362 NA NA
4: Total Total Total 3 total 15813 15813 NA NA
5: Total Total 15 Total total 4474 4474 NA NA
6: Total Total 15 1 total 1437 1437 NA NAOn peut s’apercevoir que la fonction a bien calculé l’ensemble des marges du tableau et pas seulement les croisements les plus fins.
Pour construire la matrice de transition, on utilse le package ptablede la manière suivante:
Les paramètres principaux sont:
D: l’amplitude de la déviationV: la variance du bruitjs: le seuil d’interdiction des petites valeursLa matrice de transition est construite de façon à respecter au mieux les contraintes suivantes:
V
Dans le package ptable, les distributions sont optimisées pour maximiser leur entropie.
Avec tout cela, certaines combinaisons de paramètres ne permettent pas de construire une matrice, souvent en raison d’une variance trop faible.
Choisissons pour l’exemple: D=10, V=10, js=4. Avec ce dernier paramètre, on choisit de ne pas avoir de comptages égaux à 1, 2 ou 3 dans notre tableau final.
ptab1 <- create_cnt_ptable(D = 10, V = 10, js = 4)Observons les distributions de probabilités proposées:
plot(ptab1, type="d")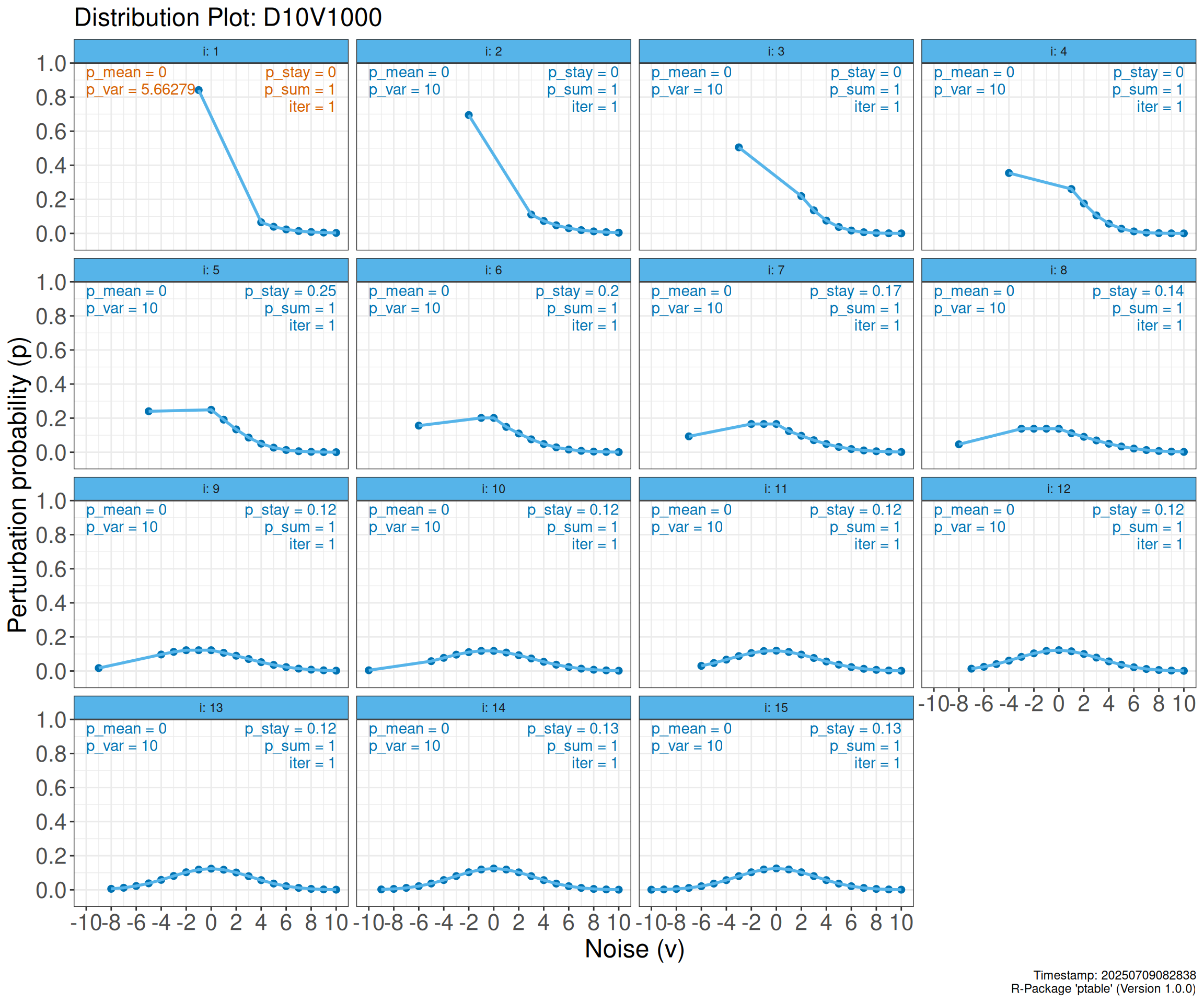
La perturbation est appliquée directement par une fonction du package cellKey, mais il est important de noter que la table de perturbation est directement accessible dans l’objet ptabque nous venons de créer:
ptab1@pTable |> head() i j p v p_int_lb p_int_ub type
<num> <num> <num> <num> <num> <num> <char>
1: 0 0 1.00000000 0 0.0000000 1.0000000 all
2: 1 0 0.84121944 -1 0.0000000 0.8412194 all
3: 1 5 0.06535617 4 0.8412194 0.9065756 all
4: 1 6 0.03920686 5 0.9065756 0.9457825 all
5: 1 7 0.02352001 6 0.9457825 0.9693025 all
6: 1 8 0.01410954 7 0.9693025 0.9834120 allOn applique cette table de perturbation à l’objet tableau1 construit précédemment:
params1 <- ck_params_cnts(ptab = ptab1)
tableau1$params_cnts_set(val = params1, v = "total")--> setting perturbation parameters for variable 'total'On s’appuie sur la méthode perturb() de notre objet tableau1. Celle-ci appliquera la perturbation en utilisant les clés individuelles et la matrice de transition.
tableau1$perturb(v = "total")Count variable 'total' was perturbed.Pour récupérer le résultat:
tableau1$freqtab(v = "total") REG SEXE AGE6 ACTEU vname uwc wc puwc pwc
<char> <char> <char> <char> <char> <num> <num> <num> <num>
1: Total Total Total Total total 34053 34053 34055 34055
2: Total Total Total 1 total 16878 16878 16877 16877
3: Total Total Total 2 total 1362 1362 1363 1363
4: Total Total Total 3 total 15813 15813 15814 15814
5: Total Total 15 Total total 4474 4474 4474 4474
---
356: 94 2 65 3 total 74 74 70 70
357: 94 2 90 Total total 0 0 0 0
358: 94 2 90 1 total 0 0 0 0
359: 94 2 90 2 total 0 0 0 0
360: 94 2 90 3 total 0 0 0 0Il est important de pouvoir se faire une idée de la déformation que la perturbation a produite nos données.
Le package cellKey propose un ensemble de métriques, dont:
d1: les écarts absolus entre données originales et perturbées.d2: les écarts absolus relatifs entre données originales et perturbées.d3: les écarts absolus entre les racines carrées des données originales et perturbées.tableau1$measures_cnts(v = "total", exclude_zeros = TRUE)$overview
noise cnt pct
<fctr> <int> <num>
1: -9 2 0.005555556
2: -8 2 0.005555556
3: -7 3 0.008333333
4: -6 10 0.027777778
5: -5 14 0.038888889
6: -4 21 0.058333333
7: -3 31 0.086111111
8: -2 26 0.072222222
9: -1 41 0.113888889
10: 0 79 0.219444444
11: 1 34 0.094444444
12: 2 38 0.105555556
13: 3 25 0.069444444
14: 4 15 0.041666667
15: 5 12 0.033333333
16: 6 5 0.013888889
17: 7 1 0.002777778
18: 8 1 0.002777778
$measures
what d1 d2 d3
<char> <num> <num> <num>
1: Min 0.00 0.000 0.000
2: Q10 0.00 0.000 0.000
3: Q20 1.00 0.000 0.011
4: Q30 1.00 0.001 0.024
5: Q40 2.00 0.002 0.037
6: Mean 2.52 0.066 0.106
7: Median 2.00 0.004 0.049
8: Q60 3.00 0.007 0.069
9: Q70 3.00 0.016 0.102
10: Q80 4.00 0.033 0.164
11: Q90 5.00 0.101 0.266
12: Q95 6.00 0.188 0.397
13: Q99 8.00 0.737 0.645
14: Max 9.00 4.000 1.236
$cumdistr_d1
cat cnt pct
<char> <int> <num>
1: 0 38 0.1241830
2: 1 112 0.3660131
3: 2 168 0.5490196
4: 3 223 0.7287582
5: 4 257 0.8398693
6: 5 283 0.9248366
7: 6 297 0.9705882
8: 7 301 0.9836601
9: 8 304 0.9934641
10: 9 306 1.0000000
$cumdistr_d2
cat cnt pct
<char> <int> <num>
1: [0,0.02] 222 0.7254902
2: (0.02,0.05] 255 0.8333333
3: (0.05,0.1] 275 0.8986928
4: (0.1,0.2] 292 0.9542484
5: (0.2,0.3] 296 0.9673203
6: (0.3,0.4] 298 0.9738562
7: (0.4,0.5] 302 0.9869281
8: (0.5,Inf] 306 1.0000000
$cumdistr_d3
cat cnt pct
<char> <int> <num>
1: [0,0.02] 84 0.2745098
2: (0.02,0.05] 155 0.5065359
3: (0.05,0.1] 213 0.6960784
4: (0.1,0.2] 261 0.8529412
5: (0.2,0.3] 280 0.9150327
6: (0.3,0.4] 291 0.9509804
7: (0.4,0.5] 295 0.9640523
8: (0.5,Inf] 306 1.0000000
$false_zero
[1] 13
$false_nonzero
[1] 0
$exclude_zeros
[1] TRUEEn moyenne, la perturbation a générée une déviation de \(\pm2.52\) dans les cases de notre tableau.
Reproduire le résultat de la perturbation pour la case REG=11,SEXE=1,AGE6=25,ACTEU=2, dont les valeurs originales et perturbées sont les suivantes:
tableau1$freqtab(v = "total") |>
filter(REG=="11",SEXE=="1",AGE6=="25", ACTEU=="2") REG SEXE AGE6 ACTEU vname uwc wc puwc pwc
<char> <char> <char> <char> <char> <num> <num> <num> <num>
1: 11 1 25 2 total 173 173 173 173Pour cela vous aurez besoin:
ptab1@pTable pour récupérer la perturbation à appliquer sur votre case.Retrouvez-vous le même résultat que cellKey.
Appliquer à nouveau la perturbation sur tableau1, en posant js=0. Les résultats sont-ils de meilleure qualité?
Appliquer un arrondi de base 10 au tableau1. Les résultats sont-ils de meilleure qualité ?
Appliquer la méthode aux deux autres tableaux de données. Comme ces tableaux ont des cases communes, vous vérifierez que les résultats sont bien identiques sur celles-ci.