Formation au web scraping
Rabat - Coopération internationale
December 1, 2022
Sommaire
I. Introduction au web scraping
I. Introduction au web scraping
I. Sommaire
Présentation générale et usages courants
Présentation générale et usages courants
Qu’est-ce que le web scraping ?
- Le web scraping désigne un ensemble de techniques d’extraction de contenu sur des sites internet.
- Le terme fait généralement référence à l’usage de bots pour collecter ces contenus automatiquement.
Exemples introductifs
- On souhaite accéder à la liste des présidents des États-Unis et réunir les dates de mandat dans un
Excel.
- On souhaite télécharger le classement QS 2023 des universités et filtrer les universités italiennes.
- On souhaite accéder à un répertoire d’expressions idiomatiques et trouver toutes celles contenant le mot “nez”.
Web scraping, web crawling, screen scraping, quelles différences ?
- Le web scraping se réfère à l’extraction des données, ou captation d’informations, sur une ou plusieurs pages web.
- Le web crawling, ou spidering, correspond à la recherche (ou la navigation parmi) de nouveaux URLs sur Internet ou sur un site spécifique.
- Quant au screen scraping, proche du web scraping, il consiste plutôt à extraire le contenu visuel d’un site apparaissant à l’écran, comme des images.
Note
Web scraping et web crawling peuvent aller ensemble :
- On utile d’abord un crawler pour récupérer tous les urls d’un site …
- … Puis on scrape chacune des pages les unes après les autres
Cas d’usage pratiques
Études de marché et intelligence économique
- Faire un suivi des prix sur des sites de ventes (possiblement concurrents) en les scrapant régulièrement
- On peut alors parler de price scraping
- Glaner des informations sur les sites d’entreprises concurrentes
Exemple
Dans les répertoires d’expressions idiomatiques, il est facile de “dérober” les contenus les uns des autres (Expressio, Expressions Françaises, L’internaute…)
Cas d’usage pratiques
Analyses de sentiment et génération de leads
- Récupérer les commentaires d’un produit ou d’une entreprise sur un site tiers afin d’analyser les retours obtenus et faire du sentiment analysis
- Un papier de recherche sur le sujet
- Obtenir une liste de clients potentiels ou répondant à des critères spécifiques
- À partir de sites comme les Pages Jaunes ou Google Maps pour les entreprises
Cas d’usage pratiques
Obtenir des données pour alimenter des modèles de ML
- Regrouper divers indicateurs et séries temporelles via les Google Trends pour améliorer les performances de modèles de prédiction
- En phase expérimentale à l’INSEE, par exemple pour des problématiques de nowcasting
- Surveiller les valeurs de stocks boursiers et mouvements de marché sur Yahoo Finance et les inclure dans des modèles
- En l’occurrence,
Yahoo Financeoffre aussi une API pour l’extraction de données
- En l’occurrence,
Cas d’usage pratiques
Dans des domaines spécifiques
- Dans le domaine immobilier, de nombreuses agences utilisent le scraping pour alimenter leur propre base de biens à vendre ou à louer.
- On peut aussi trouver de nombreux agrégateurs d’annonces en ligne.
- Dans le domaine aérien, nombreux sont les comparateurs en ligne qui ont recours au scraping pour présenter des offres de trajets issues de plusieurs compagnies.
- Ex : kiwi.com, lastminute.com…
- Ce n’est d’ailleurs pas le cas que dans le domaine du transport (ex: hébergement touristique).
- Dans le domaine des paris sportifs, il est courant de scraper les sites de statistiques sportives afin d’adapter l’offre des paris.
Cas d’usage pratiques
Dans le domaine de la recherche
Pour des chercheurs, le web scraping peut représenter une importante source de données, et ce dans des domaines très variés.
Cas d’usage pour un INS
- Scraper divers sites de ventes afin d’obtenir des données de prix pour le calcul de l’indice des prix à la consommation (
IPC)
- Compléter des données de statistiques d’entreprises avec des informations disponibles en ligne
- Minimiser la charge de réponse lors des enquêtes en favorisant le scraping
- Construire des bases de sondages, par exemple en scrapant les annuaires d’enseignes
Risques juridiques et scraping éthique
Le web scraping, est-ce légal ?
- Le web scraping en lui-même n’est pas une pratique illégale …
- … Mais l’utilisation faite des données scrapées peut être soumise à réglementation.
- Ces règles dépendent alors du pays dans lequel on se trouve ainsi que des données scrapées.
Attention
Diffuser ou commercialiser des données scrapées ou un quelconque travail réutilisant ces données n’est pas sans conséquence.
Une frontière floue
- Les législations spécifiques au web scraping sont peu nombreuses et différentes d’un pays à l’autre.
- En revanche, la réutilisation des données est encadrée.
- Par exemple par le code de la propriété intellectuelle ou par le
RGPD.
- Par exemple par le code de la propriété intellectuelle ou par le
- Les cas portés en justice ont des dénouements parfois différents les uns des autres, notamment d’un pays à l’autre, montrant bien qu’il s’agit là d’une zone parfois grise.
Une pratique pourtant très répandue
- Les cas d’usage, y compris dans de grandes entreprises, sont très nombreux.
- Les articles discutant de web scraping et de leur légalité sont tout aussi proliférants, mais pas toujours d’accord les uns avec les autres.
- Quelques ressources : Imperva, Islean Consulting, TechCrunch…
Les principales réglementations autour du web scraping
En France
- L’article 323-3 du code pénal : “Le fait […] d’extraire, de détenir, de reproduire […] frauduleusement les données qu’il [le site] contient est puni de cinq ans d’emprisonnement et de 150 000 € d’amende”
- En termes de droit de la concurrence, on pourra aussi parler de concurrence déloyale avec l’article L. 121-1 du code de la consommation
- Il serait même possible de parler de parasitisme et invoquer l’article 1240 du code civil
- La
CNILa également publié en 2020 un ensemble de nouvelles directives, limitant l’usage de données personnelles, même si publiques, à usage commercial
Les principales réglementations autour du web scraping
En Europe (1/2)
- La Directive 96/9/CE du Parlement Européen et du conseil
Elle introduit notamment le droit sui generis, protégeant les bases de données ayant nécessité un “investissement substantiel”
Le fabricant d’une base de données [a] le droit d’interdire l’extraction et/ou la réutilisation de la totalité ou d’une partie substantielle, évaluée de façon qualitative ou quantitative, du contenu de celle-ci, lorsque l’obtention, la vérification ou la présentation de ce contenu attestent un investissement substantiel du point de vue qualitatif ou quantitatif
L’extraction et/ou la réutilisation répétées et systématiques de parties non substantielles du contenu de la base de données qui supposeraient des actes contraires à une exploitation normale de cette base, ou qui causeraient un préjudice injustifié aux intérêts légitimes du fabricant de la base, ne sont pas autorisées
Les principales réglementations autour du web scraping
En Europe (2/2)
- Le RGPD, sur l’utilisation des données à caractère personnel
- Règlement européen mais d’application extraterritoriale
- 5 grands principes :
- Le principe de finalité
- Le principe de proportionnalité et de pertinence
- Le principe d’une durée de conservation limitée
- Le principe de sécurité et de confidentialité
- Les droits des personnes
- Le Data Governance Act, prévu pour septembre 2023
Les principales réglementations autour du web scraping
Encore d’autres
- Les jurisprudences issues des procès d’entreprises liés au web scraping
- Les mentions légales, conditions d’utilisation et autres consignes des sites concernés
- D’autant plus engageantes quand accéder au contenu nécessite d’accepter explicitement les conditions du site (par exemple en appuyant sur un bouton)
- Aux États-Unis, plusieurs textes peuvent s’appliquer, entre autres :
Les sites se protègent aussi eux-mêmes
- Afin d’éviter la réutilisation de leurs contenus par des concurrents et lutter contre l’espionnage
- Afin de bloquer les
botsqui occupent une partie significative du trafic, ralentissant ainsi l’accès au site- Un scraping mal fait peut s’assimiler à une attaque par déni de service (
DoS)
- Un scraping mal fait peut s’assimiler à une attaque par déni de service (
Les méthodes mises en place pour se protéger du scraping (1/2)
- Mettre en place des conditions d’utilisation contraignantes et instructions explicites pour se protéger d’un point de vue légal
- Repérer les adresses IP suspectes et bloquer leur accès au site, temporairement ou de façon permanente
- Identifier les bots et leur afficher un contenu différent des utilisateurs classiques, pour par exemple renvoyer de fausses données
- Limiter les requêtes ou la bande passante consommée par une même source, pouvant ainsi conduire à des collectes partielles ou interrompues
Les méthodes mises en place pour se protéger du scraping (2/2)
- Modifier régulièrement le format
HTMLdu contenu pour empêcher l’automatisation du scraping par autrui
- Créer des pages Honeypot qu’un humain ne visiterait jamais pour identifier puis bloquer des bots
- Utiliser des CAPTCHAs lorsqu’une activité suspecte est repérée
- Nécessiter une identification pour accéder au contenu du site
Les limites du web scraping
- La qualité des données obtenues par scraping n’est pas toujours au rendez-vous.
- De plus, vérification manuelle à faire pour vérifier qu’un faux contenu n’a pas été renvoyé par le site.
- Il faut ‘lutter’ contre les sites qui se défendent contre le scraping, ce qui n’est pas sans effort.
- Modifications manuelles des codes à faire régulièrement, rendant l’automatisation très difficile.
- Pérennité de la collecte au fil du temps incertaine.
- Les risques légaux sont existants, et plus généralement cela peut nuire à l’image d’un INS.
- Il vaut mieux favoriser des relations de confiance avec les sites concernés.
Remarque
Il est préférable de privilégier d’autres modes d’accès aux données lorsque cela est possible.
Dans ces conditions, quand envisager le web scraping ?
La politique de l’INSEE est de garder le web scraping comme dernière option. Les premières étapes recommandées sont d’abord de :
- Demander directement aux sites concernés l’accès à leurs données et nouer d’éventuels partenariats, par exemple modulo une contrepartie
- Chercher s’il existe une API du site permettant d’accéder aux données (ou la demander)
- Chercher des alternatives, comme accéder à des données similaires via un moyen moins contraignant
Pour un scraping éthique (et légal !)
- Le web scraping reste malgré tout une nouvelle source de données très pratique dans le cas où aucune meilleure alternative ne se présente.
- Il ne faut donc pas s’en priver lorsque c’est techniquement et juridiquement propice.
- Cependant, il existe des moyens de scraper de façon honnête, “éthique” et en minimisant la charge sur le site scrapé.
- Cela passe par exemple par demander la permission aux sites à scraper, ce qui peut aussi conduire à un éventuel partenariat.
Les guidelines du Système Statistique Européen
- Un ensemble de recommandations principalement à destination des INS publié durant l’été 2022
- La version précédente datant de février 2020 également disponible
In the context of the work on Big Data and Trusted Smart Statistics, the European Statistical System (ESS) increasingly utilises information published on the World Wide Web. To ensure that web scraping activities of European Statistical System (ESS) members, namely Eurostat and the national statistical institutes (NSIs) are carried out transparently, and in line with ethical and legal provision, this document proposes guidelines for an ESS wide web scraping policy. Once adopted, these guidelines not only foster nationally sound practices but also ensure a consistent approach across the ESS.
Les guidelines du Système Statistique Européen
Transparence
- Rendre publique la liste des collectes de données par scraping de l’INS, autrement dit être transparent
- Si l’impact sur site va être important (par exemple un scraping fait très fréquemment), informer spécifiquement le site concerné
- Plus généralement, prendre le réflexe de demander la permission
- S’identifier auprès du site lors de l’opération de scraping
Les guidelines du Système Statistique Européen
Minimiser l’impact
- Toujours chercher à minimiser l’impact sur les serveurs du site scrapé
- Notamment en limitant les requêtes effectuées au minimum requis
- Privilégier les heures creuses du site pour les opérations automatisées de scraping
- Étaler les requêtes en laissant un temps de ‘pause’ entre chaque requête, surtout sur un même domaine
Les guidelines du Système Statistique Européen
Confiance
- Favoriser les échanges avec les propriétaires des sites : partenariats, échanges de données, requêtes d’API…
- Se plier aux conditions d’utilisation des sites concernés et aux réglementations de la zone concernée
- Manipuler de façon sécurisée les données scrapées, notamment les données personnelles
- Ex : Respecter le RGPD, d’application extraterritoriale
⚠️ Ce qu’il ne faut pas faire !
- Consciemment déroger aux réglementations applicables et manquer de transparence
- Surcharger les requêtes sur le site concerné (assimilable à une attaque
DoS) ou multiplier les mêmes requêtes plusieurs fois
- Scraper un site entier lorsque l’on a seulement besoin d’une portion de son contenu
- Paralléliser les requêtes sur un site ou faire ces dernières en heures pleines
- Diffuser de façon non autorisée des données scrapées non publiques ou soumises à droit d’auteur
- Pour un INS, utiliser le scraping à des fins non statistiques ou hors du champ légal
Avertissements
- Selon les pays, il existe des données qui sont publiques mais dont le scraping est illégal.
- Il faut donc bien se renseigner sur les lois locales.
- Par exemple, la collecte d’adresses mail par scraping est illégale en Australie, en raison du Spam Act de 2003.
- Dans le doute, ne pas hésiter à se documenter davantage.
- Exemples de ressources : Carpentries, Rubyroidlabs…
- Il existe parfois des structures dont le rôle est justement d’évaluer l’aspect juridique de pratiques comme le web scraping.
- A l’INSEE, c’est la responsabilité de l’UAJC
- Outre l’aspect juridique, il faut bien passer en revue les impacts méthodologiques liés aux risques techniques du web scraping (collecte incomplète, rupture de collecte).
Rappels sur HTML
Comprendre la nature d’une page web
- Un site Internet est constitué de diverses pages Web.
- Celles-ci sont le produit de fichiers appelés codes source des pages.
- Les 3 langages principaux pour les coder sont :
- HTML : pour composer la structure des pages via un système de balises
- CSS : des feuilles de style pour décrire la présentation de pages
HTML - JavaScript : pour tout ce qui est relatif à l’interactivité d’un site (ex : boutons)
Pour en apprendre plus
Deux ressources-clés :
- W3C : World Wide Web Consortium
- MDN Web Docs : Mozilla Developer Network
Inspecter une page web
- Il est possible d’afficher le code source des pages Web, au sein duquel les scrapeurs doivent naviguer.
Clic droitsur la page puis- “Inspecter l’élément” pour observer un endroit spécifique de la page
- “Afficher le code source de la page” pour afficher le code de toute la page
Hiérarchisation d’une page web
Les balises HTML
- Sur une page web, vous trouverez à coup sûr des éléments comme
<head>,<title>, etc. Il s’agit des codes qui vous permettent de structurer le contenu d’une pageHTMLet qui s’appellent des balises.- Par exemple, les balises
<p>,<h1>,<h2>,<h3>,<strong>ou<em>.
- Par exemple, les balises
- Le symbole
< >est une balise : il sert à indiquer le début d’une partie. Le symbole</ >indique la fin de cette partie.
- La plupart des balises vont par paires, avec une balise ouvrante et une balise fermante (par exemple
<p>et</p>).
Exemple : les balises de tableau
| Balise | Description |
|---|---|
<table> |
Tableau |
<caption> |
Titre du tableau |
<tr> |
Ligne de tableau |
<th> |
Cellule d’en-tête |
<td> |
Cellule |
<thead> |
Section de l’en-tête du tableau |
<tbody> |
Section du corps du tableau |
<tfoot> |
Section du pied du tableau |
Un exemple : un tableau HTML
Un exemple : un tableau HTML
| Prénom | Nom | Profession |
|---|---|---|
| Mike | Stuntman | Cascadeur |
| Mister | Pink | Gangster |
Scraping d’une page web
- Le web scraping consiste à naviguer parmi ces balises
HTMLpour extraire le contenu désiré (textes, tableaux, images, …).
- Il est aussi possible de récupérer d’autres URLs sur une page pour s’y rendre et les scraper ensuite.
- Dans certains cas plus complexes, lire le contenu
HTMLne suffit pas,- Par exemple s’il faut cliquer sur des boutons pour faire apparaître le contenu désiré.
XPath
- Une page web peut aussi se présenter sous le format
XML, proche duHTML.
- Afin de justement naviguer dans une page
HTMLouXML, on fait appel à un langage d’expressions appeléXPath.- Ce sont des expressions
XPathqui seront utilisées en appel des fonctions. XPathpermet ainsi de se déplacer de noeud en noeud dans la structure arborescente d’une page.
- Ce sont des expressions
II. Mise en pratique
II. Sommaire
Présentation des différentes librairies
Présentation des différentes librairies
Les librairies principales sur Python
Plusieurs librairies permettent de faire du scraping en Python. Les principales sont :
Extraire les codes sources HTML
Requests et Urllib
- Rôle :
- Créer des requêtes
HTTPpour récupérer le contenu des pages web - Des headers peuvent être ajoutés aux requêtes pour s’identifier auprès du site
- Créer des requêtes
Requestsun peu plus simpliste queUrllib
Extraire les codes sources HTML
Bonne pratique
- Lorsque l’on scrape plusieurs pages d’un même site, il vaut mieux ouvrir une seule session sur le site et faire les requêtes à partir de là que réouvrir une nouvelle session à chaque requête.
- Si l’on scrape plusieurs sites différents, on ouvre une session par site distinct.
- Cela permet notamment d’éviter la saturation des serveurs en limitant le nombre de ports utilisés lorsque de larges volumes sont scrapés.
- Cela réduit également le délai des requêtes successives, puisqu’il n’y a pas à ouvrir une nouvelle session à chaque requête.
Analyser les codes HTML : BeautifulSoup
- Permet de formater des documents
HTMLouXMLen une structure arborescente - Permet ensuite de naviguer dans la structure pour scraper le contenu désiré
- Très intuitif à utiliser
Remarque
La librairie se trouve généralement sous le nom de bs4.
Analyser les codes HTML et XML : lxml
Permet de formater des documents
HTMLouXMLen une structure arborescentePermet de naviguer dans l’arborescence des balises lorsque celles-ci ne sont pas clairement identifiées
- Si par exemple il n’y a pas d’id ou de class
Repose notamment sur
XPath, permettant d’accéder à des balises enfouies profondément dans l’arborescenceParticulièrement utile pour des pages avec de nombreux éléments emboîtés peu identifiés
Interagir avec une page : Selenium
- Les librairies précédentes ne permettent pas d’interagir avec une page utilisant
Javascript- Ex: Appuyer sur un bouton, rentrer ses identifiants…
Seleniumpermet de simuler un navigateur (aussi appelé headless browser) puis d’interagir avec les élémentsJavaScriptdu site “comme un utilisateur”
Un outil plus complet : Scrapy
- Un outil plus complet mais aussi plus complexe
- Très utile pour les opérations de web crawling
- Davantage recommandé pour de gros projets
- Un tutoriel des Carpentries
Quelques librairies sur R
- polite
- Particulièrement orienté scraping éthique
- rvest
- Librairie la plus utilisée et donc documentée
Quelques librairies en Java
Javaest également beaucoup utilisé dans le domaine du web scraping
- Documentation extensive disponible sur Internet
Partie pratique
Une plateforme de travail : le SSP Cloud
Un Datalab pour l’expérimentation et la formation
- Plateforme de datascience dimensionnée pour les usages innovants
- Des technologies modernes qui favorisent la reproductibilité
- Lieu de formation et d’expérimentation
- Ouverte et collaborative
Du libre-service à la mise en production
Le projet Onyxia
- Un projet open-source pour déployer des plateformes de datascience modernes
- Le dépôt Github ici
De la formation
- Le catalogue de formation du SSP Cloud
- Des formations reproductibles
- Un catalogue contributif
- Innover sur les modes de formation
- Vers de l’auto-formation tutorée
De l’open-source
- Comptes GitHub institutionnels
- Pourquoi ouvrir ses codes ?
- Auditabilité des agents publics
- Meilleure qualité du code et reproductibilité
- Une vitrine pour l’auteur.e et pour l’INS
- Pour plus d’informations, contacter
Mise en pratique : se familiariser à BeautifulSoup et Selenium
- Une mise en pratique créée à destination des étudiants de Master de l’ENSAE Paris
- Incluant notamment les Administrateurs de l’INSEE en formation
- Le lien pour accéder au TP de web scraping ici
Pour aller plus loin
Un site dédié à l’utilisation de Python pour la data science
Créé et entretenu par Lino Galiana, data scientist à l’INSEE
Aspects techniques du scraping éthique
Les guidelines du SSE
S’identifier
S’identifier via le champ “user-agent”, l’un des headers renseignables lors d’une requête
HTTPUn autre champ parmi les headers possible :
from
Renseigner son nom, entité, coordonnées
On peut aussi inclure l’url contenant les informations liées à la collecte ou une explication sur les données prélevées
Les guidelines du SSE
Suivre les conventions
Il existe plusieurs conventions liées à l’utilisation d’Internet et du scraping qu’il faut tâcher de respecter.
On citera le Word Wide Web Consurtium (
W3C), notamment sur les protocoles de transfert hypertexte.
- Essentiel pour le scraping, il est vivement recommandé de se plier au protocole d’exclusion des robots.
- En tapant la racine de l’url suivi de ‘/robots.txt’, on peut accéder à une page du site indiquant les règles que doit respecter un programme pour accéder au site, les pages pouvant être scrapées, celles qui ne doivent pas l’être, la charge acceptable de scraping (fréquence des requêtes par exemple)…
- Exemple: https://fr.wikipedia.org/robots.txt
- Les crawlers peuvent lire ces fichiers et s’y plier d’eux-mêmes (cf IBM).
- Davantages d’informations et explications techniques ici
Contourner les défenses des sites
Quelques pratiques admises pour ne pas être bloqué par les sites scrapés :
- Ajouter des pauses entre chaque requête, pour ne pas aller plus vite qu’un utilisateur ne le pourrait (
time.sleep()enPython)- C’est également une bonne pratique de scraping éthique
- Un délai de 2 à 5 secondes par requête est la préconisation usuelle
- Modifier régulièrement le champ user-agent (par exemple avec un compteur) avant que celui-ci ne se fasse bloquer
Autres recommandations pour un INS
- Faire en sorte de pouvoir tracer l’activité d’un programme, afin de notamment pouvoir en auditer le fonctionnement.
- Les logs doivent contenir des informations sur l’utilisateur ou le compte système effectuant l’action, le résultat de l’action et le temps qu’elle a mis à s’exécuter.
- En cas de passage en production, il est nécessaire que le programme fasse l’objet d’une revue de code (entre pairs ou externe), voire, selon la nature de son intégration, relève d’une démarche d’homologation de sécurité.
- Bien faire attention à la documentation et à la transmission des codes lors de projets de scraping, pour éviter les pertes de connaissance au sein d’une équipe lors d’un changement de poste.
- Il est déjà arrivé que des collectes soient freinées en raison du départ de la personne à les avoir mises en place.
Automatisation et industrialisation
Pré-requis
- Accès Internet au sein de l’INS avec un proxy bien configuré si existant
- Les sites scrapés doivent être dans l’allow-list et ne doivent pas avoir déjà bloqué l’adresse IP
Automatiser et industrialiser les processus de scraping
- En raison des efforts des sites contre le scraping (ex : format des sites changeant régulièrement, blocage des adresses IP),
- Limiter les interactions humaines est quasiment impossible
- Industrialiser les processus nécessite des révisions régulières
- Automatiser les méthodes peut reposer sur un cronjob ou autre orchestrateur
Stocker les données
- En général, les données brutes (ex : les pages web) sont stockées dans une base
NoSQLet sont traitées ensuite.- Les codes
HTMLpeuvent par exemple être stockés dans une baseMongoDB.
- Les codes
- Problèmes méthodologiques courants :
- Différencier le stock du flux : la page web que je viens de scraper est-elle nouvelle ou est-ce la même que celle d’hier ?
- Dédoublonner le contenu lorsque par exemple le scraping se fait sur plusieurs sites dont le contenu peut s’intersecter.
III. Divers cas d’usage
III. Sommaire
Quelques litiges légaux
LinkedIn v. HiQ Labs (2019)
Le litige
- Contexte : HiQ scrape les données des utilisateurs LinkedIn (accessibles publiquement) pour nourrir un outil de prédiction de l’attrition, commercialisé ensuite.
- Cas :
- LinkedIn tente d’interdire la collecte au nom du CFAA et d’une violation des conditions d’utilisation du site.
- HiQ saisit la justice pour se défendre.
- Verdict : Deux victoires (tribunal californien et Cour Suprême) pour HiQ, dont le maintien de l’activité de scraping est autorisé.
LinkedIn v. HiQ Labs (2019)
Les conclusions
- LinkedIn n’est pas propriétaire des données : ce sont en réalité les membres eux-mêmes. Les utilisateurs qui choisissent un profil public attendent « évidemment » qu’il soit accessible par des tiers.
- Laisser à LinkedIn le contrôle sur l’utilisation des données publiques pourrait engendrer un « monopole de l’information » préjudiciable à l’intérêt public.
- Le
CFAAest inadapté pour ce type de cas.
- HiQ n’a scrapé que des données auxquelles n’importe quel utilisateur a accès, et LinkedIn ne peut pas les leur interdire spécifiquement.
Ryanair v. Opodo (2010)
Le litige
- Contexte : Opodo scrape (entre autres) les données du site de Ryanair pour les agréger en un comparateur de prix de billets.
- Cas : Ryanair attaque Opodo en justice dans plusieurs pays européens, notamment en France, pour non respect des CGU, concurrence déloyale et parasitisme.
- Verdict : Différent selon les pays, mais en France Ryanair a été débouté à deux reprises.
Ryanair v. Opodo (2010)
Les conclusions
Le Tribunal de Paris :
- Rejette l’intégralité des demandes de Ryanair
- Condamne Ryanair à d’importantes sommes à Opodo pour préjudice
- Maintient le droit d’Opodo à scraper les données publiques du site de Ryanair
Ryanair v. PR Aviation (2015)
Le litige
- Contexte : PR Aviation scrape (entre autres) les données du site de Ryanair pour les agréger en un comparateur de prix de billets.
- Cas : Ryanair attaque PR Aviation en justice aux Pays-Bas pour ne pas avoir respecté les termes contractuels d’utilisation du site et pour infraction aux directives européennes de protection des données.
Ryanair v. PR Aviation (2015)
Les conclusions
Décision préliminaire de la CJEU :
- La
Directive 96/9/ECne s’applique pas dans ce cas, car les bases de données ne qualifient pas :- Pour le droit au copyright
- Pour la protection sui generis
- En revanche, Ryanair est autorisé à instaurer des limitations contractuelles sur l’utilisation de son site, tant qu’elles ne contredisent pas le droit national
- On notera que pour pouvoir lancer une recherche et visualiser les vols Ryanair disponibles en ligne, il faut explicitement accepter les CGU du site en cliquant sur un bouton
Ryanair v. Expedia (2019)
- Contexte : Expedia scrape (entre autres) les données du site de Ryanair pour les agréger sur son comparateur en ligne.
- Cas : Ryanair attaque PR Aviation en justice aux Etats-Unis et en Irlande pour ne pas avoir respecté les termes contractuels d’utilisation du site et au nom du CFAA aux Etats-Unis.
- Verdict : Accord “à l’amiable” entre les deux géants, mais les vols de Ryanair n’apparaissent plus sur le site d’Expedia.
Ryanair v. Kiwi.com (2021)
Le litige
Contexte : Kiwi.com scrape (entre autres) les données du site de Ryanair pour les agréger sur son comparateur en ligne.
Cas : Ryanair attaque Kiwi.com en justice en République Tchèque pour ne pas avoir respecté les termes contractuels d’utilisation du site.
Verdict : Première défaite de Kiwi.com, puis victoire en appel auprès de la Cour Constitutionnelle Tchèque.
Ryanair v. Kiwi.com (2021)
Les conclusions
- La cour régionale de Brno avait imposé à Kiwi.com de se plier aux CGU de Ryanair. Cela impliquait notamment que Kiwi.com devait transmettre à Ryanair plusieurs données personnelles sur ses clients ayant acheté un billet de la compagnie sur la plateforme (dont par exemple leurs coordonnées).
- En cour d’appel, la décision avait été révoquée pour les raisons suivantes :
- Droit national à la protection judiciaire
- Liberté de conduire son entreprise
- Le procès initial n’aurait pas suffisamment tenu compte du contexte
Ryanair v. Lastminute - Italie (2019)
- Contexte : Lastminute scrape (entre autres) les données du site de Ryanair pour les agréger sur son comparateur en ligne.
- Cas :
- Ryanair attaque Lastminute en justice en Italie pour ne pas avoir respecté les CGU du site et le droit à la propriété intellectuelle.
- Ryanair demande également un accès aux données de Lastminute liées aux tickets de la compagnie.
- Verdict : La Cour Suprême prend le parti de Lastminute et n’autorise pas l’aspect contractuel des CGU de Ryanair ni l’accès aux données demandées.
Ryanair v. Lastminute - France (2022)
Contexte : Lastminute scrape (entre autres) les données du site de Ryanair pour les agréger sur son comparateur en ligne.
Cas : Ryanair attaque Lastminute en justice en France pour ne pas avoir respecté les termes contractuels d’utilisation du site.
Verdict : La cour d’appel de Paris prend le parti de Ryanair et ordonne la cessation immédiate des activités de scraping de Lastminute, en plus de lourds dommages et intérêts.
Affaire “Bluetouff” - France (2015)
- Cour de cassation, Chambre criminelle, 20 mai 2015, 14-81.336
- Olivier Laurelli, alias Bluetouff, condamné à 3000 euros d’amende pour avoir téléchargé et réutilisé en 2012 (pour diffusion) des données de l’Anses accessibles publiquement sur leur site, là où elles n’auraient pas dû l’être.
- Bluetoof relaxé par le tribunal de Créteil en 2012 puis condamné auprès de la Cour d’appel de Paris en 2015.
LeBonCoin v. Entreparticuliers (2021)
Le litige
Contexte : Entreparticuliers.com scrape quotidiennement les annonces immobilières présentes sur leboncoin.fr afin de les republier sur son propre site
Cas : LeBonCoin attaque en justice Entreparticuliers.com en France pour non respect du droit
sui generisde ses bases de donnéesVerdict : Entreparticuliers.com condamné à deux reprises (par le Tribunal puis la Cour d’appel de Paris)
LeBonCoin v. Entreparticuliers (2021)
Les conclusions (1/2)
- Accéder au contenu du site LeBonCoin.fr ne nécessite pas d’accepter explicitement les CGU, LeBonCoin n’a donc pas invoqué le côté contractuel de ces dernières mais seulement le droit
sui generis.
- Pour en bénéficier, LeBonCoin a dû témoigner d’un investissement substantiel dans la constitution, la vérification ou la présentation de ses bases de données.
- En pratique, c’est un point bloquant pour nombre de producteurs de données dans de telles affaires.
- En l’occurrence, il a été prouvé que les moyens humains et financiers investis dans ces bases étaient bien substantiels.
- Entreparticuliers a donc été condamné à deux reprises :
- Par le tribunal au nom de l’article L. 342-1 du Code de la propriété intellectuelle
- Par la Cour d’appel au nom de l’article L. 342-2 du même Code
LeBonCoin v. Entreparticuliers (2021)
Les conclusions (2/2)
- La Cour d’appel souligne que le but poursuivi lors du scraping est sans incidence pour caractériser l’atteinte au droit
sui generis.
- Entreparticuliers.com condamné à verser d’importants dommages et intérêts à leboncoin.fr pour :
- Préjudice financier : LeBonCoin témoignant d’importants investissements dans la lutte contre le web scraping
- Préjudice d’image : LeBonCoin démontrait un nombre important de plaintes de ses utilisateurs
D’autres litiges légaux en Europe
- AutoTrack v. GasPedaal (2013 - Pays-Bas)
- Aussi connu sous le nom de Innoweb BV v. Wegener ICT Media BV
- Le méta-moteur de recherche GasPedaal est interdit de scraper GasPedaal, notamment car :
- Les données scrapées sont réutilisées sans modification notoire
- AutoTrack bénéficie du droit
sui generissur ses données
D’autres litiges légaux aux Etats-Unis
- Craigslist Inc. v. 3Taps Inc. ( 2013 - Etats-Unis)
- Suite à un accord mutuel, 3Taps et PadMapper ne pourront plus scraper les données de Craiglist et devront lui verser une somme importante d’argent.
- Le CFAA a été invoqué par Craiglist et accepté par la Cour suite au blocage des adresses IP des deux entreprises et les multiples mises en demeure envoyées pour faire cesser les activités de collecte. 3Taps avait continué ses activités de scraping en utilisant un VPN (et PadMapper les leur avait scrapées).
Conclusions des jurisprudences
En Europe (1/2)
- Les CGU d’un site sont juridiquement contractuelles pour interdire toute pratique de web scraping …
- … au moins dès lors qu’elles sont acceptées explicitement (par exemple en appuyant sur un bouton) …
- … sauf si mention contraire par les lois nationales (ex : si supériorité du droit à la concurrence, déjà invoqué en Italie ou en République Tchèque).
- Republier des données scrapées …
- au moins à des fins commerciales
- sans qu’un travail notable de réutilisation soit fait
- par exemple pour un méta-moteur de recherche
- pouvant créer un préjudice pour le site initial
Conclusions des jurisprudences
En Europe (2/2)
- Un contenu accessible publiquement, mais sans que ce ne soit manifestement un choix du site, ne peut pas forcément être légalement scrapé.
- Le droit
sui generisprotège les bases de données nécessitant des investissements substantiels par les producteurs, indépendamment de l’intention des scrapeurs.- En revanche, prouver la qualification à ce droit n’est pas tâche aisée.
Conclusions des jurisprudences - Aux Etats-Unis
- Un site affichant des données publiques dont il n’est pas propriétaire ne peut pas en empêcher le scraping.
- L’activité de web scraping en elle-même ne viole pas le Computer Fraud and Abuse Act.
- Lors d’un litige, bloquer l’adresse IP d’un utilisateur et lui adresser une mise en demeure interdisant le scraping du site peuvent éventuellement suffire à invoquer le CFAA pour protéger les bases de données du site.
Et pour un INS alors ?
Quid des prérogatives de puissance publique pour recueillir de l’information ?
- En Europe, la loi n° 633 du 22 avril 1941, pour la protection du droit d’auteur, prévoit une exception en cas d’utilisation d’une base de données à des fins de recherche scientifique à but non lucratif (art. 64-sexies de la loi n° 633/1941 modifié).
- Bien que la recherche et la production statistiques ne soient pas explicitement mentionnées, ces dispositions apportent un cadre raisonnable pour permettre aux statisticiens publics d’accéder aux informations des bases de données en ligne et pour traiter ces informations afin de produire des résultats statistiques anonymisés.
Le scraping à l’INSEE
Scraping à l’INSEE
Quand ?
- Le web scraping est utilisé en dernier recours, l’INSEE favorisera :
- Les accords avec des partenaires (ex : seloger.com)
- L’utilisation d’API (ex : Qwant, Yahoo Finance)
- Les sources de données publiques
- Le web scraping devient cependant une source de données grandissante.
Scraping à l’INSEE
Utilisation
Le scraping est notamment utilisé pour le calcul des indices des prix :
- Prix des transports (trains via site de la
SNCF, domaine maritime) ;
- Prix de produits divers (surtout de l’électronique) ;
- Prix dans le domaine de l’hôtellerie (avec
booking.com).
D’autres utilisations ponctuelles peuvent également être faites.
Scraping à l’INSEE
Organisation
- Un scraping encore par cas d’usage, avec une gestion plus globale en cours de maturité
- Objectif de mutualisation entre les équipes statistiques
- La logique open source comme moyen de mutualisation
- Beaucoup de
Python, un peu deRet deJava
Cas d’usage à l’INSEE
Les prix dans le domaine de l’hôtellerie (Booking.com)
Références
- Un travail ayant donné lieu à une publication
- Adrien Montbroussous, Camille Freppel and Ombéline Guillon, “Web scraping of a booking platform: exploring new data and methodology for the hotel service consumer price index”, Paper for the 17th International Conference of the Ottawa Group, Rome
- Une présentation plus accessible ici
Les prix dans le domaine de l’hôtellerie (Booking.com)
Le code
But : collecter davantage de données pour calculer au mieux les indices d’évolution de prix pour l’hôtellerie.
La partie ‘scraping’ du projet est disponible ici.
Pour plus d’informations, contacter (INSEE).
- La conférence associée aux présentations : ici
- D’autres projets similaires de scraping mentionnés
Ventes d’articles électroniques
- But : collecter davantage de données pour calculer au mieux les indices de prix associés au secteur
- Projet encore à une étape expérimentale
- Scraping de Rue du Commerce : ici
- Pour plus d’informations, contacter (INSEE).
Scraping de la SNCF
Contexte
- Le calcul de l’IPC tient compte de :
- L’indice des prix des trains Grandes Lignes
- Le transport des passagers en train
- Les prix utilisés étaient fondés sur un document publié annuellement par la SNCF. Mais cette méthode :
- Ne reflète pas les variations infra-annuelles réelles, en particulier pour les TGV
- Ne reflète pas les prix effectivement payés par les consommateurs
- Ne suit pas les recommandations des institutions internationales
Scraping de la SNCF
Introduction du webscraping
- Sous forme expérimentale depuis 2018, indices publiés depuis 2020
Collecte quotidienne pour capter la volatilité des prix
Requêtes effectuées pour plusieurs couples origine-destination, types de train, antériorités, profils passagers et horaires
Près de 23 000 requêtes par nuit
- Un important travail statistique avec les données ainsi obtenues s’ensuit.
- Stratification en cellules homogènes de prix
- Un micro-indice calculé par cellule
- Agrégation des micro-indices avec un indice de Laspeyres arithmétique
Scraping de la SNCF
Comparaison des résultats
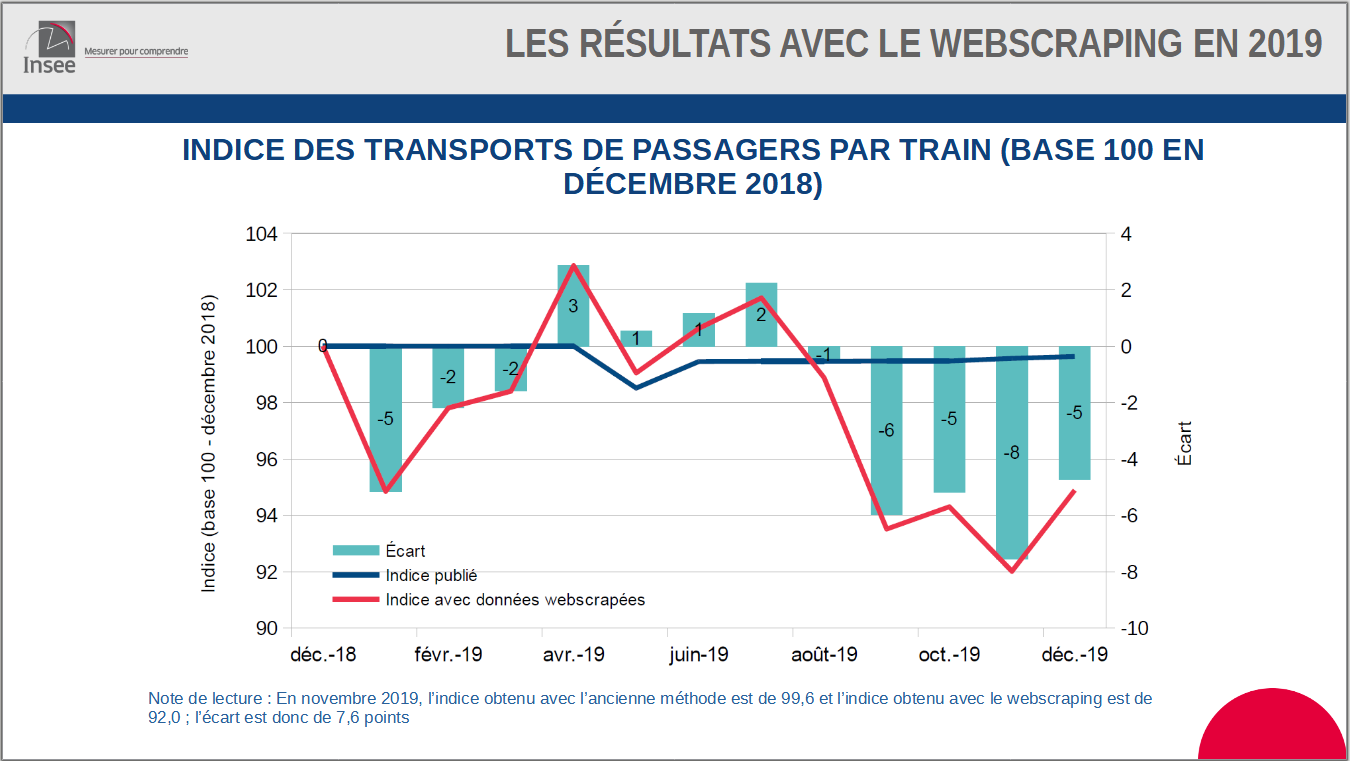
D’autres ressources pour le scraping lié à l’IPC
- Guidelines d’Eurostat sur le scraping lié à l’indice des prix à la consommation
- Annexe 3 consacrée aux travaux de l’INSEE sur Boulanger et Rue du Commerce
IV. D’autres organisations adeptes de scraping
IV. Sommaire
Le scraping chez Eurostat
Les investissements d’Eurostat en web scraping
Eurostat investit dans divers projets communs nommés ESSnets.
“An ESSnet project is a network of several
ESSorganisations aimed at providing results that will be beneficial to the wholeESS.”
- Parmi ces investissements, plusieurs liés aux nouvelles sources de données, dont le web scraping.
- ESSnet Big Data I & II
- Trusted Smart Statistics – Web Intelligence Network
Une continuité de projets
3 ESSnets dans la continuité les uns des autres :
- Big Data I de février 2016 à mai 2018
- Big Data II de novembre 2018 à juin 2021
- Le Web Intelligence Network (
WIN) d’avril 2020 à mars 2025- Le
WINfait notamment la promotion du Web Intelligence Hub (WIH), dédié au thème de l’acquisition et l’utilisation de nouvelles données venant du Web. - Ce sont 17 organisations de 14 pays européens qui travaillent ensemble.
- Le
Un découpage en work packages
Ces ESSnets couvrent une variété de projets. Ceux-ci sont organisés par work packages, chacun avec ses propres objectifs.
- L’INSEE est engagé dans les work packages 3 et 4.
Cas d’usage d’Eurostat
Le work package 2 du WIN
- Il y a notamment deux gros projets de web scraping qui se sont poursuivis dans ces ESSnets :
- Online Job Advertisements (
OJA)- Aussi appelé Online Job Vacancies (
OJV)
- Aussi appelé Online Job Vacancies (
- Online-Based Enterprise Characteristics (
OBEC)
- Online Job Advertisements (
- Les deux projets faisaient également partie du ‘Implementation Track’ de l’ESSnet Big Data II.
BREAL: Big data REference Architecture and Layers
Au sein du même track, on pourra aussi citer le projet ‘Process and architecture’, qui a donné naissance au BREAL.
Cela représente désormais le work package 4 du WIN. Tous les rapports disponibles ici.
Online Job Advertisements
Contexte
- Besoin de statistiques sur les offres d’emploi les plus à jour possible pour adapter les politiques d’emploi et d’éducation
- Les offres d’emploi étant de plus en plus en ligne, collecter ces données sur Internet devient particulièrement intéressant
- Les collectes de données traditionnelles sur les offres d’emploi sont assez peu efficaces
- Le web scraping estimé comme la solution la plus appropriée pour obtenir des données les plus complètes possible
Online Job Advertisements
Avantages du web scraping
- Possibilité de passer de données trimestrielles à des données journalières
- Sur les sites d’offres, celles-ci sont souvent déjà découpées par secteur, région, niveau d’éducation…
- Réduire le fardeau de réponse des entreprises
Online Job Advertisements
Quelques challenges (1/2)
- Bien définir le champ d’étude, par exemple restreindre aux secteurs avec une offre en grande partie en ligne
- Dédoublonner les offres présentes sur plusieurs plateformes (ex : les champs différant légèrement d’un site à l’autre à offre égale)
- Traiter à la fois des données structurées et non structurées (selon les sites)
- Savoir travailler avec les différents niveaux de détail ou unités de mesure qu’offre chaque site
Online Job Advertisements
Quelques challenges (2/2)
- Gérer la qualité variable des données et les erreurs de scraping qui pourraient ressortir
- Bien respecter les règles en vigueur pour chaque site et pays au sujet du web scraping
- Gérer l’aspect temporel :
- Comparer les données du jour A à celles collectées la veille
- Évaluer la durée de validité des offres
- Gérer la représentativité des données
OJAet le fait qu’il manque beaucoup d’offres non publiées en ligne
Online Job Advertisements
Méthodes utilisées
- Scraping de nombreux sites d’offre d’emploi
- Méthodes poussées de NLP :
- Détection des langues
- Normalisations des textes
- Déduplications
- Classification par Machine Learning
Online Job Advertisements
Conclusions
- En France, la DARES (Ministère du Travail) participe à ce travail.
Online-Based Enterprise Characteristics
Le principe
“The aim of WPC [Work Package C] is to use web scraping, text mining and inference techniques for collecting and processing enterprise information, in order to improve or update existing information, such as Internet presence, kind of activity, address information, ownership structure, etc., in the national business registers.”
Autrement dit, de nombreux sites d’entreprises sont scrapés afin d’en extraire des informations complémentaires aux enquêtes menées par les INS dans chaque pays.
Les différentes étapes d’OBEC
1- Politique de web scraping
- Le projet impliquant le scraping de nombreux sites dans plusieurs pays, il y a un fort besoin de transparence.
- Outre la visibilité du projet, le
RGPDajoute un certain nombres de contraintes.
- Une politique sur l’usage du web scraping pour le projet a donc été rédigée et diffusée.
Les différentes étapes d’OBEC
2- Cadre méthodologique
- Cadrer le design du projet :
- Représentation de données, process et méthodes…
- Cadrer la phase de déploiement :
- Infrastructure, étapes de data processing…
- Réfléchir au cycle de vie du projet en fonction du GSBPM
Les différentes étapes d’OBEC
3- Expérimentations
- Production de statistiques expérimentales en utilisant les méthodes d’
OBEC:- Collecte d’URL, présence sur les réseaux sociaux, activité en ligne, e-commerce…
- 7 pays volontaires, les rapports et résultats ici
- Les résultats obtenus sont une vitrine d’
OBEC… - Mais ne peuvent pas encore être considérés comme des statistiques officielles
- Les résultats obtenus sont une vitrine d’
Les différentes étapes d’OBEC
4- Starting Kits
Afin que chaque INS puisse mettre en application les méthodes mises en place lors du projet, un starting kit est disponible en open source.
Le deliverable associé au starting kit
Le code source sur
Github
Les différentes étapes d’OBEC
5- Evaluation de la qualité des résultats
- S’assurer de la qualité des résultats pour passer de la phase expérimentale à la mise en production par les INS
- Derniers documents publiés en Novembre 2020, travail poursuivi aujourd’hui avec le
WIN
Quelques leçons tirées du scraping pour OBEC
| Problème rencontré | Réponse à adopter |
|---|---|
| Liste d’URL non à jour | Lancer un crawling pour vérifier validité des liens |
| Le robots.txt interdit le scraping de tout contenu | Notifier le site plus en amont de la collecte |
| Site temporairement indisponible | Essayer de scraper le site à des moments différents |
| Pas d’horodatage sur le site | Scraper le site régulièrement et comparer les sorties |
| Informations extraites du site insuffisantes | Le site a pu évoluer : revoir le code du scraping |
Web scraping dans un INS - Quelques interlocuteurs
Le Web Intelligence Network
- Présents sur plusieurs media :
- Souhaitent également communiquer auprès d’INS hors Europe
- Un calendrier très complet d’événements, de webinaires…
- Dernier webinaire le 23/11 sur le work package 4 : “BREAL et user stories”, qualité et méthodologie
Pour reprendre les mots du WIN …
The target audience for the WIH are organisations that produce national statistics and want to modernise the production of national statistics and are looking for:
- Exploring new and emerging data sources
- Building competences
- Building and strengthening collaborations
- Developing new frameworks
- Adopting new practices
Les webinaires du WIN des prochains mois
- Début 2023 :
- “Web Scraped Data to Enhance the Quality of the Statistical Business Register”
- “Method of Processing and Analysing Web Scraped Tourism Data”
- “Web Intelligence in Practice. How to use content form the web for enterprise statistics?”
- Mi 2023 :
- “Web Scraping of Real Estate Portals”
- Davantage d’informations à venir pour la suite
L’INS du Royaume-Uni : l’ONS
- Un blog consacré à la data science alimenté régulièrement
- Prompts à multiplier les partenariats
Quid de recourir à des acteurs privés spécialisés ?
- Il existe de nombreuses entreprises proposant des services de scraping.
- En revanche, aucune garantie que les guidelines présentées soient appliquées.
- Possibles problématiques de transparence sur la collecte.
Ce n’est donc pas une recommandation. Ce n’est ni une pratique à l’INSEE ni à Eurostat.
V. Conclusion
Le mot de la fin
- Le web scraping est une nouvelle source de données très prometteuse.
- Les cas d’usage sont nombreux, y compris pour les INS.
- En revanche attention, même à des fins statistiques, tout n’est pas permis.
- Bien respecter les bonnes pratiques.
- Un réseau d’interlocuteurs à disposition
- A travers le
WINou entre INS
- A travers le
Remerciements aux contributeurs
- Lino Galiana, INSEE
- Romain Lesur, INSEE
- Romain Avouac, INSEE
Le code source de la formation sur Github accessible ici
Merci pour votre attention !
Des questions ?
Comment utiliser le SSP Cloud ?