Bonnes pratiques pour les projets statistiques
Une formation aux bonnes pratiques avec Git et R
Insee
Insee
Introduction
- Version pour les manageurs de la formation aux bonnes pratiques avec et

Retour à la page d’accueil pour explorer les autres versions
Plan
- Messages principaux de la formation aux agents
- Présentation des enjeux avec des exemples concrets
- Qualité et structure des projets
- Pourquoi et comment faire du bon ?
- Format et sécurité des données
- Ouverture à l’open source
Introduction
Pourquoi les bonnes pratiques ?
Origine : communauté des développeurs logiciels
Constats :
- le “code est plus souvent lu qu’écrit” (Guido Van Rossum)
- la maintenance d’un code est très coûteuse
Conséquence : un ensemble de règles informelles, conventionnellement acceptées comme produisant des logiciels fiables, évolutifs et maintenables
Pourquoi intéresser les statisticiens aux bonnes pratiques ?
L’activité du statisticien / datascientist tend à se rapprocher de celle du développeur (notion de citizen developers) :
projets intenses en code
projets collaboratifs et de grande envergure
complexification des données et donc des infrastructures
déploiement d’applications pour valoriser les analyses
Pourquoi intéresser les managers aux bonnes pratiques ?
- Projets en production (automatisée ou ponctuelle) impliquent:
- La coordination entre plusieurs acteurs (aux niveaux techniques différents)
- La répétition d’opérations dans le temps
- Des évolutions sur des maillons de chaînes, sans la déstabiliser
- Le tout dans un environnement changeant (données, infrastructures, équipes…)
- Bonnes pratiques ( et ): manière de réduire le poids de la maintenance
- Sans brider la phase d’expérimentation
- Erreur de ne pas penser ensemble les enjeux organisationnels, humains et techniques
- Derrière le sujet technique, opportunité pour faire évoluer l’organisation…
- … pour produire des statistiques plus nombreuses, de meilleure qualité, en souffrant moins
eedd
Enjeux de la formation bonnes pratiques
Un point de départ commun
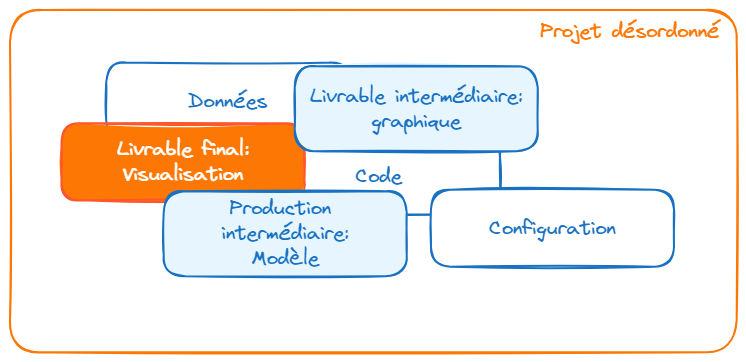
Enjeux de la formation bonnes pratiques
Un point de départ commun
L’horizon désirable
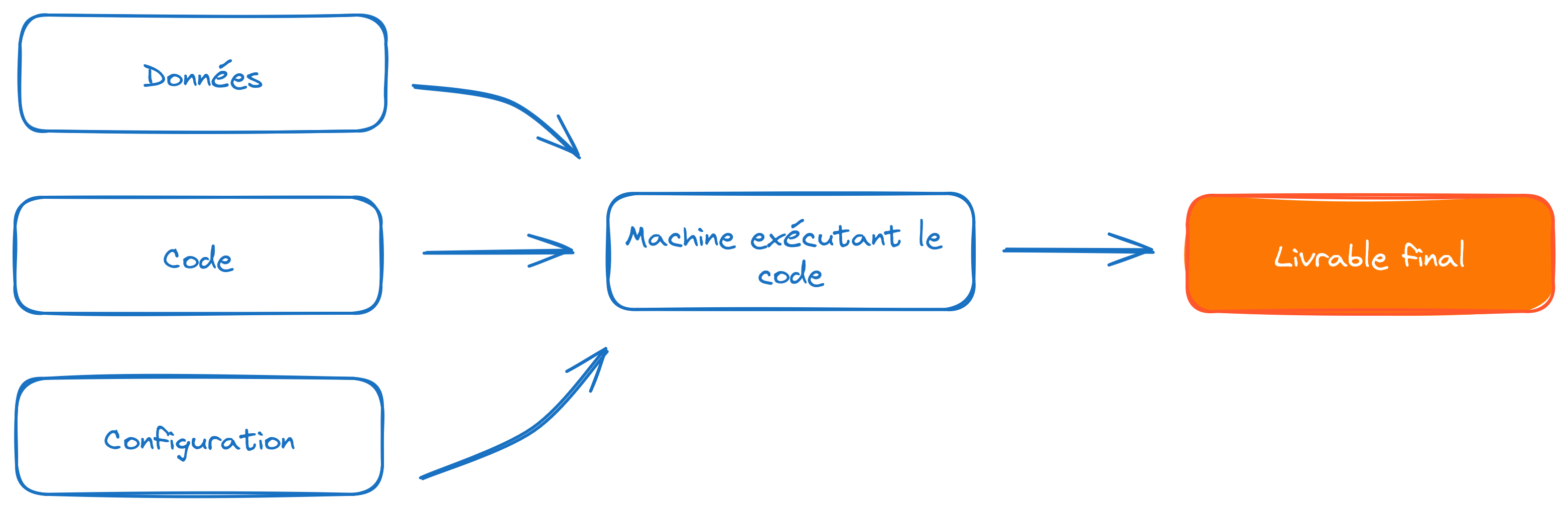
Messages clés de la formation aux agents
Des standards communautaires qui favorisent la reproductibilité et la maintenabilité
De multiples outils pour simplifier leur mise en oeuvre
Un coût d’autant plus faible que l’on se place en amont
Le mouvement de modernisation du self est l’occasion d’une montée en compétence collective
Lignes directrices de la formation aux agents
- 1️⃣ Versionner son projet pour historiciser et archiver proprement
- 2️⃣ Construire des codes de qualité (lisibles, reproductibles, auto-documentés…)
- 3️⃣ Adopter une structure modulaire et évolutive
- 4️⃣ Utiliser des formats de données adaptés
- 5️⃣ Comment construire des environnements reproductibles
- 6️⃣ Enjeux de la mise en production de projets statistiques
Ressources communautaires
Canaux de discussion
- À l’Insee
- Pour toute question sur Git : Insee-Git-Gitlab
- Pour toute question stat/self : Insee - Outils Stats v2
- Pour toute question spécifique à AUS/LS3 : Insee-DSI-Plateformes-Internes-Datascience
- Plus largement sur
- Sur
Tchap: Langage R (Tchap) - Sur
Slack: r-grrr
- Sur
- À l’Insee
Documentation
Formation : Espace formation du SSP Cloud
Réseau data science :
SSPHub
Illustration: l’élaboration d’une statistique
Le cas d’usage classique à l’Insee
Il faut distinguer deux types de processus de production :
celui qui est entièrement automatisé avec intervention humaine limitée ;
celui qui nécessite du travail humain et fait l’objet de tâtonnements :
- Données en entrée non stables ;
- Vérifications ex post non automatisables…
Beaucoup de processus sont dans la zone grise:
- Enjeu de définition de la notion de production
Qu’est-ce que la production ?
- Mettre en production : faire vivre un produit dans l’espace de ses utilisateurs
- Une base de données, une publication, une application…
- Notion simple mais mise en oeuvre compliquée !
- Insee: repose sur la séparation entre “production” et “libre service”
- Les deux sont de la production !
- La différence est dans le besoin de contrôle à façon
- D’où l’enjeu de structuration de la chaîne et des contrôles qualité
- Ouverture vers la validation de données et le data engineering
- Enjeu de l’automatisation dans un contexte de réduction des délais, de multiplication des demandes…
Pourquoi répond-il bien aux enjeux de la production ?
Exemple avec calcul du taux de pauvreté dans SRCV
Les tâtonnements supposent des allers et retours sur différentes hypothèses :
- prise en compte évolutive des phénomènes affectant l’indicateur (défiscalisation de revenus, nouvelles prestations sociales, etc.) ;
- production de différentes variantes que l’on veut pouvoir comparer les unes aux autres ;
- comprendre ce qui a été fait pour les précédentes productions, éventuellement qui a fait quoi.
Quels concepts ?
les variantes peuvent se décliner sous la notion de branches ;
en traçant l’ensemble des modifications du code, facilite la complète reproductibilité des tâtonnements ;
au travers de l’historique, il permet de retracer l’ensemble du cheminement ;
le
git blamepermet de voir qui a fait quoi ;mais cela nécessite une discipline sur l’usage de .
⇒ deux notions essentielles : reproductibilité et traçabilité
Gestion du cycle de vie d’un projet
Changement de paradigme : le code self doit être maintenu
- Changement de version de et des packages ;
- Quelles solutions connaissez-vous ?
renvet la notion de lockfileanticiper les montées de version des logiciels :
- on peut envisager un protocole pour cela
Gestion du cycle de vie d’un projet: renv
Exemple de renv.lock
Observer la composition de ce fichier (100 premières lignes)
renv.lock
{
"R": {
"Version": "4.3.3",
"Repositories": [
{
"Name": "CRAN",
"URL": "https://packagemanager.posit.co/cran/latest"
}
]
},
"Packages": {
"BH": {
"Package": "BH",
"Version": "1.84.0-0",
"Source": "Repository",
"Repository": "CRAN",
"Hash": "a8235afbcd6316e6e91433ea47661013"
},
"DBI": {
"Package": "DBI",
"Version": "1.2.2",
"Source": "Repository",
"Repository": "CRAN",
"Requirements": [
"R",
"methods"
],
"Hash": "164809cd72e1d5160b4cb3aa57f510fe"
},
"DT": {
"Package": "DT",
"Version": "0.33",
"Source": "Repository",
"Repository": "RSPM",
"Requirements": [
"crosstalk",
"htmltools",
"htmlwidgets",
"httpuv",
"jquerylib",
"jsonlite",
"magrittr",
"promises"
],
"Hash": "64ff3427f559ce3f2597a4fe13255cb6"
},
"KernSmooth": {
"Package": "KernSmooth",
"Version": "2.23-22",
"Source": "Repository",
"Repository": "CRAN",
"Requirements": [
"R",
"stats"
],
"Hash": "2fecebc3047322fa5930f74fae5de70f"
},
"MASS": {
"Package": "MASS",
"Version": "7.3-60.0.1",
"Source": "Repository",
"Repository": "CRAN",
"Requirements": [
"R",
"grDevices",
"graphics",
"methods",
"stats",
"utils"
],
"Hash": "b765b28387acc8ec9e9c1530713cb19c"
},
"Matrix": {
"Package": "Matrix",
"Version": "1.6-5",
"Source": "Repository",
"Repository": "CRAN",
"Requirements": [
"R",
"grDevices",
"graphics",
"grid",
"lattice",
"methods",
"stats",
"utils"
],
"Hash": "8c7115cd3a0e048bda2a7cd110549f7a"
},
"R6": {
"Package": "R6",
"Version": "2.5.1",
"Source": "Repository",
"Repository": "RSPM",
"Requirements": [
"R"
],
"Hash": "470851b6d5d0ac559e9d01bb352b4021"
},
"RColorBrewer": {Gestion du cycle de vie d’un projet
- Gérer le cycle de vie:
- du code
- de son environnement d’exécution
- des données mobilisées en entrée du projet et produites de manière intermédiaire.
- Définir responsabilités et organisation à la fois :
- sur la maintenance du code ;
- sur gitlab.insee.fr.
Qualité du code et structure des projets
Enjeux
D’une vision utilitariste du code à une vision du code comme outil de communication
Favoriser la lisibilité et la maintenabilité
Assurer la transparence méthodologique
La modularité pour éviter les monolithes
Les outils à recommander aux agents
Deux outils pratiques aident à respecter les standards :
- linter : programme qui vérifie que le code est formellement conforme à un certain guidestyle
- signale problèmes formels, sans corriger
- formatter : programme qui reformate un code pour le rendre conforme à un certain guidestyle
- modifie directement le code
Note
Il existe un guide de référence pour bien coder en : le Tidyverse style guide.
La modularité des projets
- Favoriser l’utilisation de fonctions
- Limite les risques d’erreur liés aux copier/coller
- Rend le code plus lisible et plus compact
- Unicité de la source de vérité
- Les packages
- Idéal pour favoriser la réutilisation du code
- Coût de maintenance élevé
Bien documenter
- Grands principes :
- Documenter le pourquoi plutôt que le comment
- Privilégier l’auto-documentation via des nommages pertinents
- Documenter le projet (contexte, objectifs, fonctionnement) dans un fichier
README- Quelques modèles : utilitR, DoReMIFaSol
Pourquoi et comment faire du bon Git ?
1️⃣ Archiver son code proprement
pour en finir avec ça :

1️⃣ Archiver son code proprement
ou ça :

1️⃣ Archiver son code proprement
ou encore ça :
prior <- read_csv(prior_path)
prior <- prior |>
select(id, proba_inter, proba_build, proba_rfl) |>
separate(id, into = c('nidt', 'grid_id'), sep = ":") |>
group_by(nidt) |>
mutate(
proba_build = proba_build/sum(proba_build),
proba_rfl = proba_rfl/sum(proba_rfl),
) |>
unite(col = "id", nidt, grid_id, sep = ":")
# Test
# prior_test <- prior |>
# mutate(
# proba_inter = round(proba_inter, 4)
# proba_build = round(proba_build, 4)
# proba_rfl = round(proba_rfl, 4)
# )
write_csv(prior_round, "~/prior.csv")1️⃣ Archiver son code proprement
Pour arriver à ça :
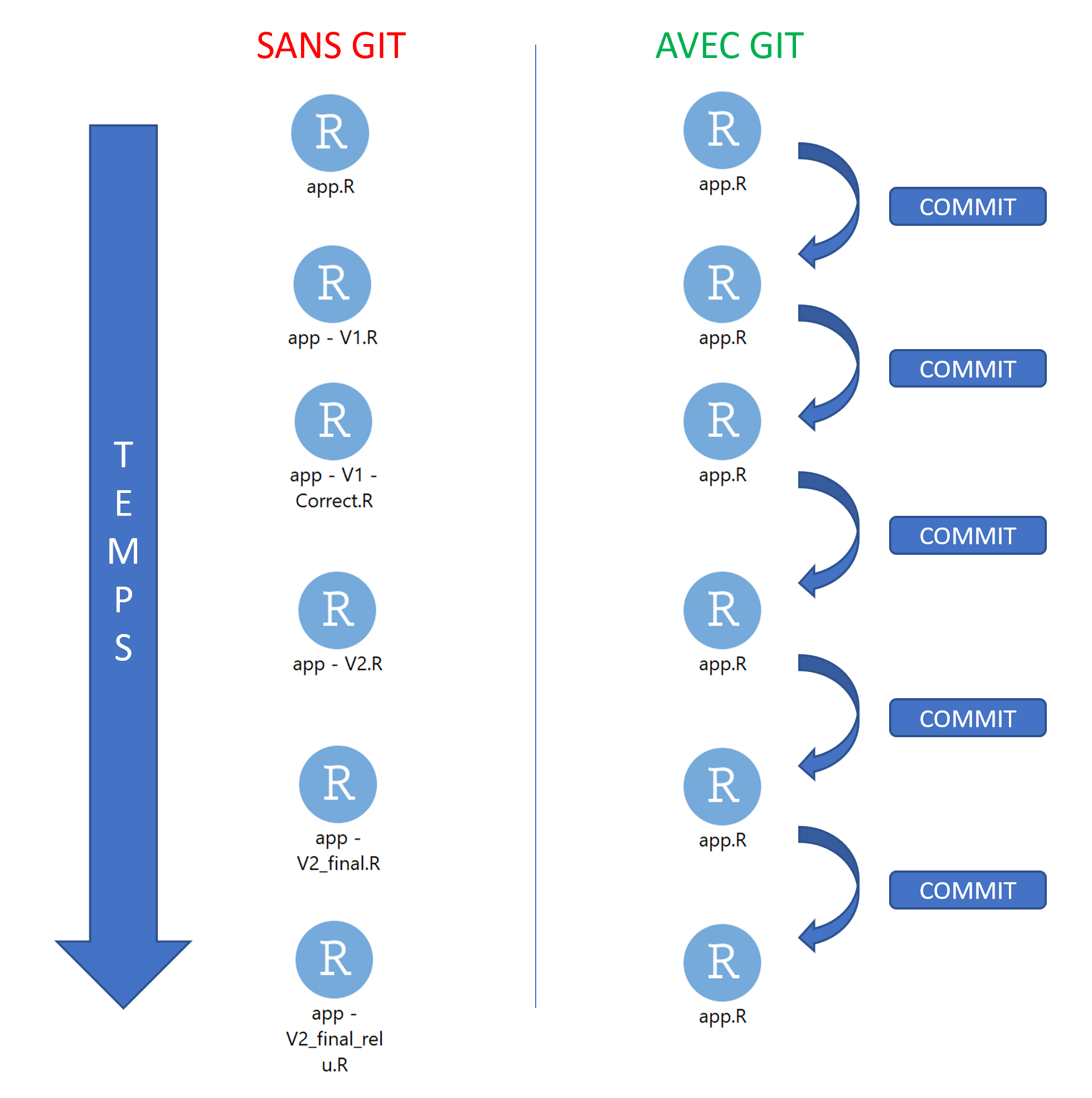
Source : ThinkR
2️⃣ Voyager dans le temps (de votre projet)
Concepts
Git, GitHub, GitLab… quelles différences ?
- est un logiciel ;
- Utilisation en ligne de commandes
- Différentes interfaces graphiques (
RStudio,VS Code…)
Concepts
Git, GitHub, GitLab… quelles différences ?
GitHubetGitLabsont des forges logicielles- Forge: espace d’archivage de code
- Des fonctionalités supplémentaires : réseau social du code
Astuce
GitHub: utilisation pour les projets open-sourceGitLab: utilisation pour les projets internes
Bonnes pratiques
Que versionne-t-on ?
- Essentiellement du code source
- Pas d’outputs (fichiers
.html,.pdf, modèles…) - Pas de données, d’informations locales ou sensibles
Bonnes pratiques
Format des commits
- Fréquence
- Aussi souvent que possible
- Le lot de modifications doit “avoir du sens”
- Messages
- Courts et informatifs (comme un titre de mail)
- Décrire le pourquoi plutôt que le comment dans le texte
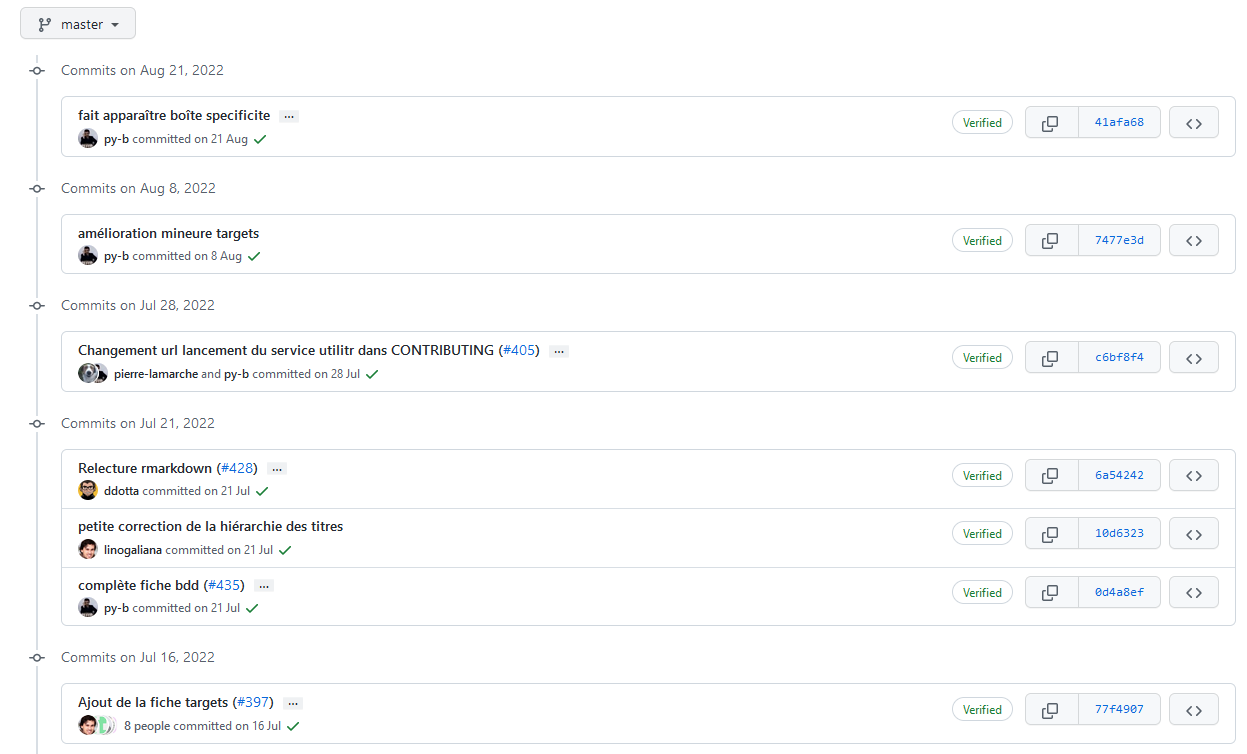
Ouverture vers la suite
Nous nous sommes concentrés sur la brique:
- “Code R”
- Mais besoin d’aller plus loin:
- “Code R” : besoin d’un environnement standardisé (
renv) - “Données”: enjeu du format et de la localisation (réseau, cloud, etc)
- “Configuration”: enjeu de la sécurité
- “Code R” : besoin d’un environnement standardisé (
Bonnes pratiques relatives aux données
Enjeux du choix d’un format
- Le choix d’un format de données répond à un arbitrage entre plusieurs critères :
- Finalité (traitement, analyse, diffusion)
- Public cible
- Volumétrie
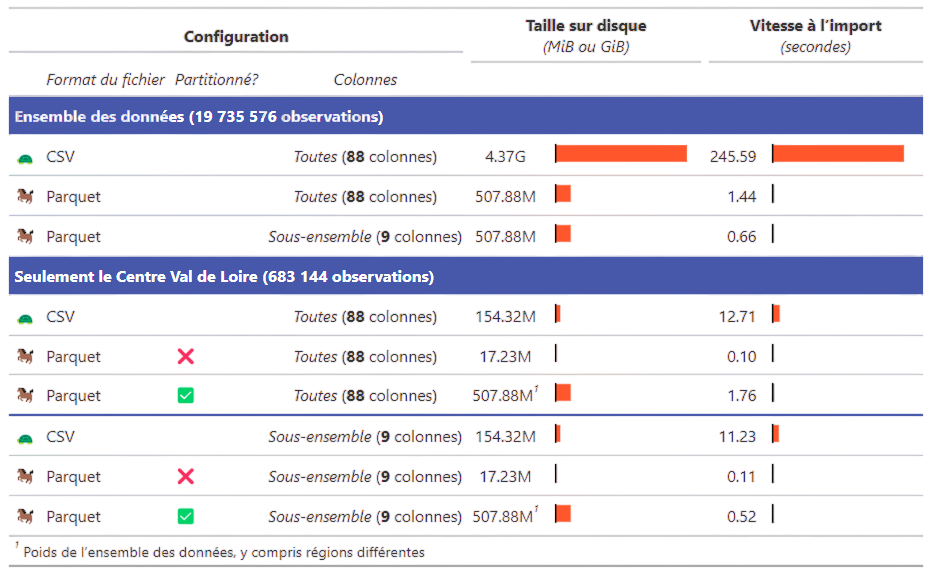
Recommandations de format
Eviter impérativement les formats de données adhérents à un langage (
RDS,RData,fst,sas7bdat, etc.).Deux formats à privilégier :
- CSV : pour la plupart des usages courants
- Avantage : non-compressé donc facilement lisible
- Inconvénients : pas de gestion des méta-données, peu adapté aux données volumineuses
- Parquet : pour le traitement de données volumineuses
- Compressé et très performant en lecture/écriture
- Gestion native des méta-données
- CSV : pour la plupart des usages courants
Recommandations de format
- Exemple sur les données du recensement:
Bonnes pratiques relatives aux données (suite)
La sécurité : question
Question
Quels sont, selon vous, les principaux risques de sécurité liés au développement en self ?
Risques 👮
- Mot de passe et jetons d’accès à des API
pas de mot de passe ni de jeton d’accès écrits dans le code - Risques sur les données :
- pas de données dans
- pas de compte d’accès commun à des bases de données
- pas de données sensibles en dehors des environnements protégés
Jetons d’accès à des API
- une solution à préférer au mot de passe (quand disponible)
- gestion fine des droits
- possibilité de révocation des jetons
- peuvent être limités dans le temps
- mais qui présentent des risques identiques aux mots de passe si les jetons ont des droits élevés
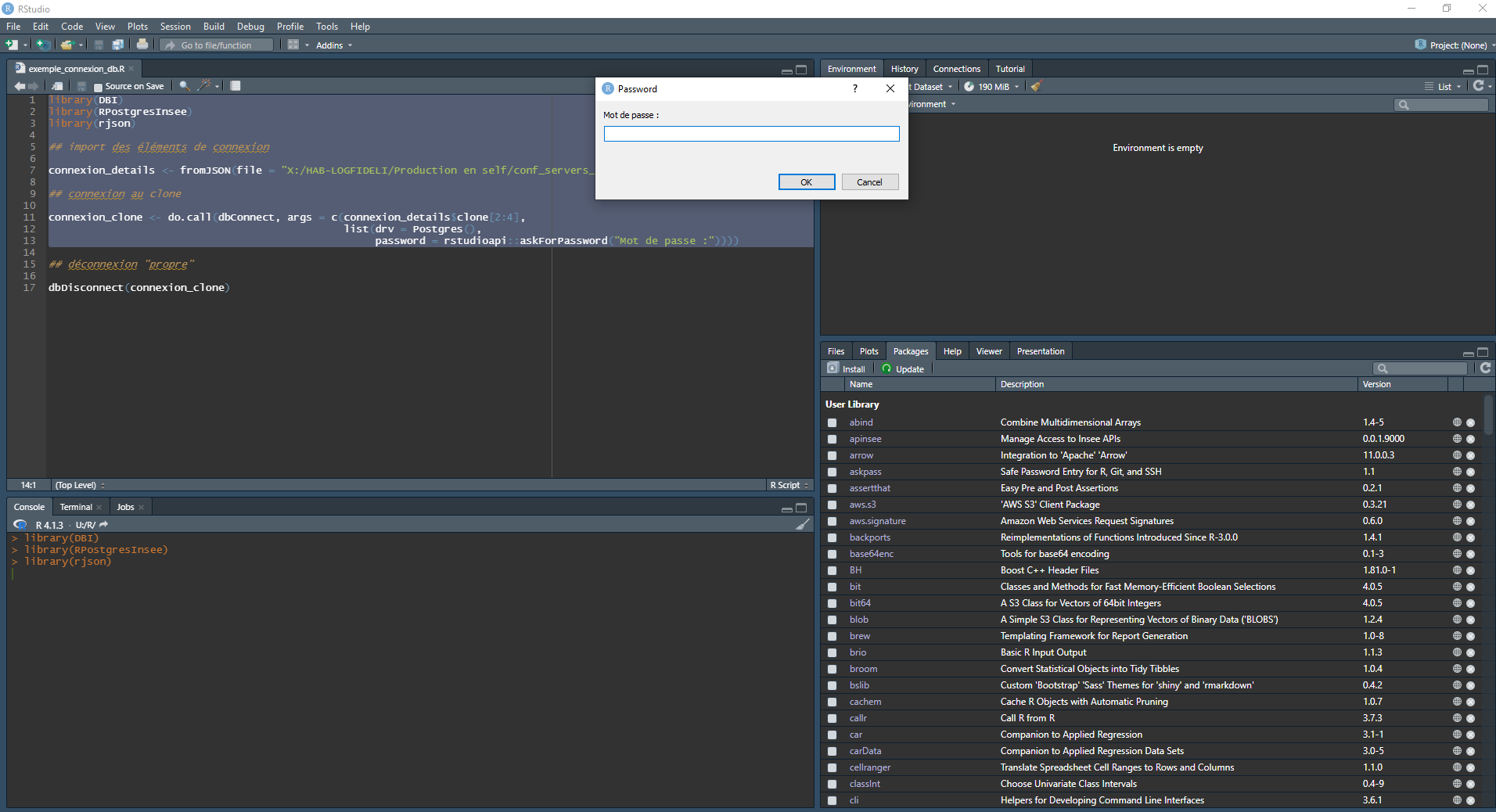
Les solutions concrètes pour les mots de passe
Notion de boîte de dialogue qui permet d’entrer le mot de passe sans l’inscrire dans le code
library(DBI)
library(RPostgresInsee)
library(rjson)
## import des éléments de connexion
connexion_details <- fromJSON(file = "X:/HAB-LOGFIDELI/Production en self/conf_servers_fideli.json")
## connexion au clone
connexion_clone <- do.call(dbConnect, args = c(connexion_details$clone[2:4],
list(drv = Postgres(),
password = rstudioapi::askForPassword("Mot de passe :"))))Résultat : un prompt qui récupère le mot de passe
A utiliser avec un gestionnaire de mots de passe
KeePass ![]() :
:
- disponible dans le centre logiciel
- simple d’utilisation
- les mots de passe sont stockés dans un fichier
.kdbxchiffré - les fichiers
.kdbxsont protégés par un mot de passe maître - une aide à la génération de mots de passe forts
Droits d’accès aux données
- ne pas utiliser de compte générique pour accéder à des bases de données :
- ne répond pas aux exigences de traçabilité
- ne répond pas aux exigences de révocation des droits d’accès
- préférer :
- des comptes individuels
- associés à une revue annuelle des droits
Stockage des données
- Données sous forme de fichier :
- ne pas les mettre sous (utiliser le fichier
.gitignore) - veiller à ce que les données sensibles ne prolifèrent pas.
- ne pas les mettre sous (utiliser le fichier
- Données dans des bases de données :
- toujours se poser la question de l’opportunité de les dupliquer sous forme de fichier
On préférera toujours avoir des données stockées dans un unique espace pour lequel les droits d’accès sont gérés individuellement.
Partie 5: Collaboration et ouverture
Quelques questions pour commencer
- Pour limiter les risques de sécurité, vaut-il mieux cacher son code à ses collègues ?
- Quelle est la nature juridique des codes sources réalisés à l’Insee ?
- , et leurs packages sont gratuits, comment est-ce possible ?
- Connaissez-vous la science ouverte et ses standards ?
La sécurité par l’obscurité
- Postulat : si on conserve ses codes sources secrets alors les failles de sécurité seront plus difficiles à détecter
- Ce postulat s’est avéré faux :
- des failles de sécurité sont en permanence détectées dans des logiciels propriétaires
- cela revient à cacher la fiabilité réelle des processus mis en oeuvre
- les logiciels open source sont examinés par de très nombreuses personnes et corrigés en cas de problème
Nature juridique des codes sources
- Les codes sources achevés (qui servent en production) ont le statut de document administratif
- Ils peuvent faire l’objet de demandes d’accès
- En cas d’accès, la publication doit se faire en open source
- Plutôt que de vérifier en catastrophe s’il y a des problèmes, autant s’y préparer au fur et à mesure
Différents niveaux d’ouverture possibles
- On peut déjà ouvrir les codes en interne au sein de l’Insee :
- meilleure compréhension mutuelle des travaux
- associé à GitLab, un cadre idéal pour la collaboration et la mutualisation
Différents niveaux d’ouverture possibles
- Au-delà, la publication de certains projets en open source permet de valoriser le savoir-faire de l’Insee :
- Packages :
disaggR,btb,RJDemetra… - Eurostat systématise l’open source pour les travaux européens
- une nécessité pour ne pas passer pour un passager clandestin vis-à-vis des communautés open source
- un moyen d’assurer la transparence de nos méthodes (cf. code des bonnes pratiques et les standards de la science ouverte)
- Packages :
L’ensemble des bonnes pratiques qui ont été présentées sont issues de l’open source.
Bonnes pratiques pour les projets statistiques (retour au site principal ; )
Comment faire de la gestion de projets avec
Gitlab?Gitlab!