Besoins techniques et organisationnels
BCEAO - Jour 1
25 septembre 2023
L’enjeu de la reproductibilité

Source : Peng R., Reproducible Research in Computational Science, Science (2011)
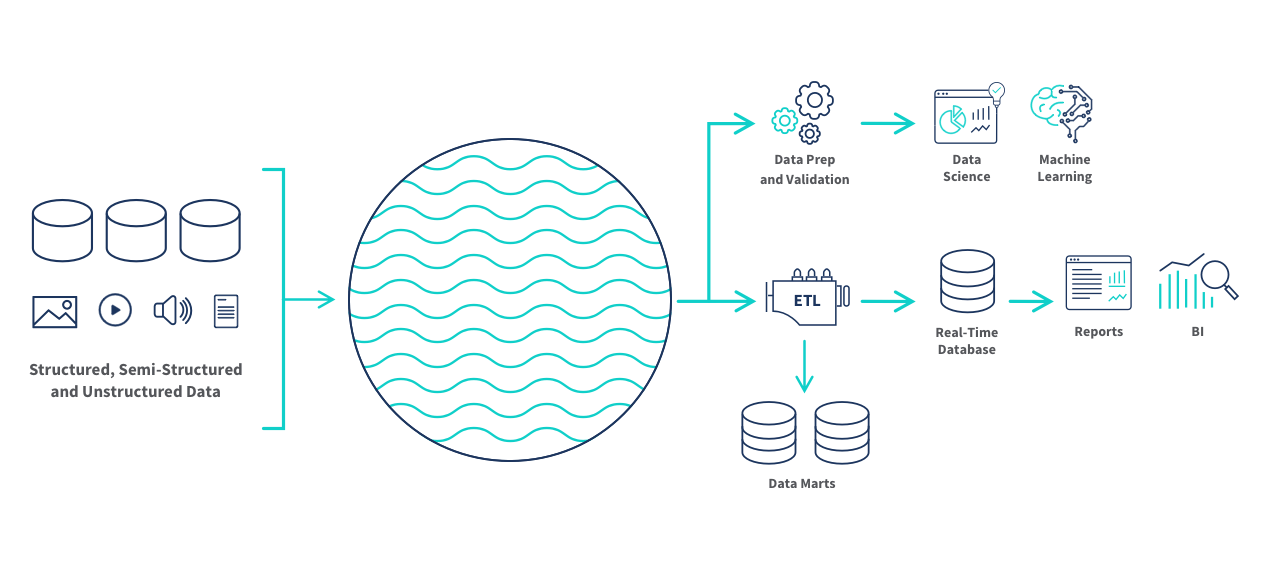
Stockage : le data lake
- Un stockage peu coûteux fait pour des données
- volumineuses
- brutes
- issues de sources variées
Le choix du stockage objet
Choix du stockage objet (type S3) vs. Hadoop
La co-localisation des traitements n’est plus justifiée
- Plus besoin de puissance/IA que de big storage
- Découplage stockage/traitement -> évolutivité
- Coûts de maintenance

Le choix de la conteneurisation
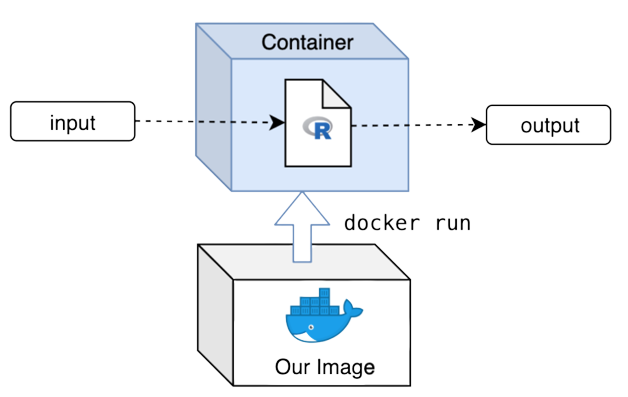
- Standard pour la data science
- autonomie
- reproductibilité
- scalabilité
- Orchestrateur : Kubernetes
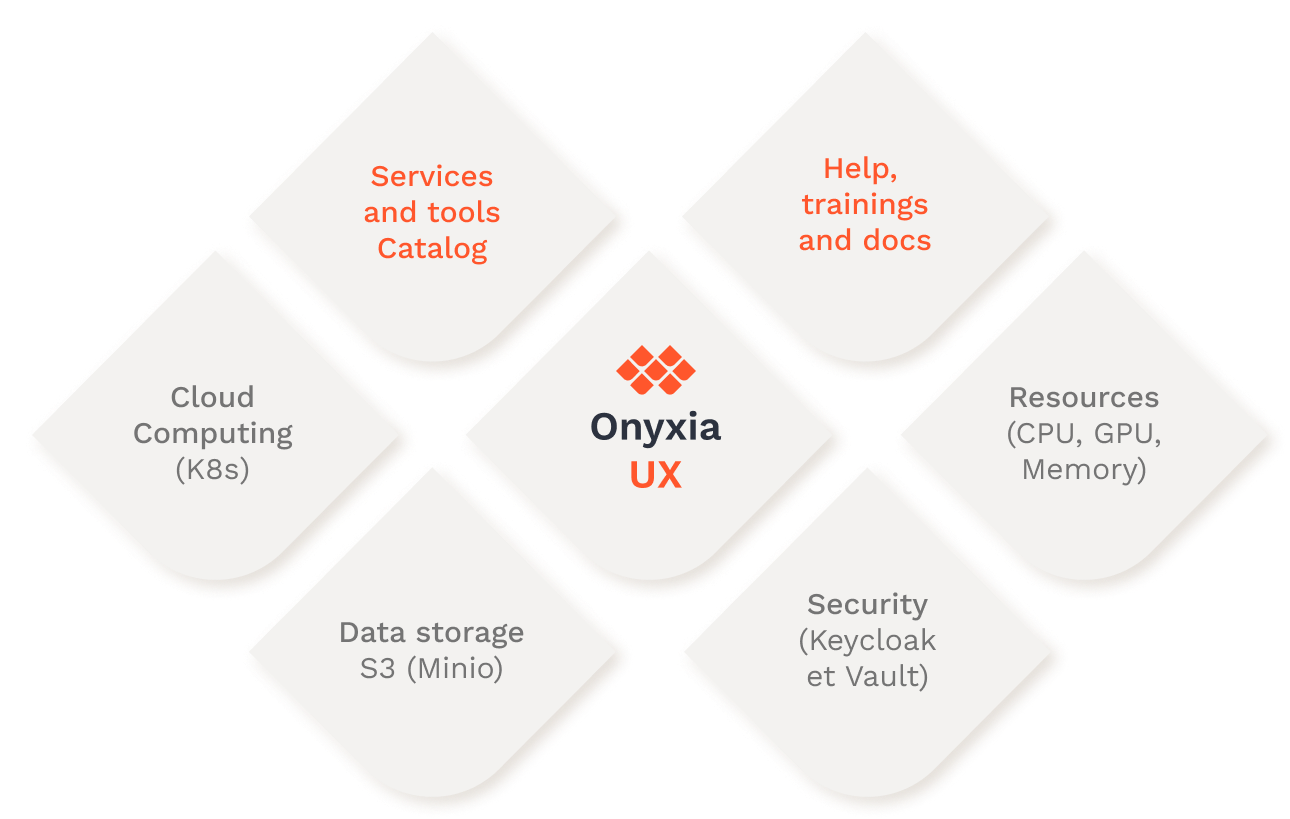
Une plateforme de data science
- Les choix techniques ne suffisent pas
- Les technologies cloud sont difficiles d’accès
- Une interface web comme liant technique
Langages de programmation
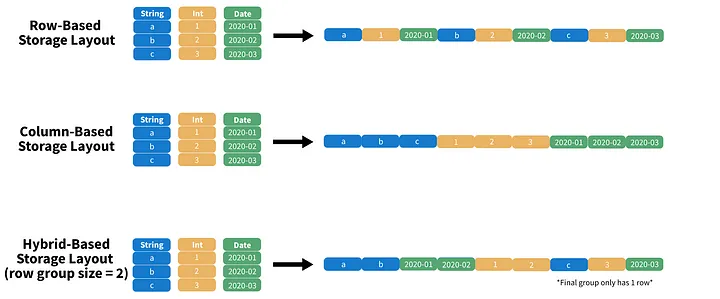
Modes de stockage
- Le stockage hybride optimise la lecture
- Projection (
SELECT) : orientation colonne - Predicates (
WHERE) : orientation ligne
- Projection (
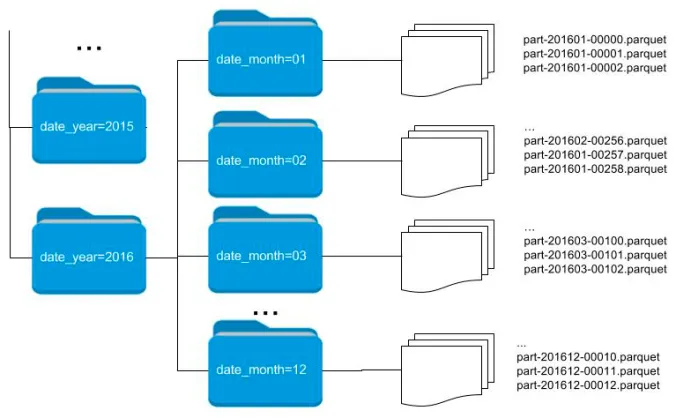
Le format Parquet : partionnement
- Division en blocs des données selon un critère
- Optimise la lecture pour certaines queries
Arrow
- Format de données en mémoire, orienté colonne
- Optimisé pour les traitements analytiques
- Pas nécessaire de charger toutes les données en RAM
- Interopérable et standardisé
![]()
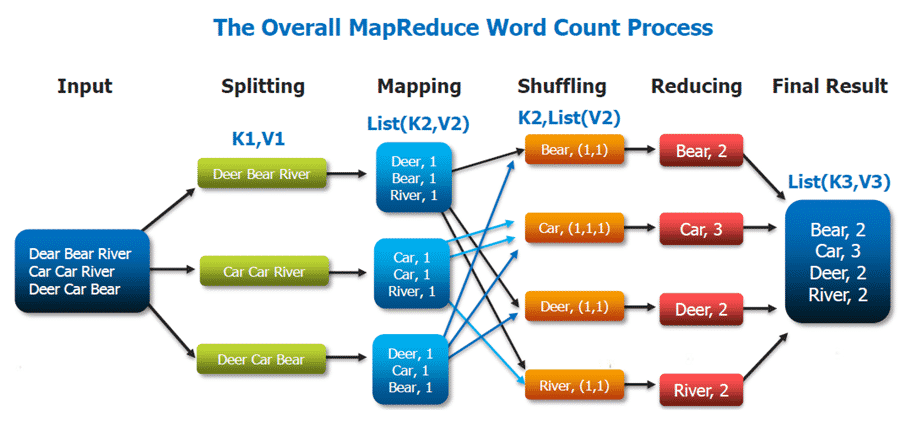
Hadoop MapReduce
Développé par Google (2004)
Popularisé par l’implémentation open-source d’Hadoop
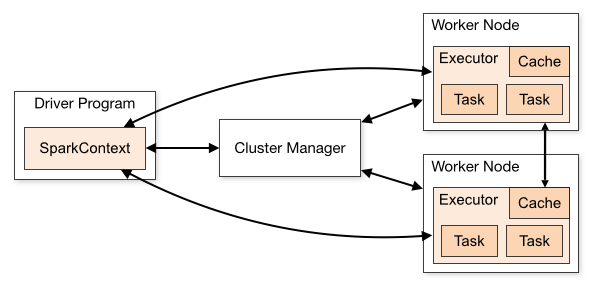
Apache Spark
- Démocratisation du calcul distribué
- Abstraction des opérations MapReduce
- Vitesse d’exécution (RAM vs. disque)
Catalogue de services d’Onyxia
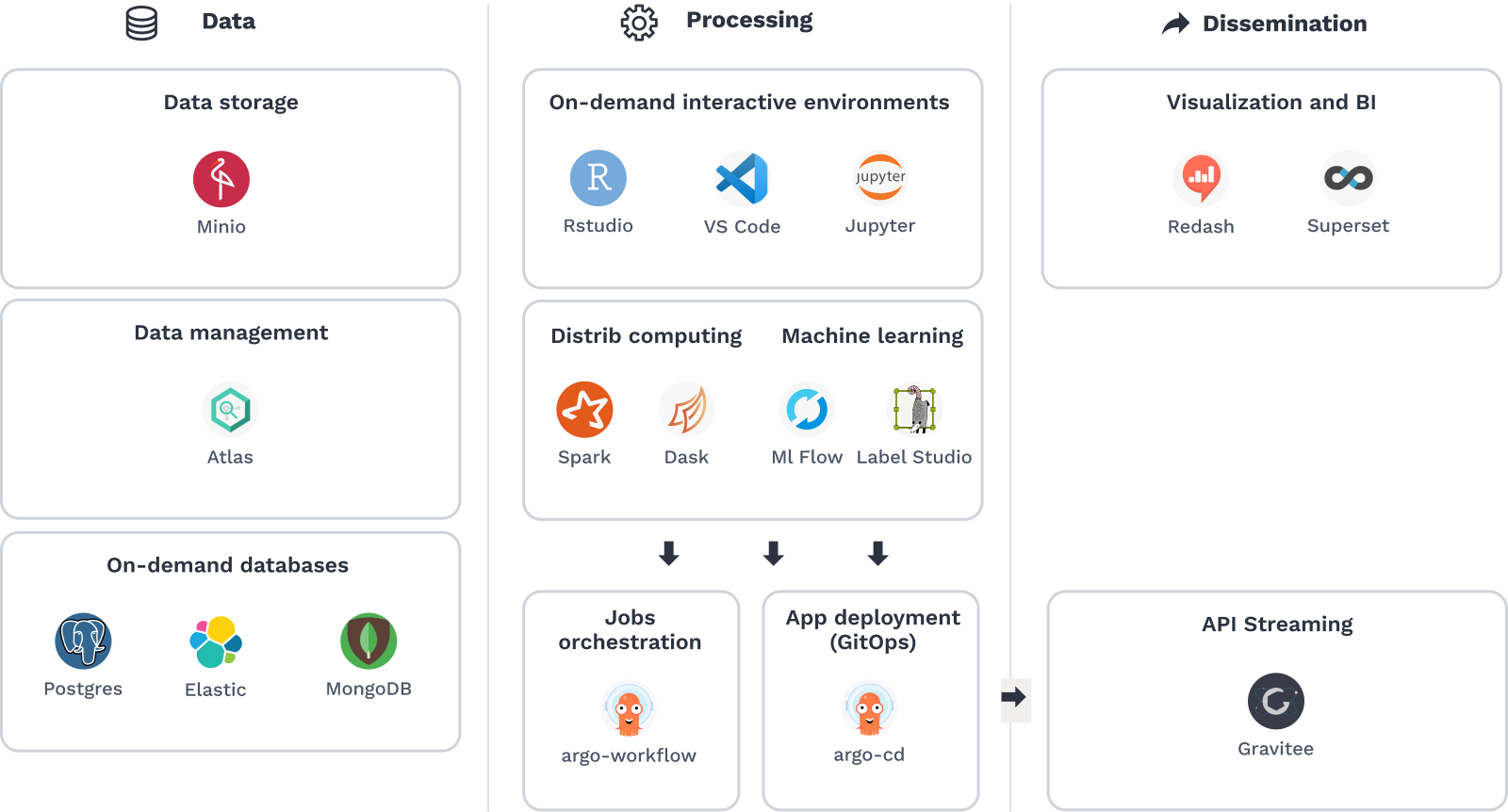
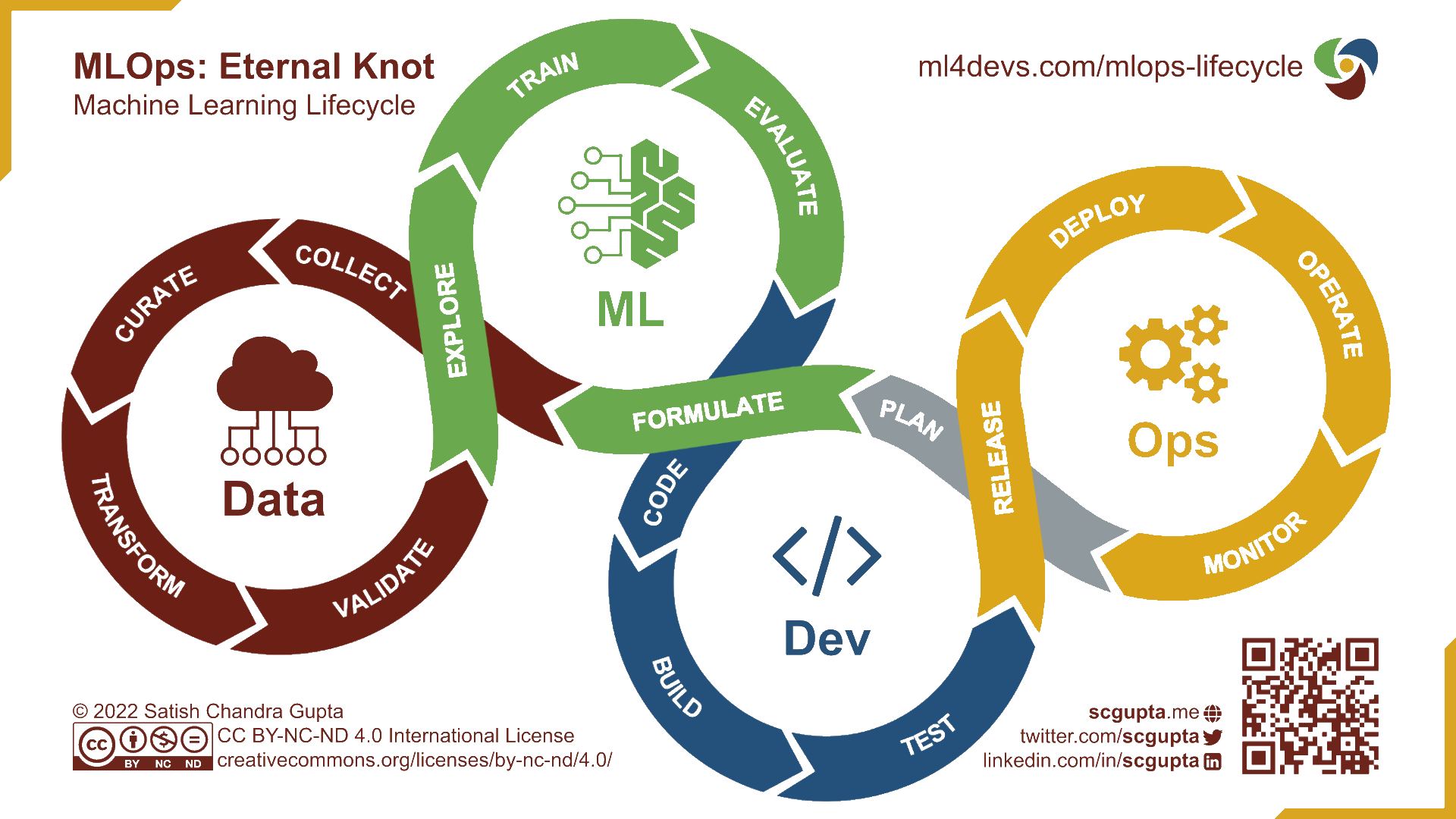
Approche MLOps
- Besoin de trouver des organisations hybrides
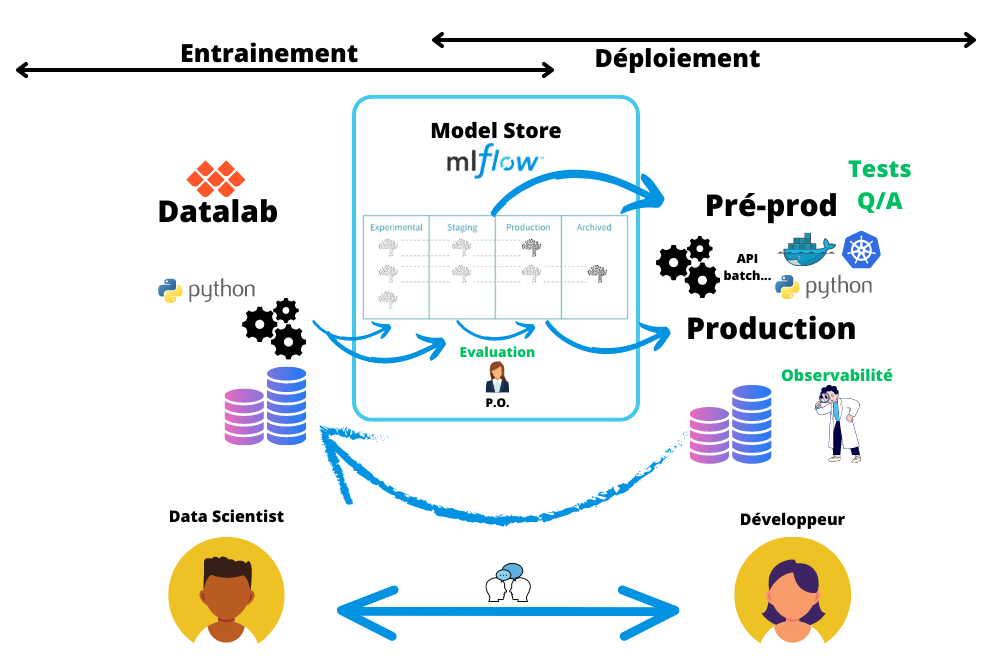
Organisation d’un projet
Comment construire une data stack pertinente ?