Place et enjeux liés au big data à l’Insee
BCEAO - Jour 1
25 septembre 2023
Introduction
Qui sommes-nous ?
- Thomas Faria
- SSP Lab : innovation en méthodologie statistique
- Romain Avouac
- DIIT : innovation informatique
Contexte de cette formation
Coopération internationale
Discussion autour de la stratégie big data de l’Insee
- Retours d’expérience
- “learning by doing”
Partage de connaissances sur le long terme
Le potentiel des big data
Big data : de quoi parle-t-on ?
- Des données “nouvelles” aux contours flous
- enregistrements automatiques (GSM, géolocalisation, capteurs..)
- contenus internet (webscraping, réseaux sociaux..)
- images satellites
- etc.
Big data : une définition
Big data : “Gestion et analyse d’un volume massif de données, souvent à une échelle bien supérieure à ce que les systèmes traditionnels peuvent traiter efficacement.”
Les 3 V qui caractérisent les big data :
- Volume : quantités massives de données
- Vitesse : haute fréquence, jusqu’au temps réel
- Variété : diversité de sources et de formats
Un phénomène pérenne
- Un phénomène en expansion constante
- Part du secteur numérique
- Capacités techniques
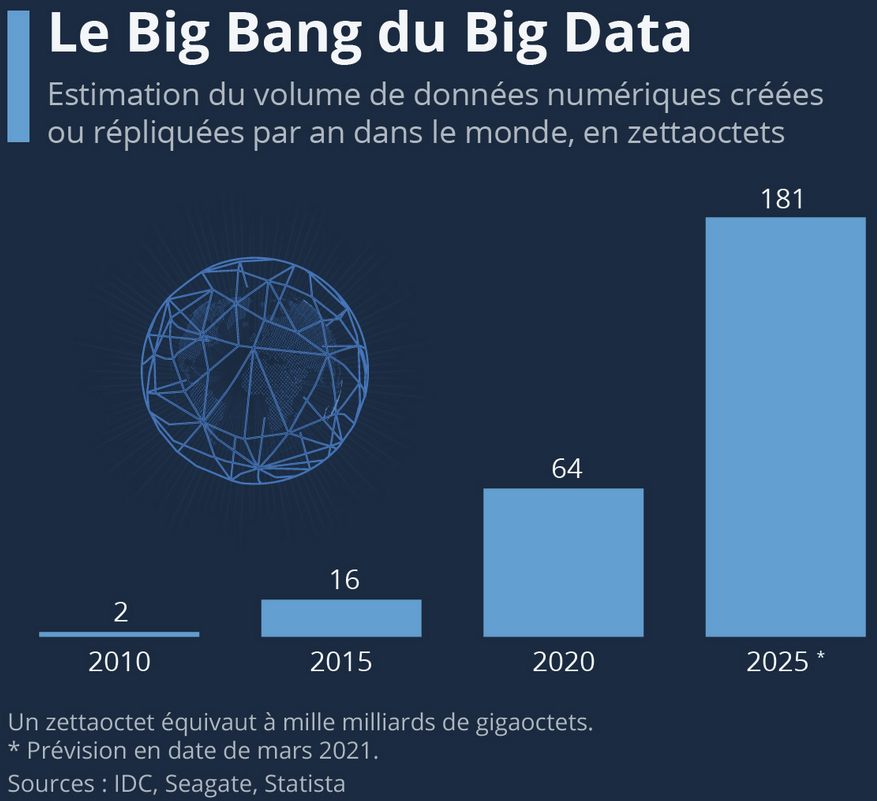
Pourquoi s’intéresser à ces données ?
Disponibilité : réduction du coût et de la charge des enquêtes, des délais de publication (ex : nowcasting)
Finesse : statistiques localisées, sur des sous-population, plus fréquentes…
Avancées méthodologiques : convergence entre statistique et informatique (machine learning)
Exhaustivité : compléter des déclarations d’enquêtes, créer de nouveaux indicateurs…
Un retour de l’exhaustif ?
- Pré-XXe siècle : règne quasi-exclusif de l’exhaustivité
- Recensements agricole, démographique, industriel
- XXe siècle : lent recul de l’exhaustivité au profit de l’échantillonnage
- 1934 : article de référence sur la théorie des sondages (Neyman)
- Développement des panels, études d’opinion, grandes enquêtes
- Fin XXe et début XXIe siècles : retour en grâce de l’exhaustif ?
Début des réflexions des INS européens
Mémorandum de Scheveningen (2013) : task force européenne sur le potentiel des big data
Groupe de travail de l’UNECE (2014-2015) : “sandbox” pour manipuler des données concrètes
ESSNET Big Data I (2016-2018) et II (2019-2021)
- Préparer l’intégration des big data à la production statistique officielle
- “Projets pilotes” sur une variété de sujets
- Nombreuses ressources
Début des expérimentations à l’Insee
2015 : projet données de caisses
- Groupe CNIS sur l’accès aux données privées
2016 : poste de statisticien sur les big data
2016 : début de l’exploitation des données mobiles
- “Partenariat” informel avec l’opérateur Orange
- “Travaux méthodologiques”
2018 : labs et premiers développements d’une “plateforme big data”
De nouveaux (?) défis
Des enjeux multiples
Démocratique
Législatif
Économique
Méthodologique
Technique
Confiance
- Des données généralement recueillies par des acteurs privés
- Comment garantir la confiance des citoyens ?
- Deux approches complémentaires
- Juridique : établir des garde-fous juridiques
- Technique : méthodes de confidentialité
Cadre législatif
- Un cadre législatif largement existant
- Secret statistique (1951)
- Traitement des données personnelles et sensibles (1978)
- Généralisation européenne : RGPD (2016) et directive e-privacy
- De nécessaires adaptations
- La quantité et la variété des données facilite les ré-identifications
- Data act (2021)
Confidentialité des données
- Un arbitrage complexe à trouver
- Garantir le respect de la vie privée
- Conserver un maximum d’information statistique
- Les possibilités d’identification croissent avec les volumes de données
- Evolution des techniques de confidentialité
Techniques de confidentialité
- Anonymisation
- De plus en plus complexe à assurer
- Destruction
- Agrégation pour limiter la perte d’information
- Obfuscation
- Potentiel des données synthétiques
- Confidentialité différentielle
- Quantifier le risque d’une faille de confidentialité
Enjeux économiques
- Les big data sont souvent collectées par des acteurs privés
- Volonté d’accès à des fins de statistique publique
- Respect du secret des affaires
- Volonté des acteurs privés de valoriser ces données
- Exemple de FluxVision
- Stratégie : nouer des partenariats “au cas par cas”
- Difficultés à pérenniser l’approvisionnement de données
Limites des modes de collecte
Processus de génération des données non contrôlé
Représentativité généralement limitée
Formats complexes et souvent changeants
Difficultés d’acheminement entre infrastructures
- Coûts de transfert
Enjeux techniques
Infrastructures de stockage : les data lakes
Calcul distribué
- Ressources computationnelles
Services de data science
- Rendre accessibles les ressources
Importance d’une “sandbox”
Enjeux méthodologiques
- Traitement des données massives
- Algorithmes distribués
- Statistique en grande dimension
- Traitement de formats non-structurés
- Traitement du langage naturel
- Analyse d’images
- Méthodes de machine learning
L’importance de la formation
- De statisticien à data scientist
- Formalisation des besoins métiers
- Veille méthodologique
- Acculturation aux techniques informatiques
- De l’expérimentation à la mise en production
- Automatisation des traitements
- Bonnes pratiques de développement
Conclusion
Des innovations croisées
- Organisationnelles
- Structure en labs
- Investissement dans la formation
- Techniques
- Mettre à disposition une “sandbox”
- Méthodologiques
- Expérimentation : nouvelles sources, méthodes
Une construction collective
Des changements qui impliquent de nombreuses dimensions (juridique, technique, méthodologique, organisationnelle, …)
Le statisticien public ne peut incarner tous ces aspects
Développer des synergies entre toutes les parties prenantes (métiers, informatique, partenaires, …)
Plan de la formation
| Horaires | Activités |
|---|---|
| 8 h 30 - 9 h 00 | Accueil et installation |
| 9 h 00 - 9 h 15 | Cérémonie d’ouverture par le Directeur des Statistiques |
| 9 h 15 - 9 h 30 | Pause-café |
| 9 h 30 - 10 h 45 | Introduction sur la place et les enjeux liés au big data à l’Insee |
| 10 h 45 - 11 h 00 | Pause-café |
| 11 h 00 - 12 h 30 | Introduction sur la place et les enjeux liés au big data à l’Insee |
| 12 h 30 - 14 h 30 | Pause-déjeuner |
| 14 h 30 - 16 h 00 | Présentation Infra / Outils |
| 16 h 00 - 16 h 15 | Pause-café |
| 16 h 15 - 17 h 30 | Prise en main du SSP Cloud |
Plan de la formation
| Horaires | Activités |
|---|---|
| 8 h 30 - 10 h 30 | Sources big data à l’Insee |
| 10 h 30 - 10 h 45 | Pause-café |
| 10 h 45 - 12 h 30 | TP 1 : Manipulation des données volumineuses |
| 12 h 30 - 14 h 30 | Pause-déjeuner |
| 14 h 30 - 16 h 00 | TP 1 : Manipulation des données massives |
| 16 h 00 - 16 h 15 | Pause-café |
| 16 h 15 - 17 h 30 | Retour sur des projets de Machine Learning mis en production à l’Insee |
Plan de la formation
| Horaires | Activités |
|---|---|
| 8 h 30 - 10 h 30 | TP 2 : Introduction à la mise en production et au MLOps |
| 10 h 30 - 10 h 45 | Pause-café |
| 10 h 45 - 12 h 45 | TP 2 : Déployer un modèle de machine learning |
Plan de la formation
| Horaires | Activités |
|---|---|
| 8 h 30 - 10 h 00 | Aspects juridiques et réglementaires du big data : un retour d’expérience |
| 10 h 00 - 10 h 15 | Pause-café |
| 10 h 15 - 12 h 00 | Retour sur la formation et échange sur la stratégie big data de la BCEAO |
| 12 h 00 - 13 h 00 | Cérémonie de clôture de l’atelier par le Directeur des Statistiques |