Codification automatique de l’APE avec de l’apprentissage statistique
BCEAO - Jour 3
27 septembre 2023
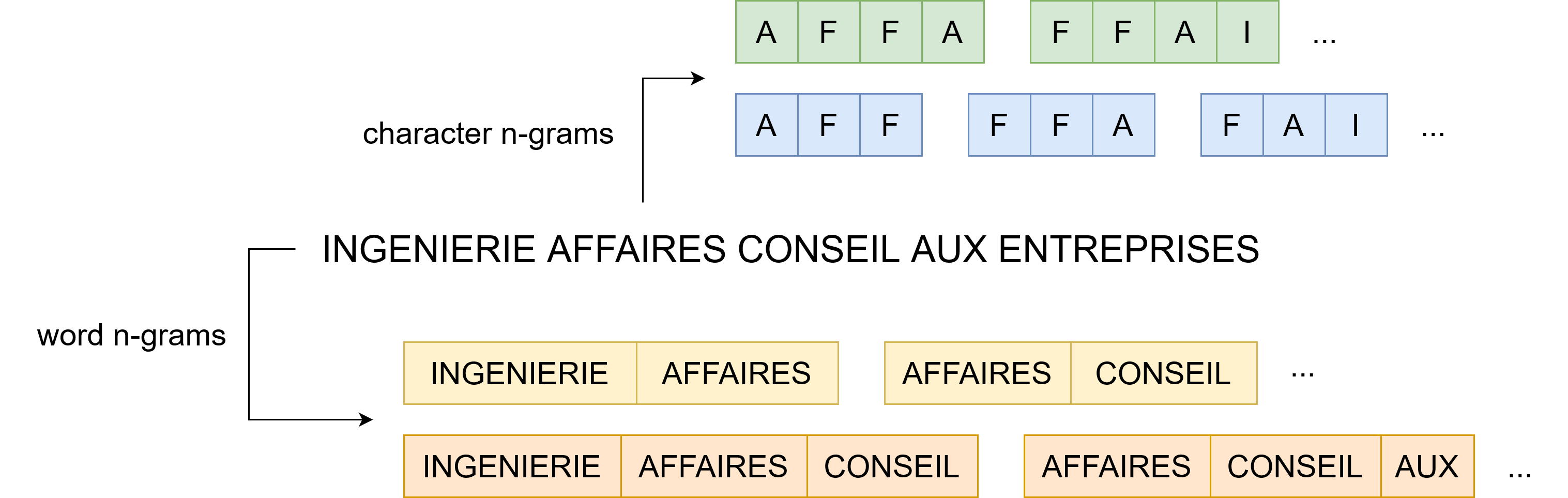
Feature extraction
- Plongements lexicaux: méthode de vectorisation.
- Plongements pré-entrainé disponibles en open-source.
- Nous apprenons nos propres plongements de mots.
- Mais aussi des plogements de :
- n-grams de mots et de n-grams de caractères.
Une bonne performance globale
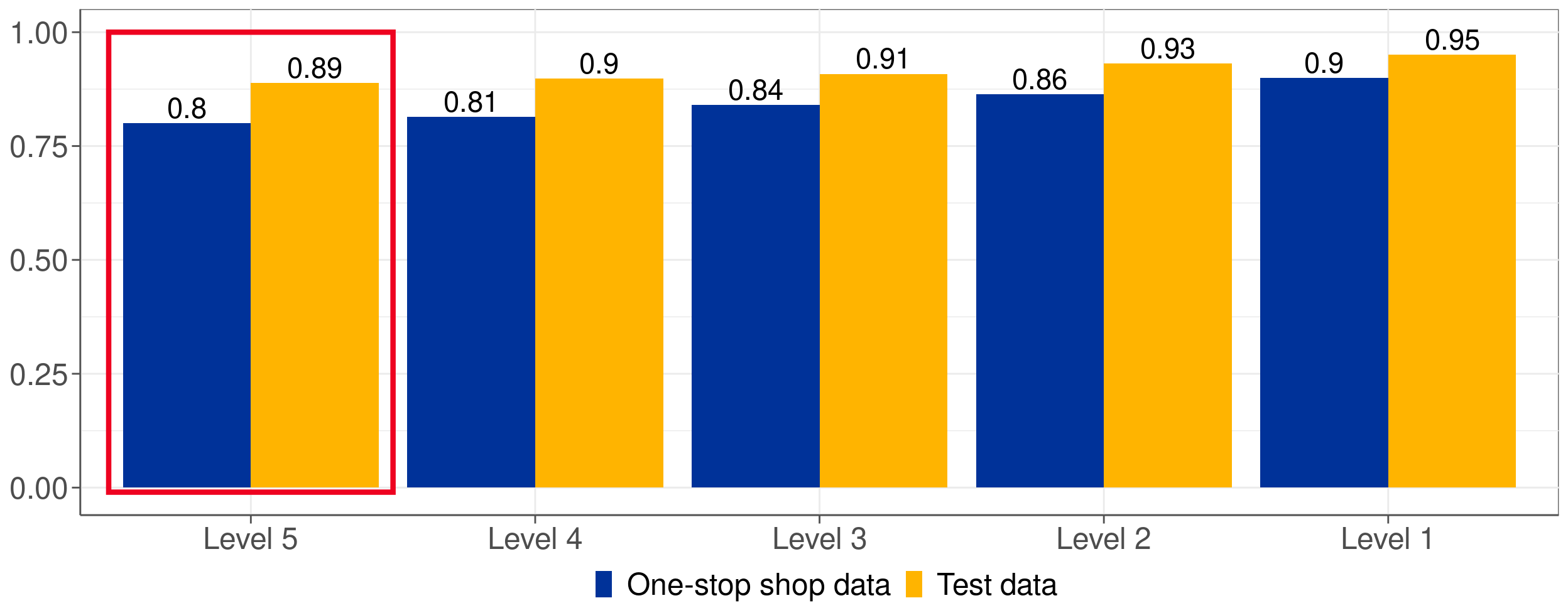
Figure 1: Taux de précision pour chaque niveau de la nomenclature du code APE
- Près de 80% des libellés issus du guichet unique sont correctement codifiés.
- Erreurs de prédiction proches dans la nomenclature.
Fludifier le processus de codification manuel
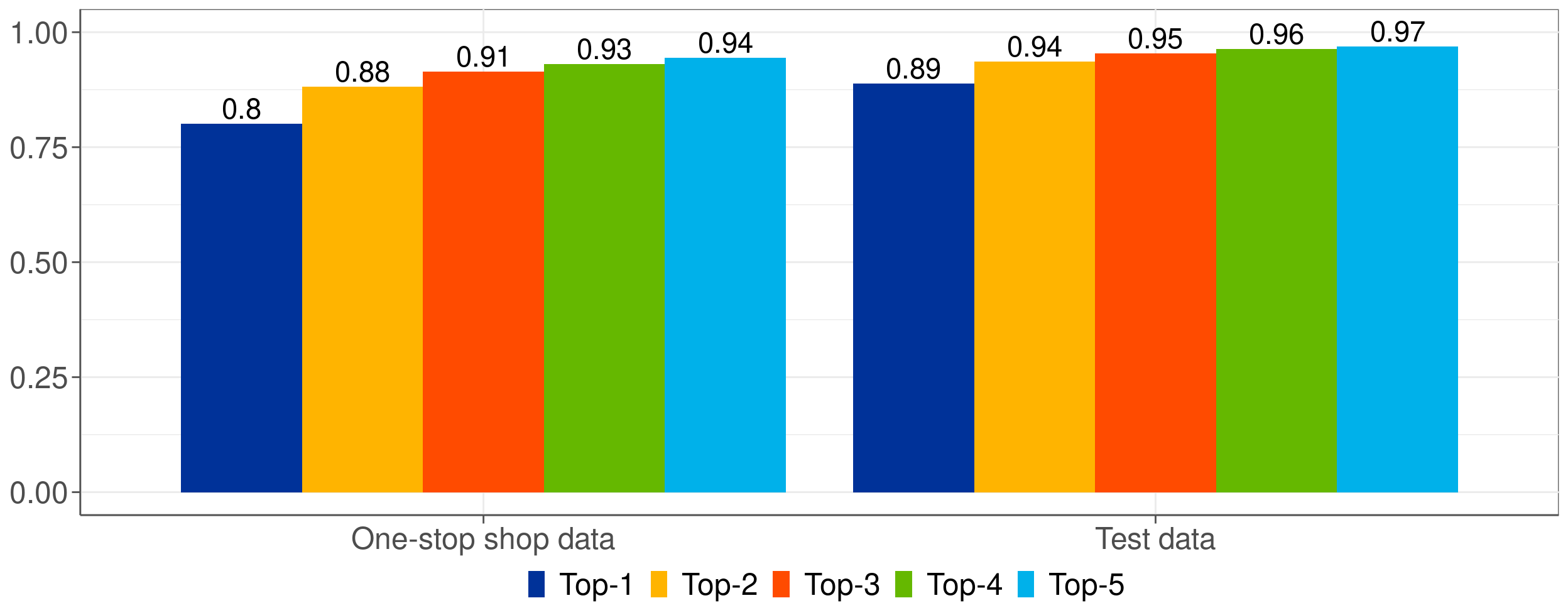
Figure 2: Top-\(k\) accuracy pour chaque jeu de données.
- Connaissance des probabilités pour chaque classe.
- Dans 94% des cas, la bonne classification se trouve dans les 5 prédictions les plus probables.
Construction d’un indice de confiance
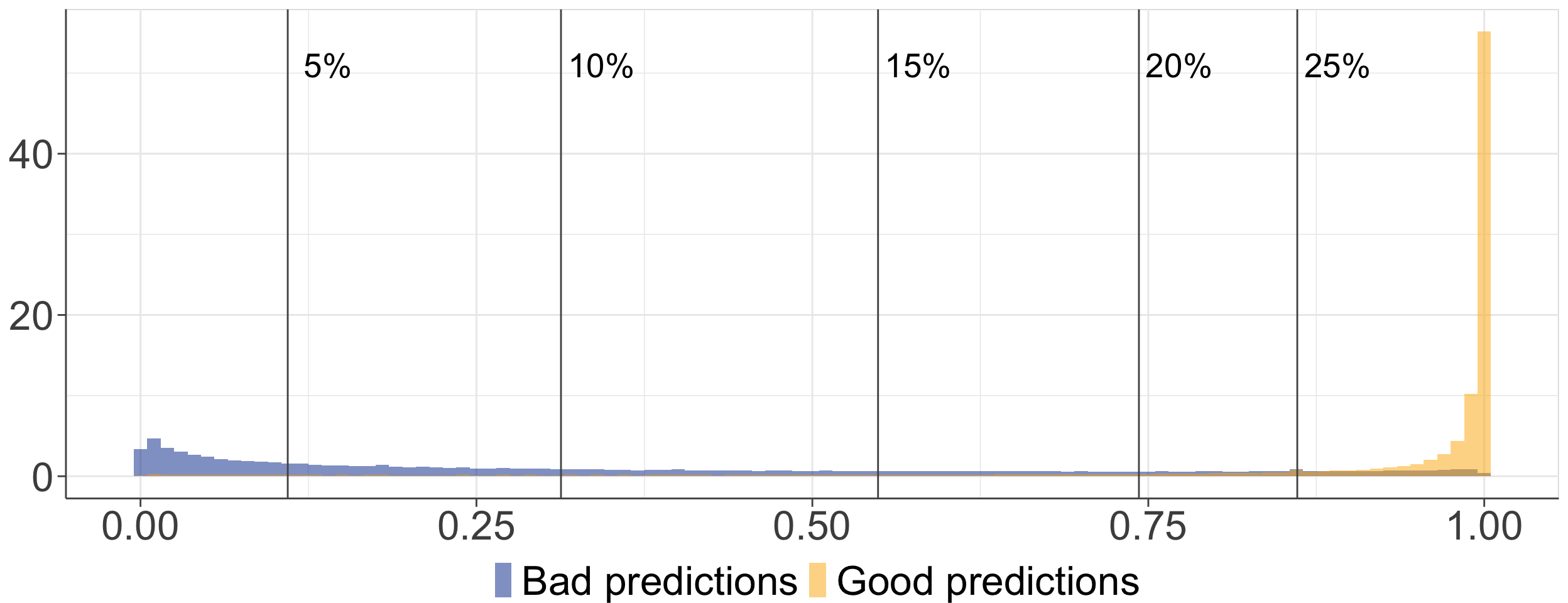
- Objectif : discriminer les mauvaises des bonnes prédictions.
- Indice de confiance retenu : différence entre les deux probabilités les plus élevées.
Améliorer l’efficacité de la reprise manuelle
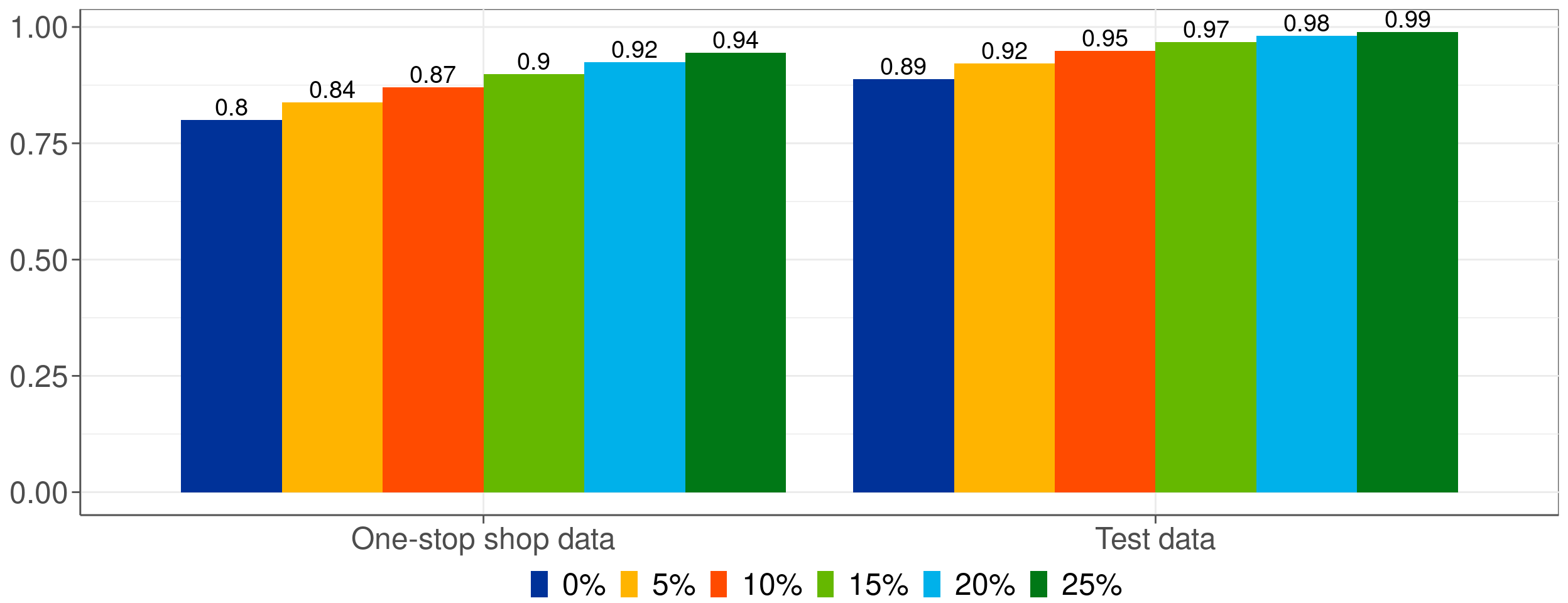
Figure 3: Précision en fonction du taux de reprise manuelle effectuée.
- Optimisation de la reprise manuelle ➨ gain de performance.
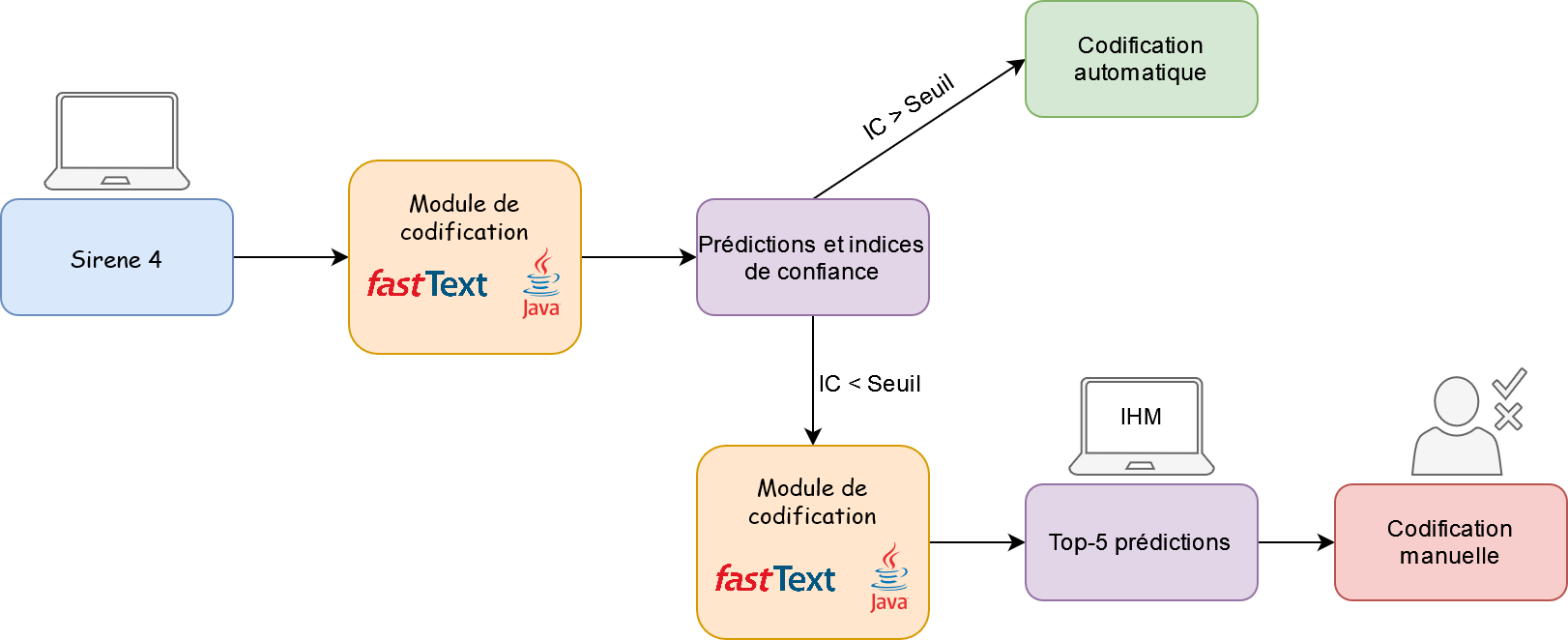
Organisation actuelle avant la mise en production
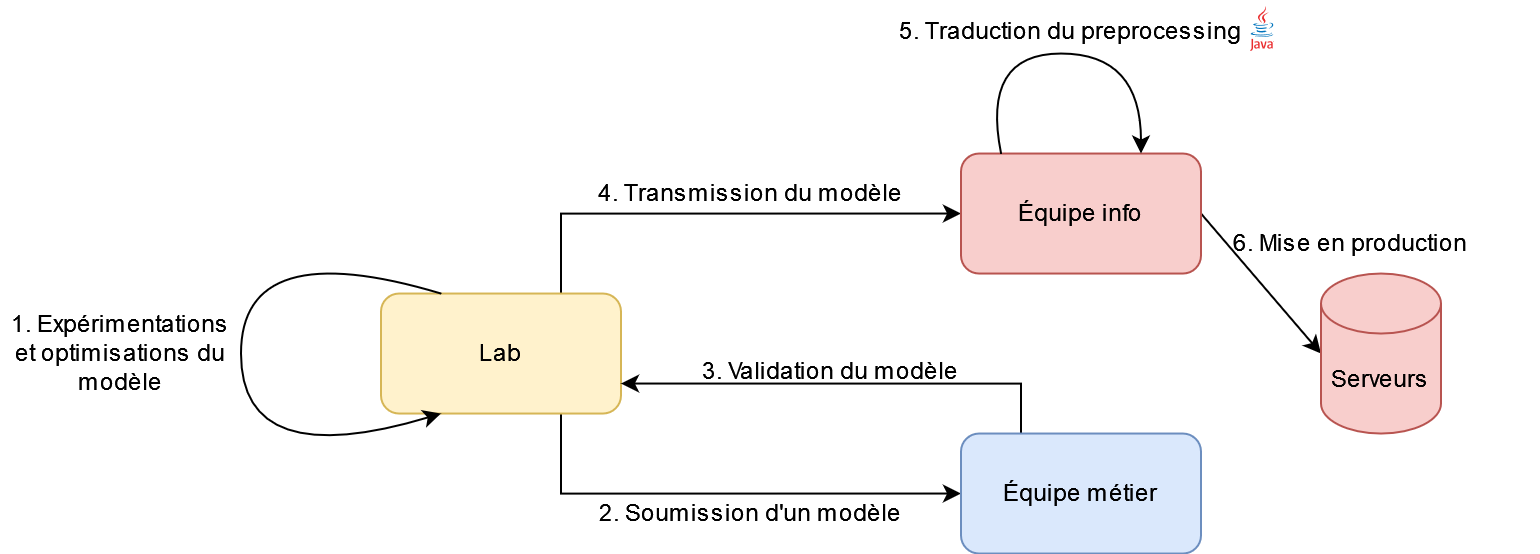
- 3 parties prenantes
Organisation actuelle une fois le modèle déployé en production