MLOps at Insee: a use case for text classification
19 March 2024
Context
- Sirene is the French national company registry
- When a company registers, an activity code is attributed
- Early 2023:
- Refactoring of the Sirene information system
- Companies register through a new channel
- Performance drop of the legacy coding engine
- Teams already overwhelmed
- Consequence: Ideal moment to innovate (but under the constraint!)
Model
- Text classification model which uses additional categorical variables
- For now we use the fastText library
- Originally trained on legacy data annotated partly by the coding engine and partly manually
Current state of affairs
- Model trained on Insee’s cloud data science platform 😍
- Coding engine developed in Java inside of a monolithic architecture 😫
- Code duplication
- Reproductibility issues
- Increased risk of error
- Maintenance problems
- No monitoring
- No test data
Current state of affairs

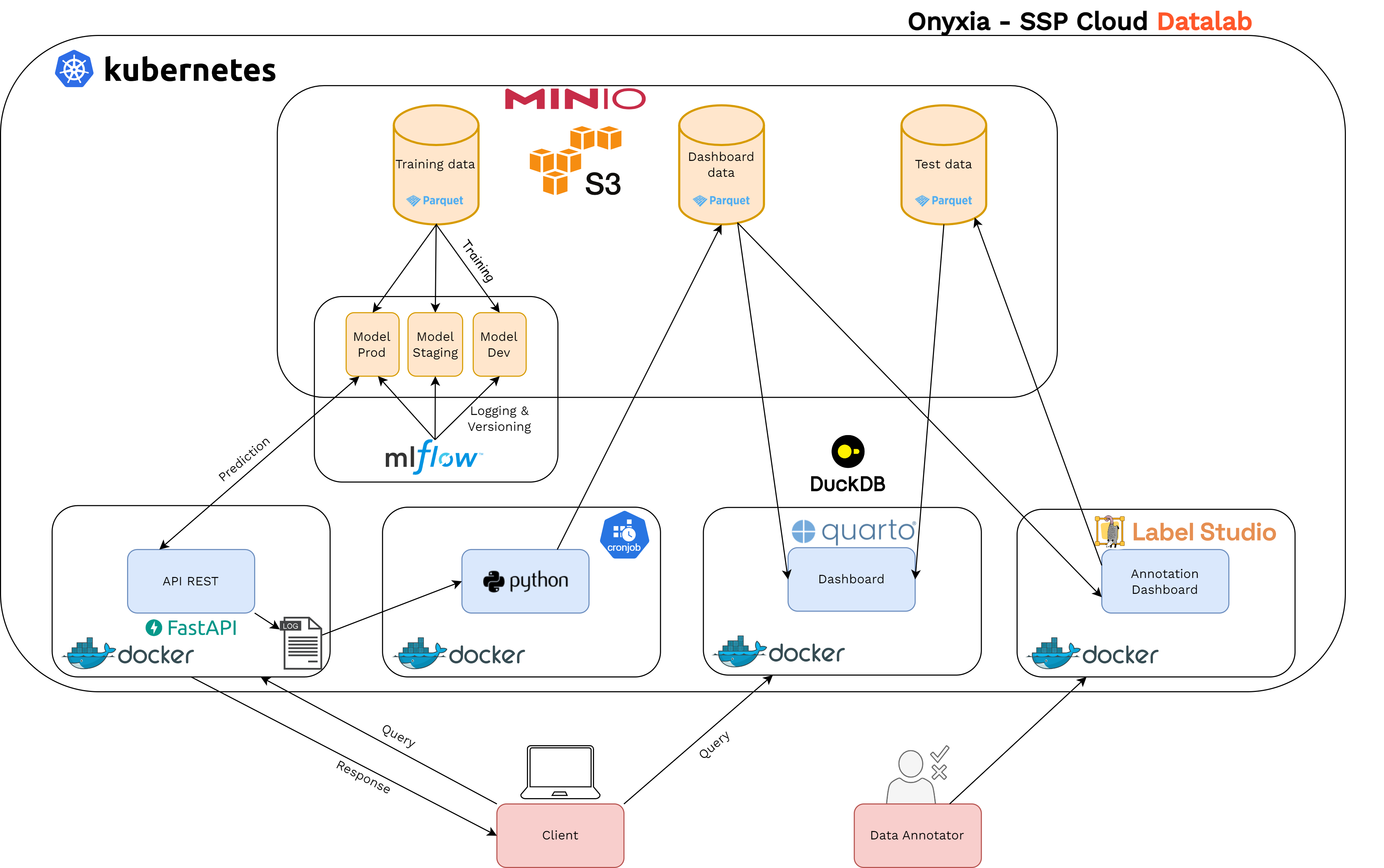
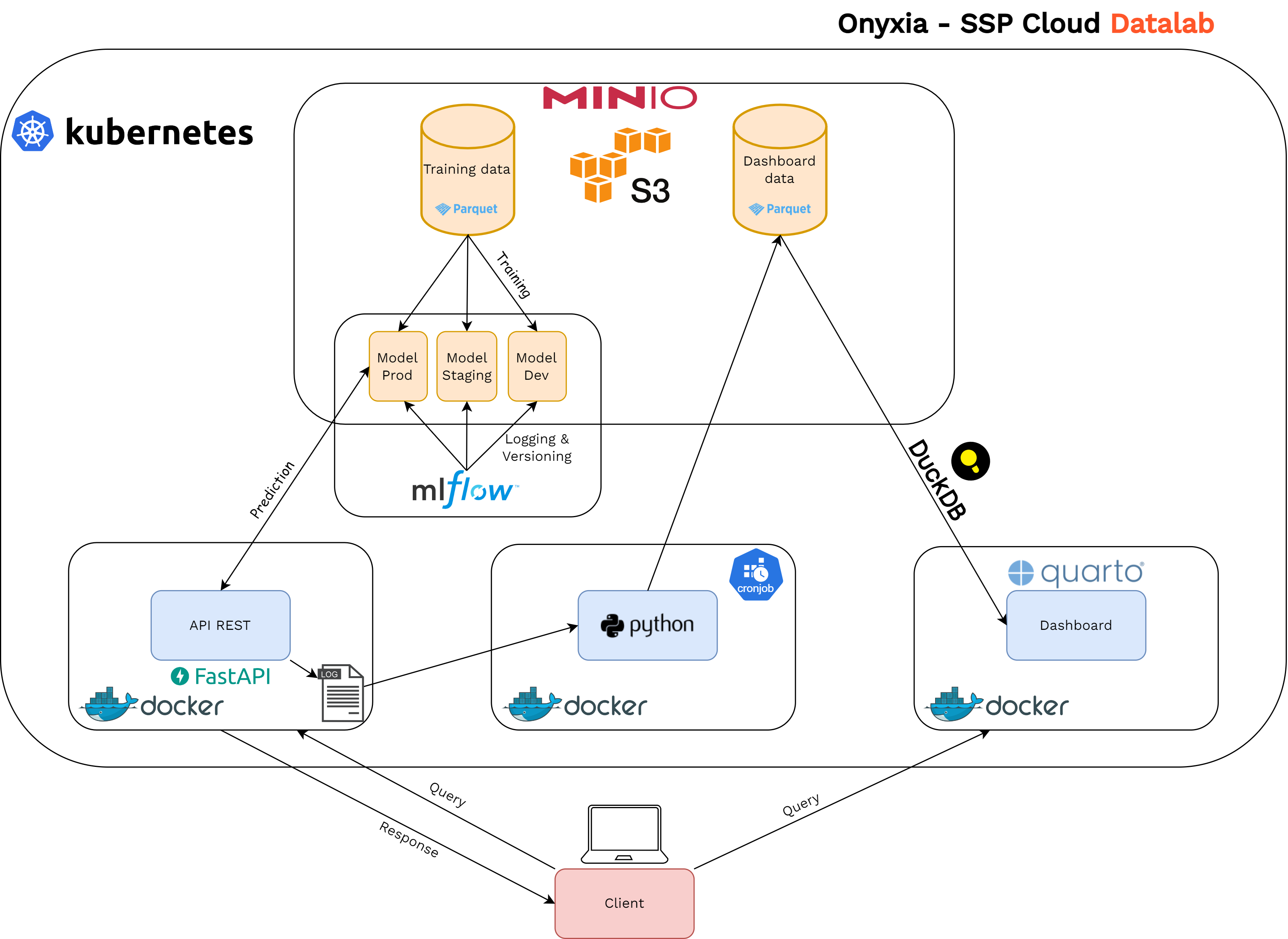
MLOps target
- Microservice architecture running on a Kubernetes cluster
- Experiment tracking and model store: MLflow
- Model served via an API: FastAPI
- Automation with ArgoCD
- Monitoring dashboard: Quarto and DuckDB
- Quality control: annotations with Label Studio
Experiment tracking
- Argo Workflows used for distributed training
- MLflow used to track/log experiments and compare runs
- Custom model class allows to package pre-processing steps in the
predictmethod:
Model store
- MLflow also used as a model store
- Models are packaged with all the metadata necessary to run inference
- Registered models are simply loaded with this command where
versionis a number or a"Production"tag for example
API serving
- Text classification model served through a containerized REST API:
- Simplicity for end users
- Standard query format
- Scalable
- Modular and portable
- Multiple endpoints: batch, online
- Continuous deployment with Argo CD
API serving

Monitoring
- Monitoring the model in a production environment is necessary:
- To detect distribution drifts in input data
- To check that the model has a stable behavior
- To decide when to retrain a model
- Ideally, we would like to track model accuracy in real-time but expensive
- In addition, monitoring of the API: latency, memory managment, disk usage, etc.
Monitoring
- How we do it:
- API logs its activity
- Logs are fetched and formatted periodically
- Metrics are computed from the formatted logs
- Display on a dashboard
Monitoring
Quality control
- Test data is gathered and annotated periodically
- Annotation is done with Label Studio
- Performance metrics are computed on the test data
- Performance is diplayed on the monitoring dashboard
- Specific retraining is necessary when specific metrics decrease under a certain threshold (not done yet)
Quality control