Codification automatique de l’APE dans le cadre du projet Sirene 4
Séminaire DMS
7 octobre 2022
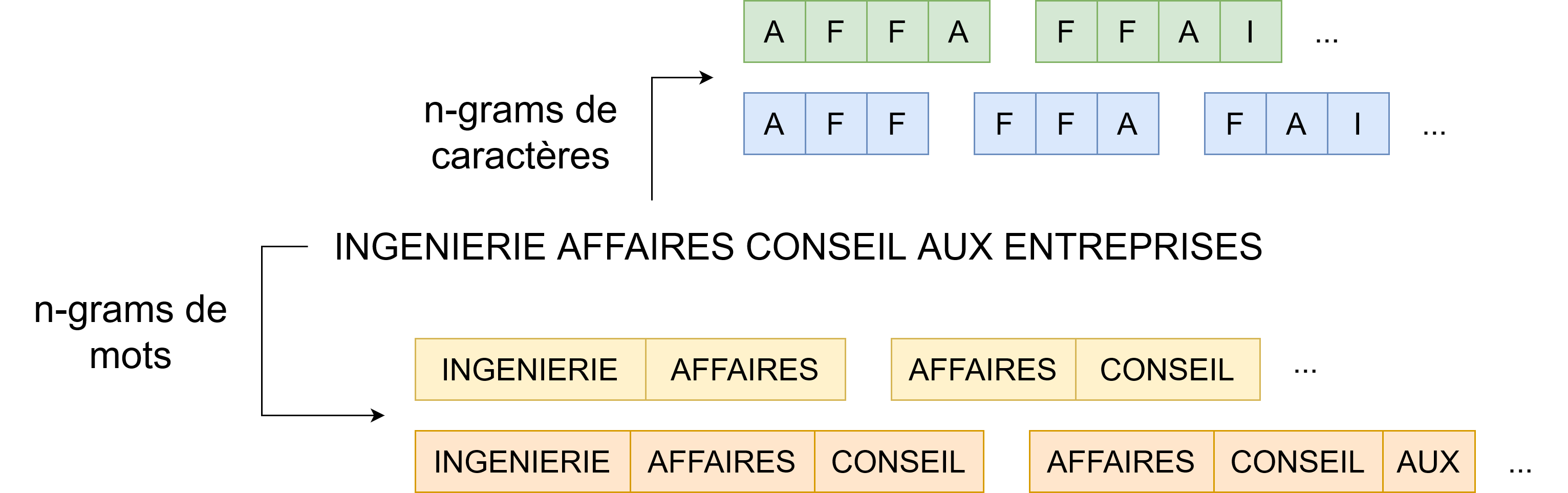
Vectorisation des libellés
- Plongements lexicaux : méthode de vectorisation.
- Plongements pré-entraînés disponibles en open-source.
- On apprend nos propres plongements de mots.
- Mais aussi des plongements pour :
- Les n-grams de mots et n-grams de caractères.
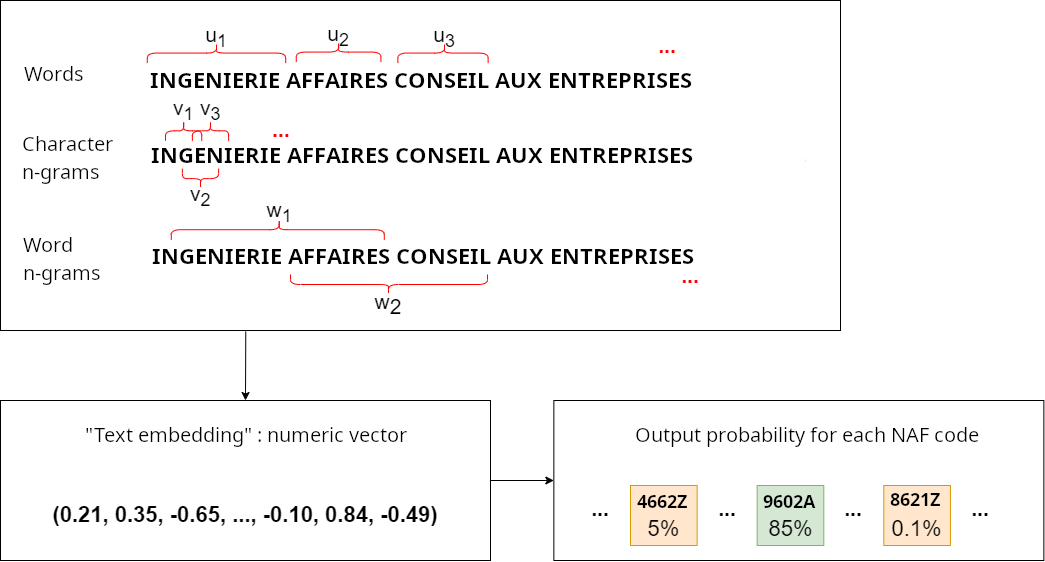
Classification à partir de plongements lexicaux
Implémentation, entraînement


- fastText : librairie rapide (
C++) et facilement utilisable. - Optimisation des paramètres d’entraînement et hyperparamètres avec mlflow.
Évaluation de la performance
- Évaluation sur 2 jeux de données :
- un jeu de test, 20% des données soit \(\approx\) 2.5 millions observations
- un jeu issue du guichet unique \(\approx\) 15 000 observations
Figure 1: Précision en fonction du taux de reprise manuelle effectuée.
Une bonne performance globale
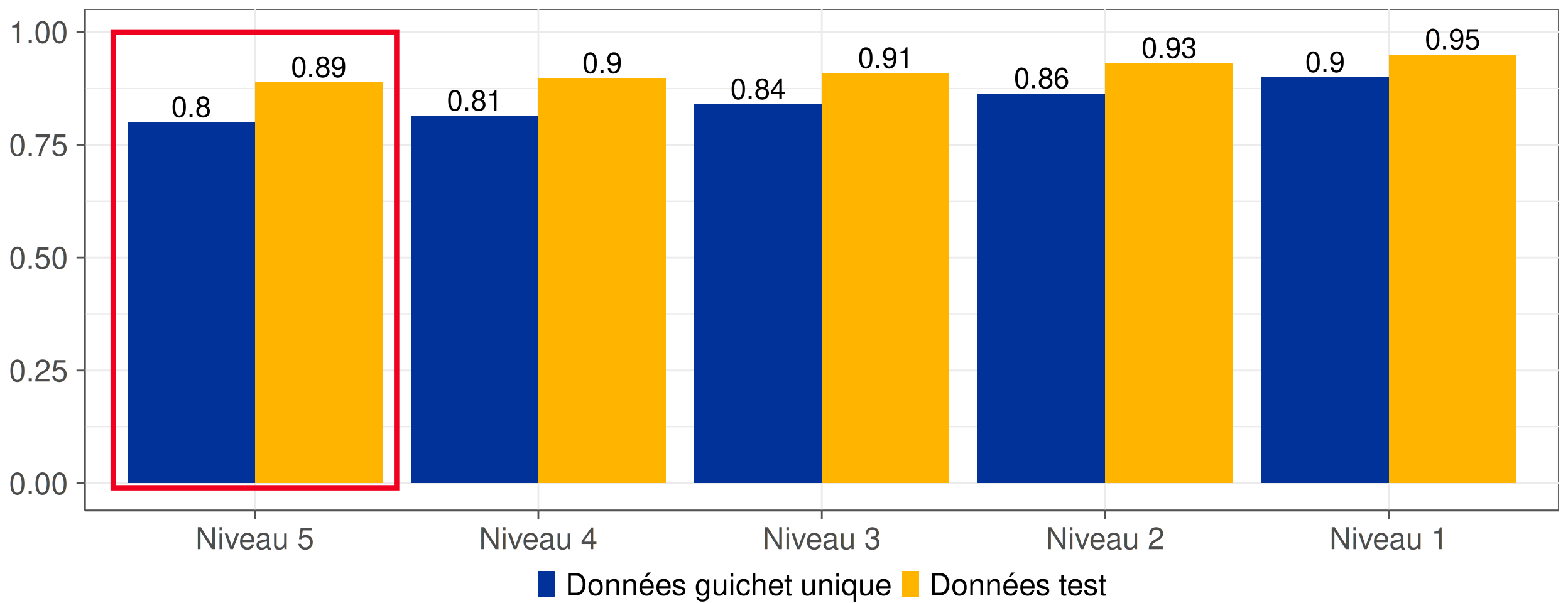
Figure 2: Taux de précision pour chaque niveau de la nomenclature du code APE.
- Près de 80% des libellés issus du guichet unique sont correctement codifiés.
- Erreurs de prédiction proches dans la nomenclature.
Une aide à la reprise manuelle
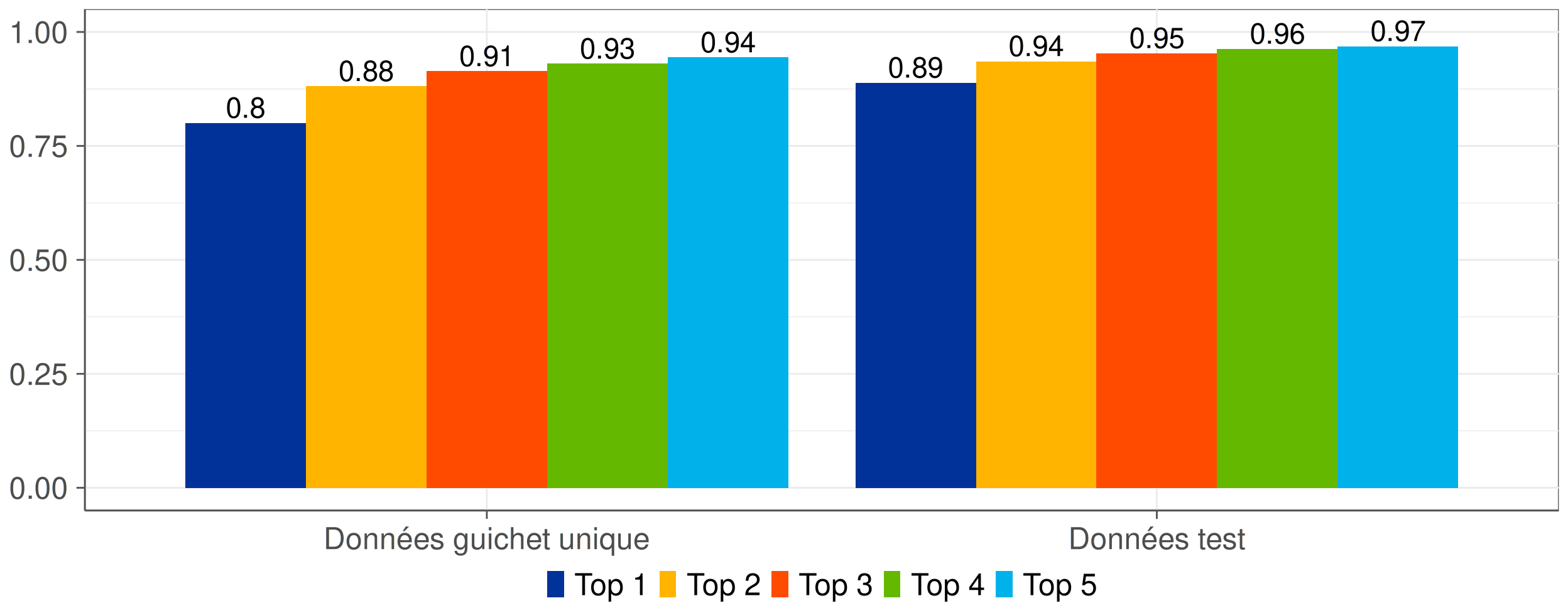
Figure 3: Top-K Accuracy pour chaque jeu de données.
- Connaissance des probabilités pour chaque classe.
- Dans 94% des cas, la bonne classification se trouve dans les 5 prédictions les plus probables.
Une performance hétérogène en fonction des classes
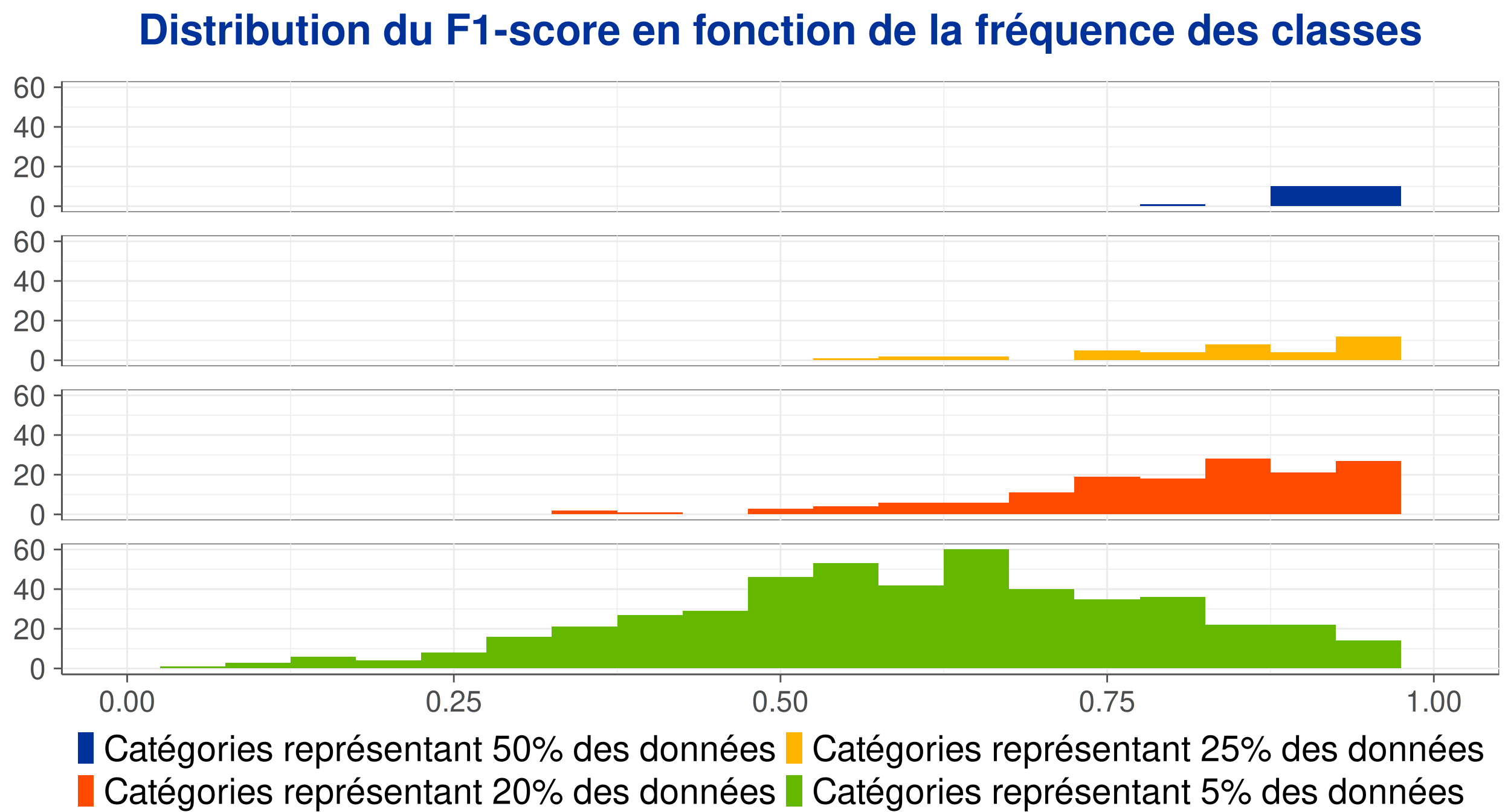
Figure 4: Distribution du F1-score en fonction de la fréquence des classes.
- Performance mitigée sur plusieurs classes peu fréquentes.
Construction d’un indice de confiance
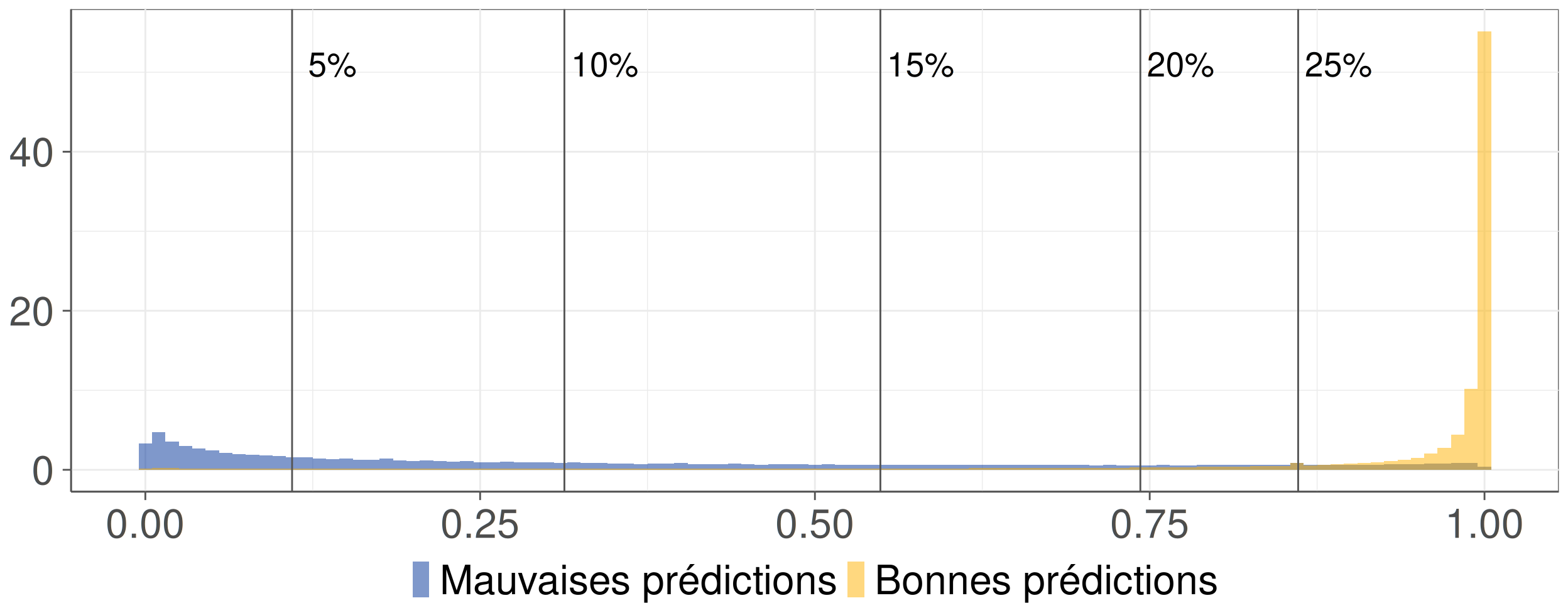
Figure 5: Distribution de l’indice de confiance en fonction du résultat de la prédiction.
- Objectif : discriminer les mauvaises des bonnes prédictions.
- Indice de confiance retenu : différence entre les deux probabilités les plus élevées.
Efficacité de la reprise manuelle
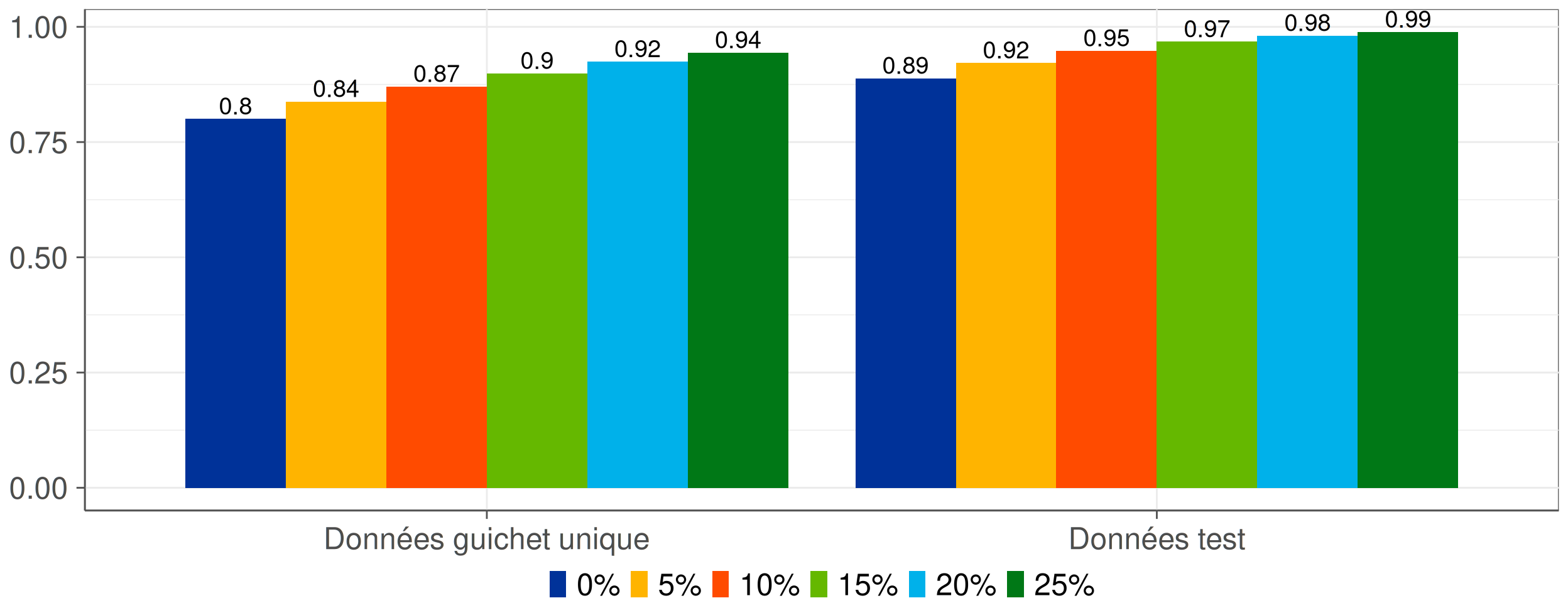
Figure 6: Précision en fonction du taux de reprise manuelle effectuée.
- Optimisation de la reprise manuelle ➨ gain de performance.
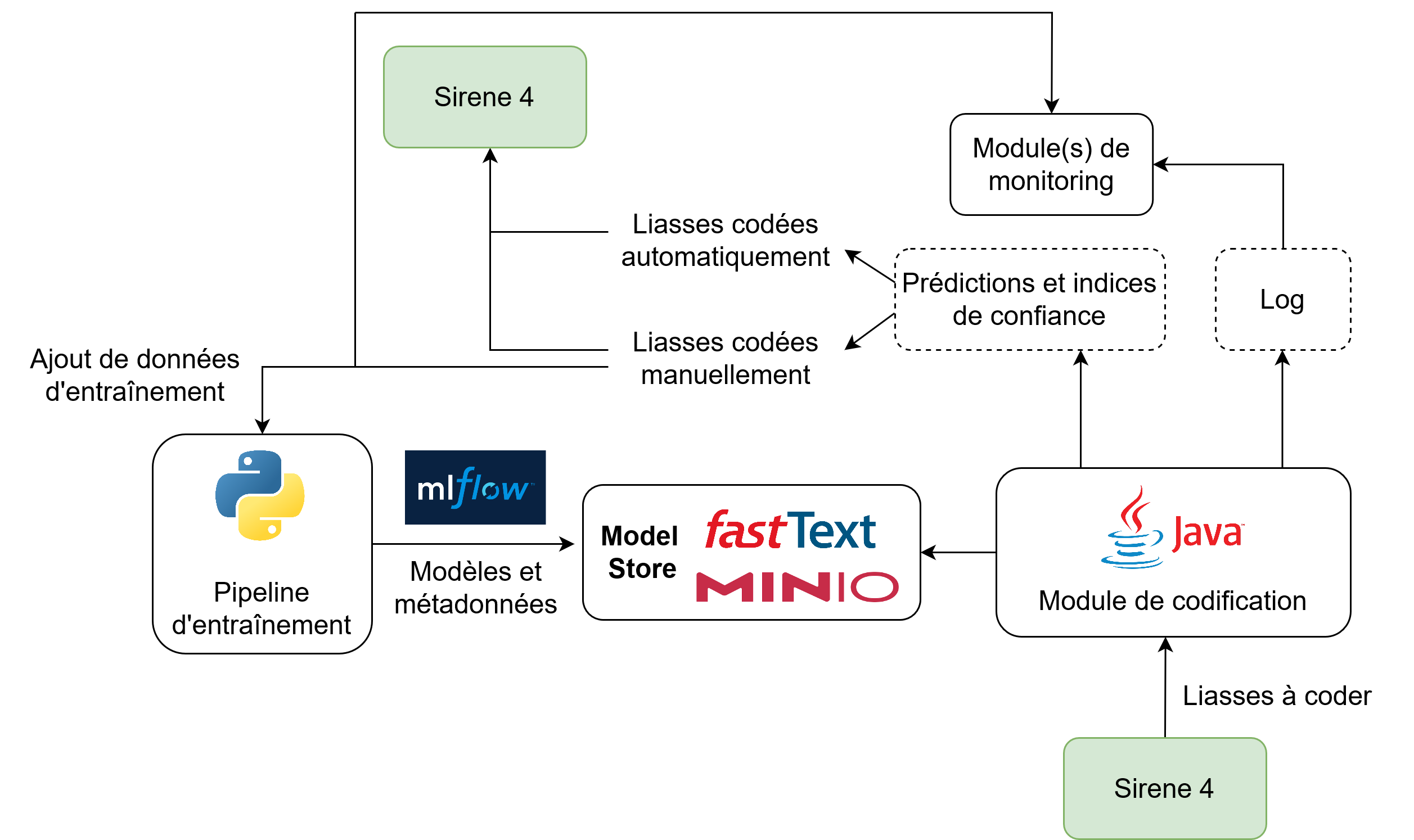
Organisation à terme ?