Codification automatique de l’APE dans le cadre du projet Sirene 4
Journée SSP Hub
17 avril 2023
Contexte
Contexte
Plusieurs changements majeurs :
- Interne : Refonte du répertoire Sirene 4.
- Externe : Mise en place d’un guichet unique.
Constat : Sicore n’est plus l’outil adapté ➨ 30% de codification automatique.
Conséquence : moment idéal pour proposer une nouvelle méthodologie de codification automatique de l’APE.
Données
- \(\approx\) 10 millions de liasses d’entreprises issues de Sirene 3 couvrant la période 2014-2022.
- Données labellisées par Sicore ou par un gestionnaire.
- Une observation consiste en :
- un descriptif textuel de l’activité
- la nature de l’activité – NAT (23 modalités)
- le type de la liasse – TYP (15 modalités)
- le type d’évènement – EVT (24 modalités)
- la surface (\(m^2\))– SUR (4 modalités)
La nomenclature hiérarchique de l’APE
| Niveau | Code | Libellé | Taille |
|---|---|---|---|
| Section | H | Transports et entreposage | 21 |
| Division | 52 | Entreposage et services auxiliaires des transports | 88 |
| Groupe | 522 | Services auxiliaires des transports | 272 |
| Classe | 5224 | Manutention | 615 |
| Sous-classe | 5224A | Manutention portuaire | 732 |
Méthodologie
Vectorisation des libellés
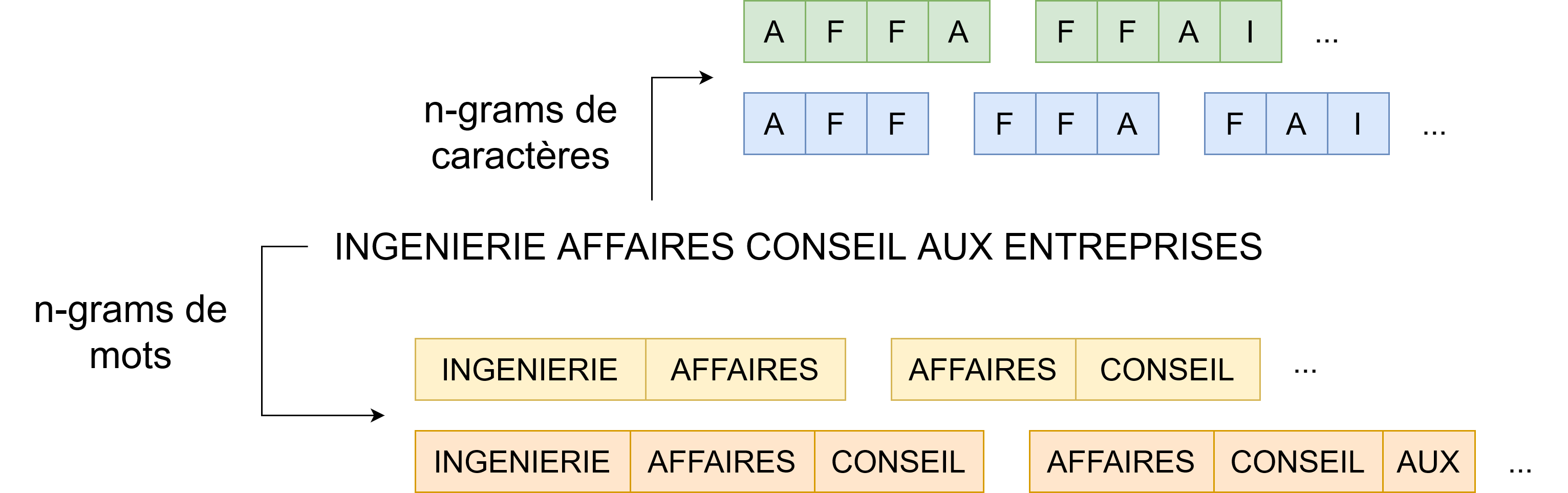
- Plongements lexicaux : méthode de vectorisation.
- Modèle “Bag of n-grams”. On apprend des plongements pour les mots, les n-grams de mots et n-grams de caractères.
Classification
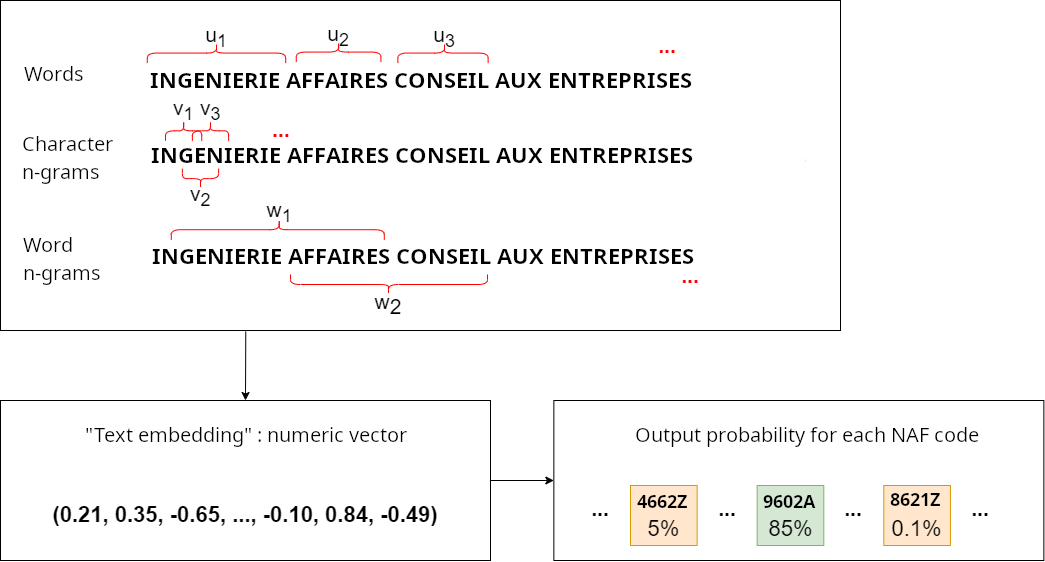
- Modèle simple qui fonctionne bien dans notre contexte.
- Indice de confiance calculé pour chaque prédiction.
Mise en production
Organisation actuelle
- 3 parties prenantes autour du projet :
- Équipe métier
- Développeur Sirene 4
- SSP Lab
- Mise en production (trop?) rapide :
- Problèmatique : équipes Sirene surchargées
- T1 2022 : lancement des expérimentations
- Novembre 2022 : 1ère mise en production de manière progressive et restrictive
Chronologie avant la mise en production d’un modèle
- Expérimentations par le SSP Lab et optimisation d’un modèle avec MLflow Tracking
- Validation du modèle par l’équipe métier
- Le SSP Lab transmet le binaire aux développeurs Sirene 4
- Les développeurs traduisent de Python à Java le preprocessing à effectuer en amont et intègre le modèle dans le module de codification
Une fois le modèle en production
- 2 appels au module de classification :
- Classification automatique du code APE
- Aide à la reprise manuelle via une IHM
- Observabilité du modèle :
- Logs accessibles seulement sur les machines de production ➨ demande nécessaire
- Pas de constitution de jeu d’évaluation en continu
Retour d’expérience
- API Java vs. expérimentation Python :
- Duplication de code
- Risque d’erreurs accru
- Problèmes liés à l’utilisation de FastText :
- maintenance
- reproductibilité
- sécurité
- Infrastructure de production rigide.
Retour d’expérience
- Méconnaissance des problèmes métier côté SSP Lab pour la maintenance.
- Contrôle de version et transmission des modèles.
- Confiance et compréhension du classifieur nécessaires côté métier/gestionnaires Sirene.
- Logs difficilement accessibles et au format variable.
- Pas d’accès aux bases Sirene (réentraînement).
Organisation visée
- Observabilité, maintenance du modèle côté Sirene (appui technique du SSP Lab)
- Cluster Kubernetes de production
- S’affranchir de FastText
- Utilisation du plein potentiel de MLflow pour la gestion des modèles en production
- Développement d’une API Python