Codification automatique de l’APE à l’Insee
Présentation à l’INSERM
7 mai 2024
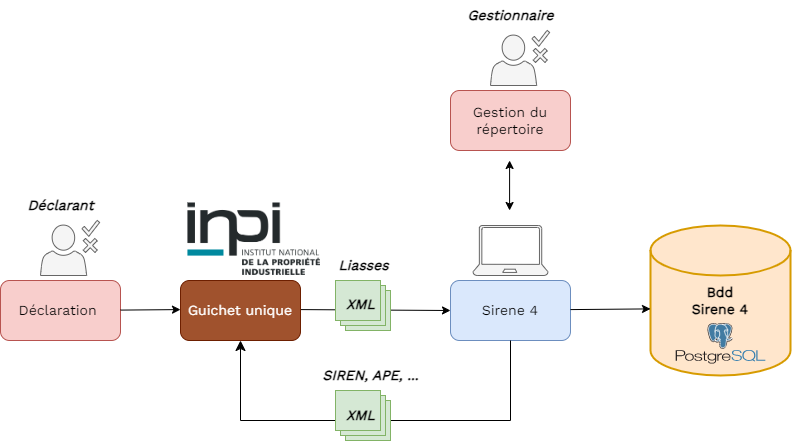
Le paysage administratif
Construction d’un indice de confiance
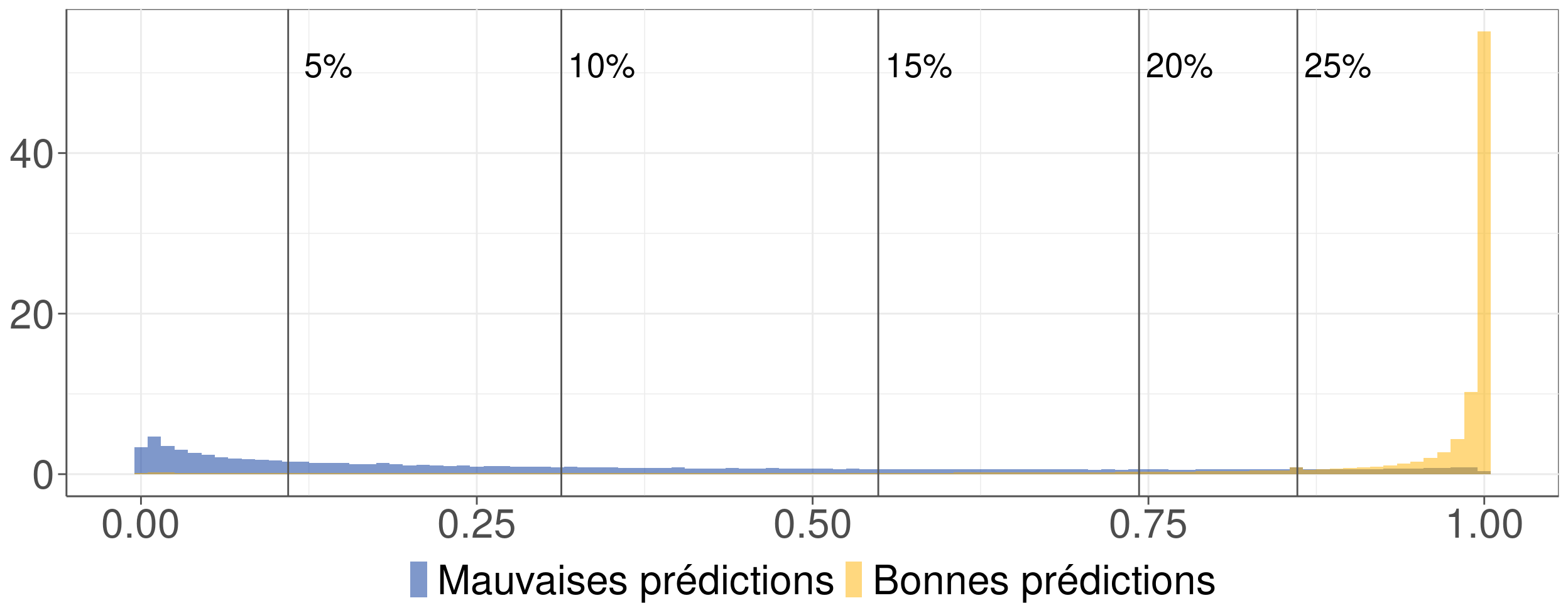
- Objectif : discriminer les mauvaises des bonnes prédictions.
- Indice de confiance retenu : différence entre les deux probabilités les plus élevées.
Mise en production actuelle
- 2 issues possibles :
- codification automatique 🚀
- reprise gestionnaire 🔍

Codification du flux de liasses
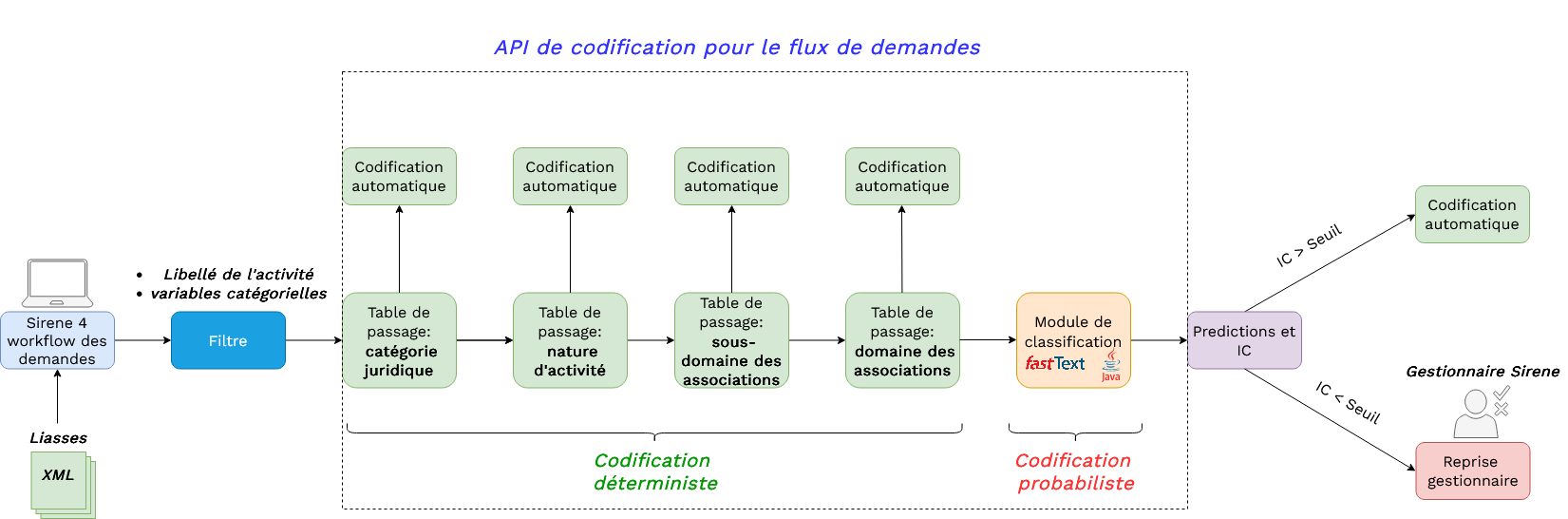
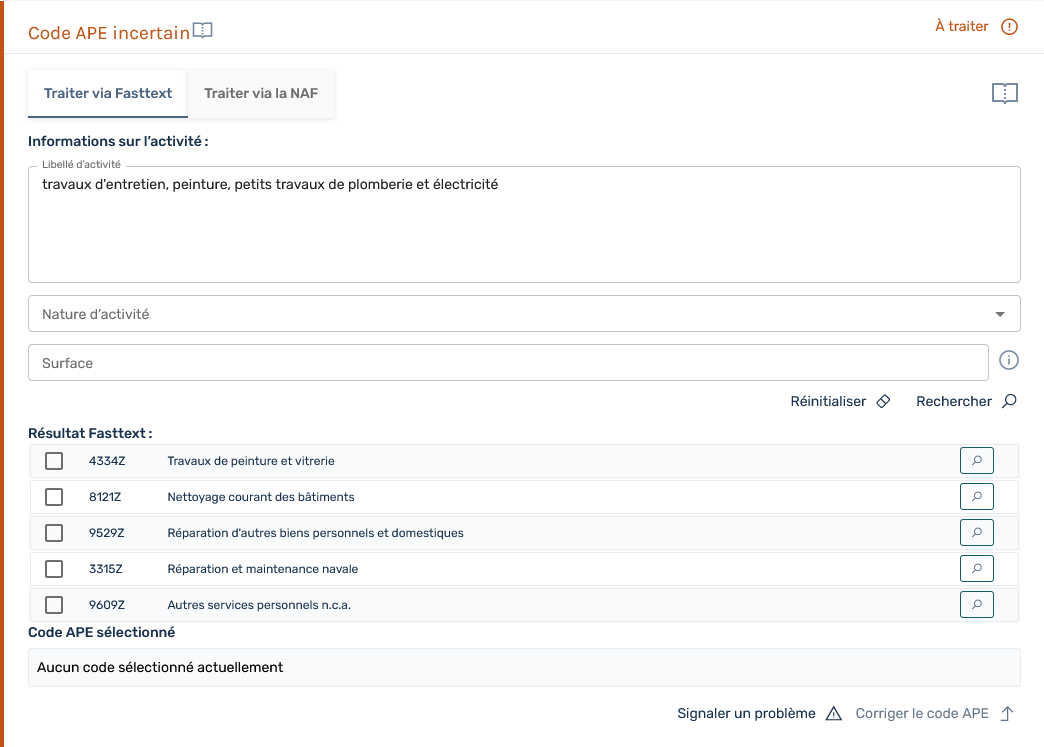
Reprise gestionnaire

Codification automatique sur l’IHM
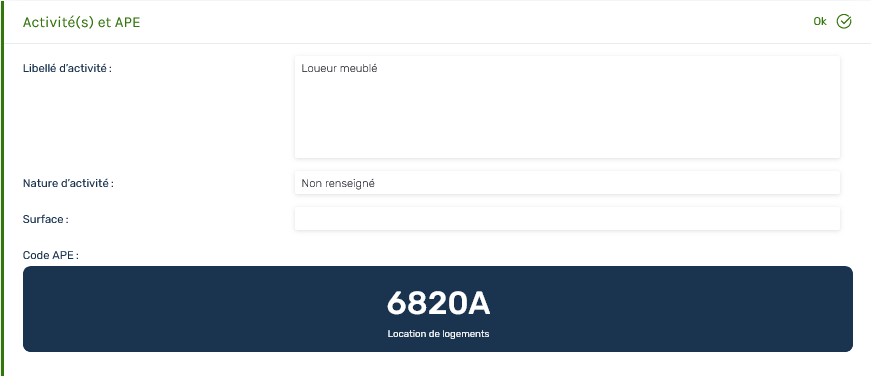
Reprise gestionnaire sur l’IHM
Situation actuelle inefficace
- Spécificités du ML non prises en compte :
- Pas de surveillance du modèle en temps réel
- Pas de données golden standard
- Pas de ré-entrainement régulier
- Conséquence : Besoin d’adopter les bonnes pratiques d’un point de vue technique (MLOps) et organisationel
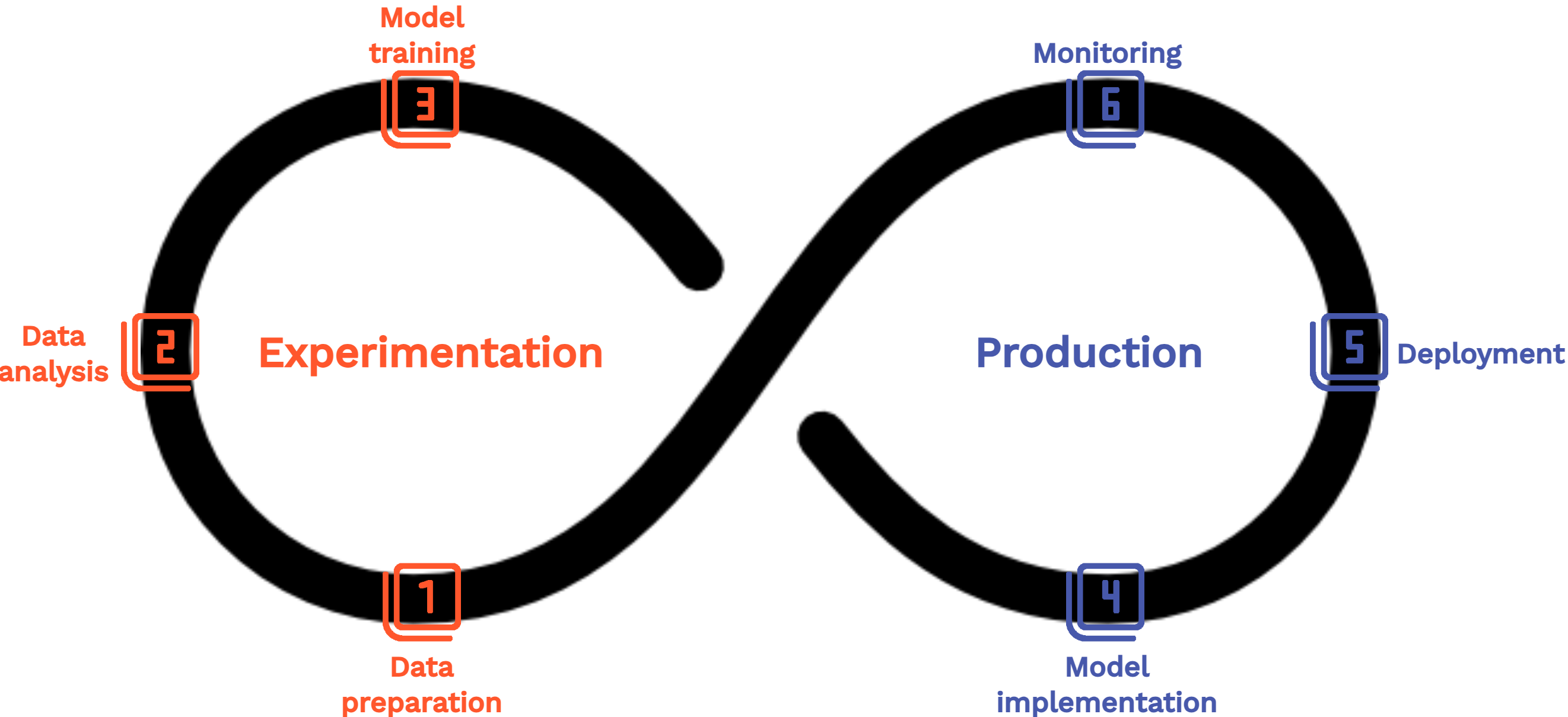
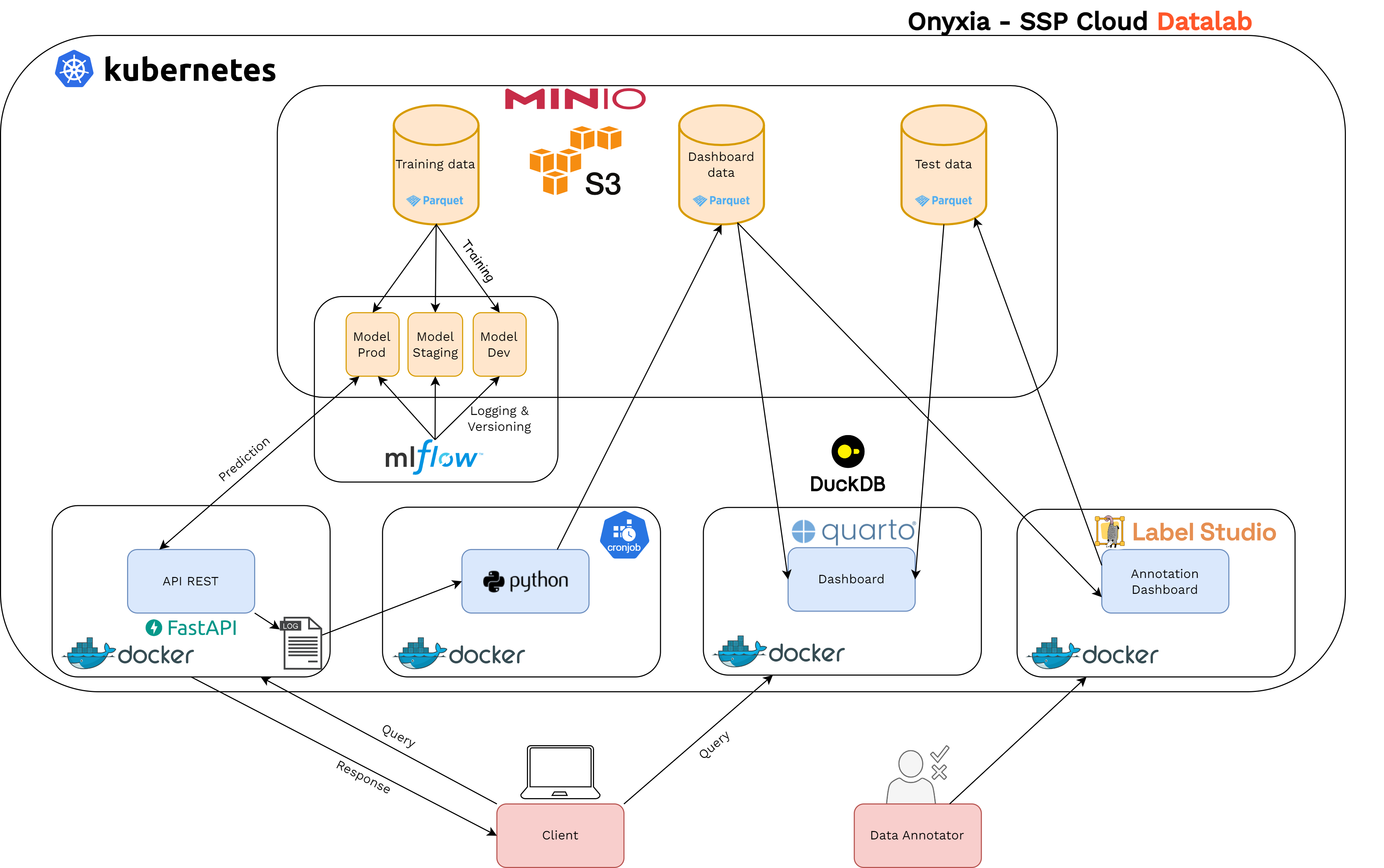
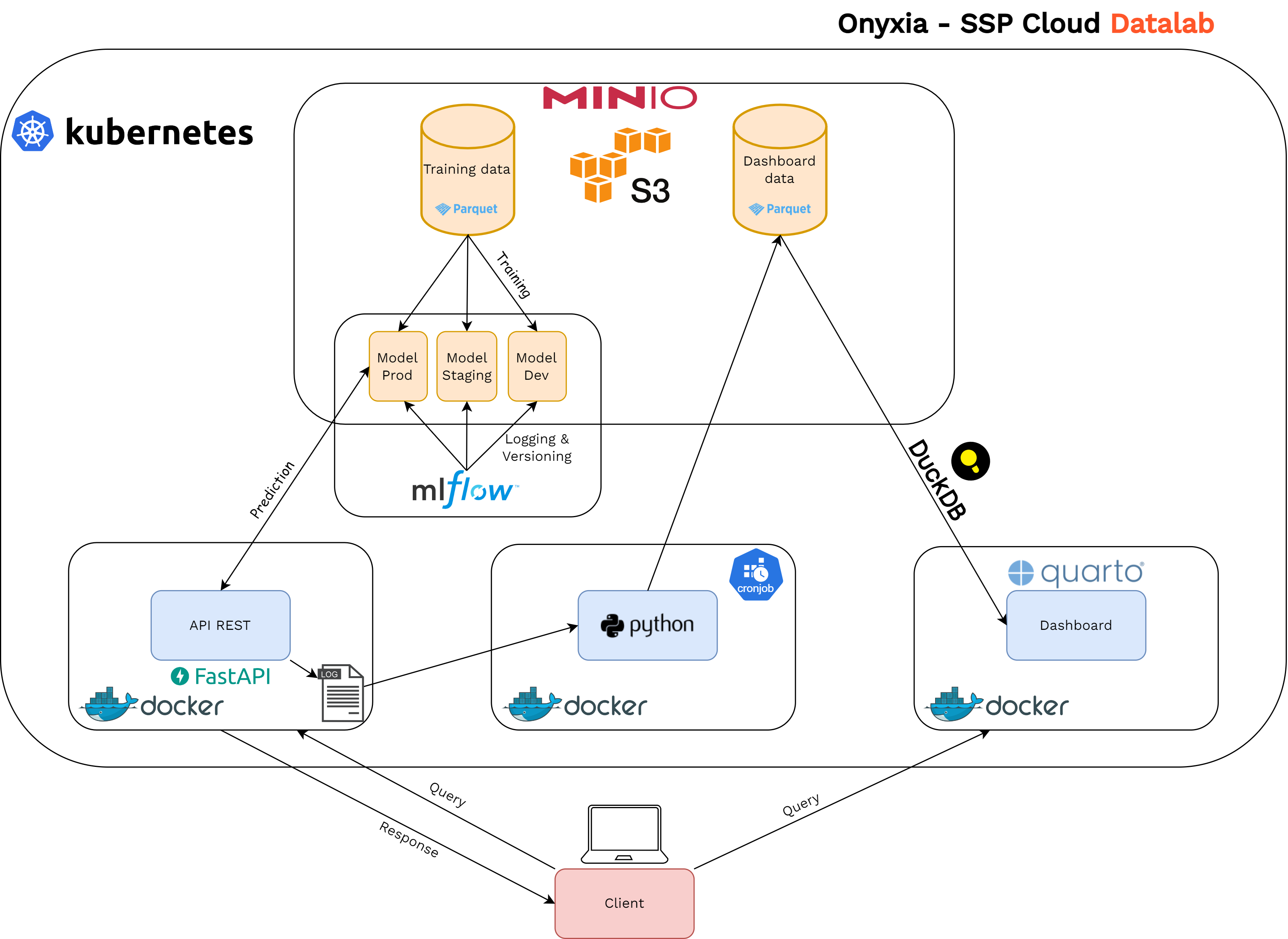
MLflow au coeur de notre projet
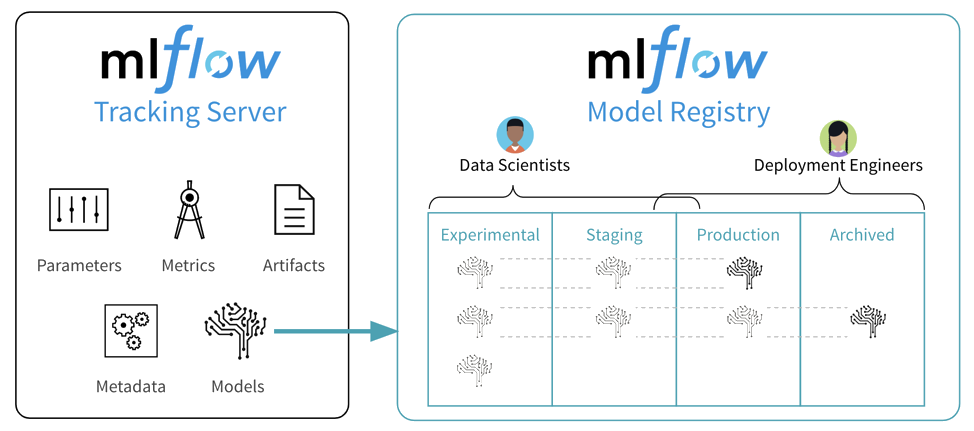
Exposer un modèle via une API

Monitoring
Contrôle qualité