Travaux sur le passage de la nomenclature NAF2008 Rev2.1 à la NAF2025
Groupe de veille Codification Automatique n°9
6 novembre 2024
1️⃣ Introduction
Les modèles de ML en production
- De plus en plus de modèle ML sont voués à être mis en production à l’Insee
- Multiples cas d’usages : codification automatique, imputation, détection de valeurs extrêmes
Quality Assurance Framework of the European Statistical System
Source data, integrated data, intermediate results and statistical outputs must be regularly assessed and validated.
- Cela s’applique évidemment aux modèles de ML dans le processus de production statistique ➡️ besoin de maintenance dans le temps
Qualité des modèles ML
- Un modèle ML est entrainé pour résoudre un tâche à partir de données de référence
- Données réelles peuvent dévier de ces données de références dans le temps ➡️ perte de performance ?
- Ré-entrainement du modèle devient nécessaire
- Cas extrême courant dans le cas de la statistique publique ➡️ changement de nomenclature
Historique du projet APE
- Eté 2022 : entraînement d’un modèle fasttext sur les données Sirene 3
- Novembre 2022 : 1ère mise en production (partielle) d’un modèle ML.
- Janvier 2023 : Prise en compte des valideurs dans Sirene 4 : éligibilité de l’activité du déclarant (CMA,…)
- Mai 2023 : 1er ré-entrainement pour corriger un problème de classification
- Mars 2024 : Toutes les liasses passent par fasttext. Complète bascule de Sirene 3 à 4
- Et maintenant ?
Enjeux actuels
- Plusieurs problématiques :
- Modèle entrainé sur les données Sirene 3
- Changement de nomenclature NAF 2008 vers NAF 2025
- Explicabilité du modèle pour les gestionnaires
- Groupe de veille n°10 en janvier 📅
2️⃣ Passage de la NAF 2008 à la NAF 2025
Calendrier pour l’adoption de la nouvelle NAF 🗓️
- Vers une adoption transitoire
- 2025 ➡️ double codification en NAF 2025
- Sirus : recodification pour fin 2025
- Sirene : Intégration de la NAF 2025 en flux et d’une infrastructure MLOps-compatible
- 2026 ➡️ amélioration de la codification en NAF 2025
- 2027 ➡️ codification en NAF 2025 avec maintien de la codification NAF 2008
NAF 2025 : quels changements ?
- Au niveau 5 : 746 sous classes contre 732 auparavant
- Principalement des éclatements au niveau de la classe (niveau 4) … mais pas que !
- 551 classes univoques, correspondance 1-pour-1 ➡️ cas idéal ! 👌

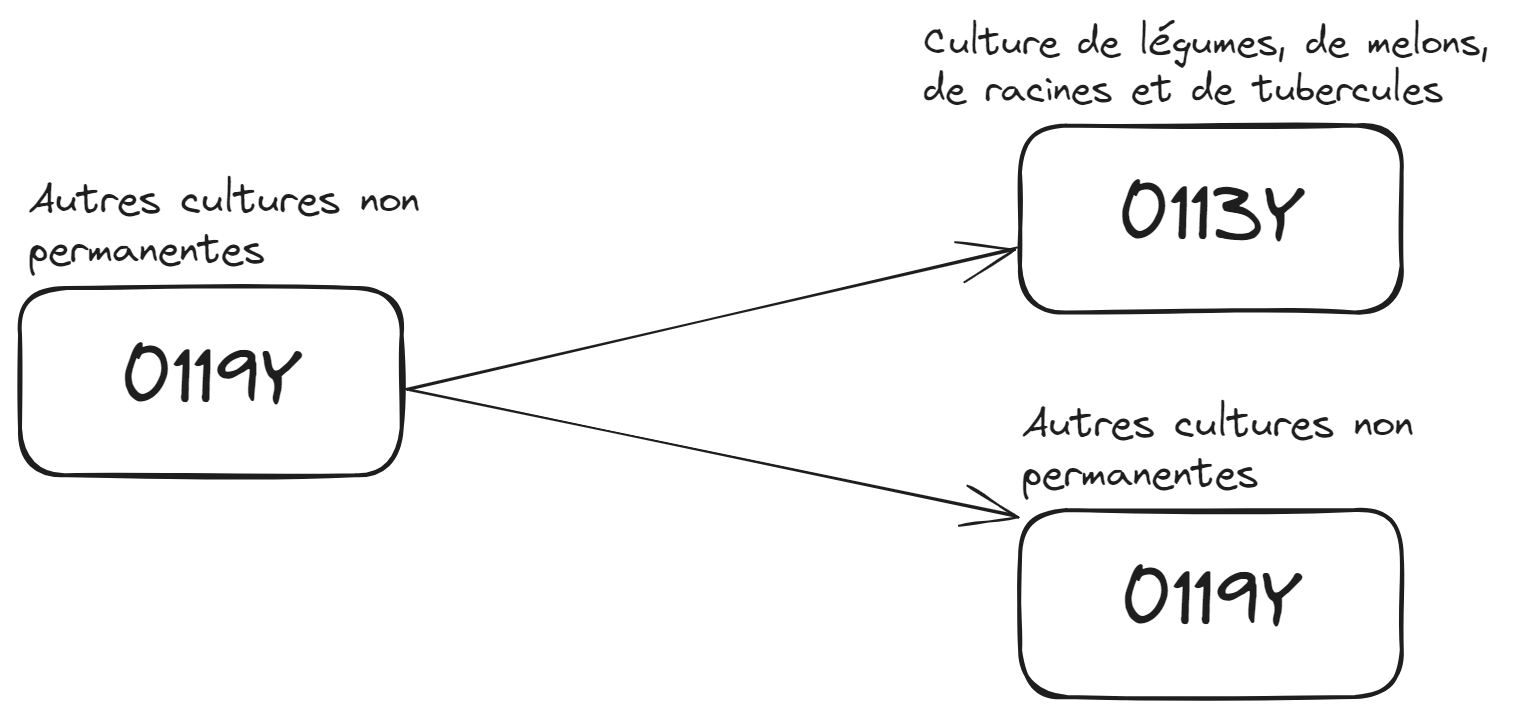
NAF 2025 : les cas multivoques
- 181 classes multivoques, correspondance 1-pour-N ➡️ cas problématiques ! 🚩
- Besoin d’un expert pour déterminer le nouveau code
Afficher la distribution des codes multivoques
| 1-to-N | # occurence |
|---|---|
| 2 | 109 |
| 3 | 30 |
| 4 | 24 |
| 5 | 6 |
| 6 | 4 |
| 8 | 1 |
| 9 | 2 |
| 21 | 1 |
| 27 | 1 |
| 36 | 1 |
| 38 | 2 |
Enjeux et besoins multiples
- Besoin de recoder le stock de liasse de Sirene ➡️ + \(14\) millions…
- Pouvoir coder le flux en NAF 2025 ➡️ entraîner un modèle ➡️ besoin d’avoir un stock…
- Modèle en NAF 2008 entrainé sur + 10 millions
- Performance de fastText très dépendant du nombre de données d’entraînement
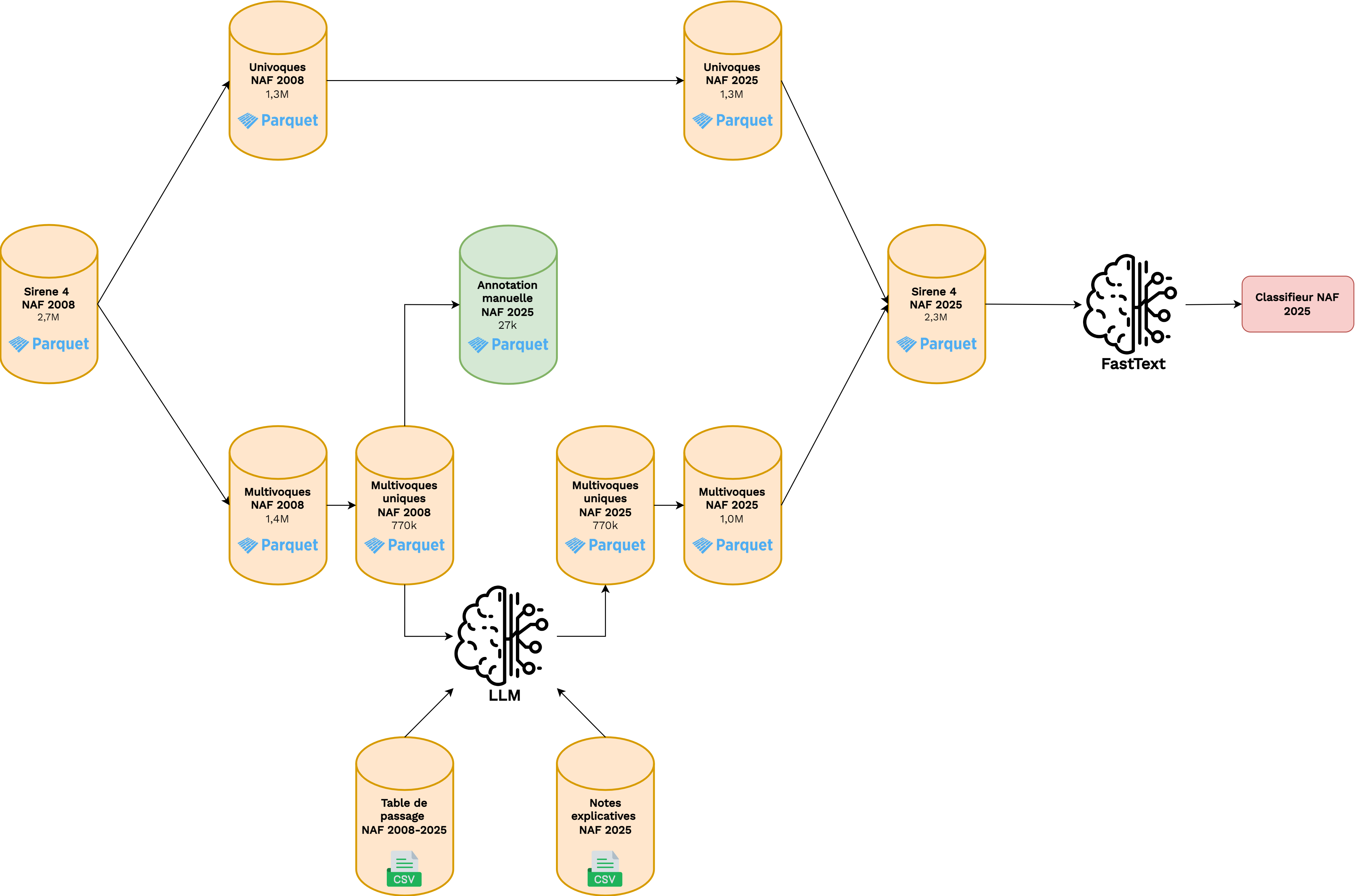
Données à disposition
- Stock Sirene 3 : \(~10\) millions obs. mais peu adaptées aux nouvelles données
- Stock Sirene 4 : \(~2.7\) millions obs.
- Univoques : \(1.3\) millions obs. et 504 sous-classes
- Multivoques : \(1.4\) millions obs. et 177 sous-classes
- Campagne d’annotation manuelle indispensable
Campagne d’annotation
- Lancement d’une campagne d’annotation depuis mi-2024
- Plateforme développée par l’équipe métier 🤔
- Focus sur les données multivoques uniques
- 🎯 Objectif double :
- Attribuer un code NAF 2025 🚀
- Vérifier la qualité du code NAF 2008 🗸
Aujourd’hui, \(~27k\) données annotées… insuffisant !
3️⃣ Méthodologie appliquée
Méthodologie
- 🎯 Objectif : Reconstruire un jeu d’entraînement le plus exhaustif possible
- Expérimentation one-shot ➡️ pas de contrainte de reproductibilité … en production
- Utilisation de LLMs pour générer des annotations en NAF 2025
- Données à disposition :
- Stock Sirene 4 (\(~2.7\) millions d’observations)
- Table de passage réalisée par les experts APE
- Notes explicatives de la NAF 2025
- Annotations manuelles (\(~27k\) observations)
Méthodologie
Tirer profit des LLMs
Retrieval Augmented Generation (RAG) vs fine-tunning
2 possibilités :
- RAG avec les notes explicatives
- Pas encore testé 📝
- Pseudo-RAG :
- Retriever manuel utilisant la table de passage
💡 Idée générale ➡️ Fournir les données essentielles au LLM pour convertir les codes NAF 2008 vers 2025
Avertissement
L’idée n’est pas de construire un classifier, seulement créer des annotations.
Le prompting
Prompt système identique pour toutes les observations
Afficher le prompt sytème
Tu es un expert de la Nomenclature statistique des Activités économiques dans la Communauté Européenne (NACE). Tu es chargé de réaliser le changement de nomenclature. Ta mission consiste à attribuer un code NACE 2025 à une entreprise, en t'appuyant sur le descriptif de son activité et à partir d'une liste de codes proposés (identifiée à partir de son code NACE 2008 existant). Voici les instructions à suivre : 1. Analyse la description de l'activité principale de l'entreprise et le code NACE 2008 fourni par l'utilisateur. 2. À partir de la liste des codes NACE 2025 disponible, identifie la catégorie la plus appropriée qui correspond à l'activité principale de l'entreprise. 3. Retourne le code NACE 2025 au format JSON comme spécifié par l'utilisateur. Si la description de l'activité de l'entreprise n'est pas suffisamment précise pour identifier un code NACE 2025 adéquat, retourne `null` dans le JSON. 4. Évalue la cohérence entre le code NACE 2008 fourni et la description de l'activité de l'entreprise. Si le code NACE 2008 ne semble pas correspondre à cette description, retourne `False` dans le champ `nace08_valid` du JSON. Note que si tu arrives à classer la description de l'activité de l'entreprise dans un code NACE 2025, le champ `nace08_valid` devrait `True`, sinon il y a incohérence. 5. Réponds seulement avec le JSON complété aucune autres information ne doit être retourné.Un prompt spécifique pour chaque observations comprenant :
- le libellé de l’activité principale de l’entreprise
- l’ancien code NAF 2008 connu
- La liste des codes possibles issues du mapping avec leurs notes explicatives
Une instruction sur le format de réponse attendu
Qualifier la réponse générée
- Tendance des LLMs a être très volubiles…
- Construction d’une réponse type, claire et brèves dans un format spécifique
- Format JSON est le plus abondamment utilisé dans l’écosystème
Afficher un exemple de réponse attendue
- Parsing de la réponse :
- Vérification du format
- Contrôle des hallucinations
LLMs utilisés
| Modèle | Taille | Vitesse d’inférence | Performance | Caractéristique |
|---|---|---|---|---|
| Qwen 2.5 | 32B | Lent | Bonnes performances | Très restrictif |
| Ministral | 8B | Extrêmement rapide | Très raisonnable | Pas restrictif |
| Mistal Small | 44B | Lent | Bonnes performances | Assez restrictif |
| Llama 3.1 | 70B (quantisé) | Extrêmement lent | Très bonnes performances | Assez restrictif |
4️⃣ Résultats
Le fléau de l’évaluation
❓ Question cruciale :
- Comment évaluer un LLM ?
- Classification ➡️ plus facile, vraiment ?
- Complexité de la nomenclature
Utilisation des \(27k\) annotations comme ground truth 🥇
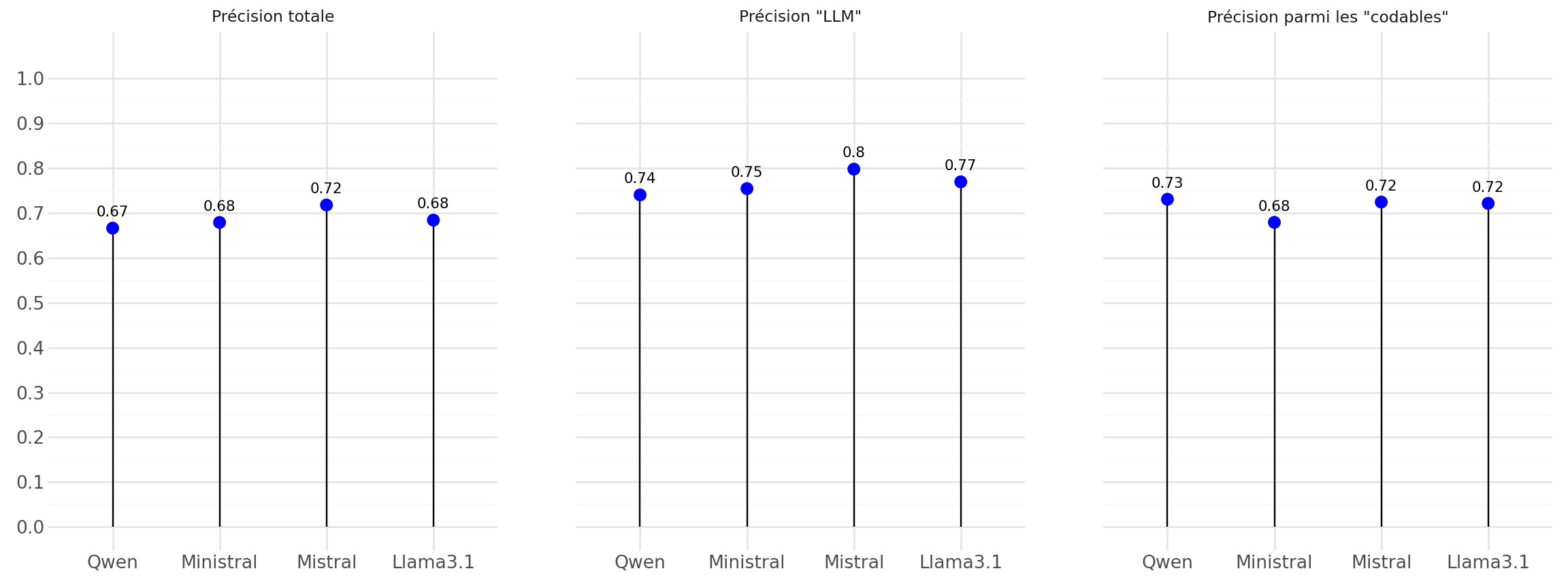
3 métriques de performances :
- Précision totale
- Précision parmi les “codables”
- Précision “LLM” (erreurs imputables à la génération seulement)
Performance des modèles
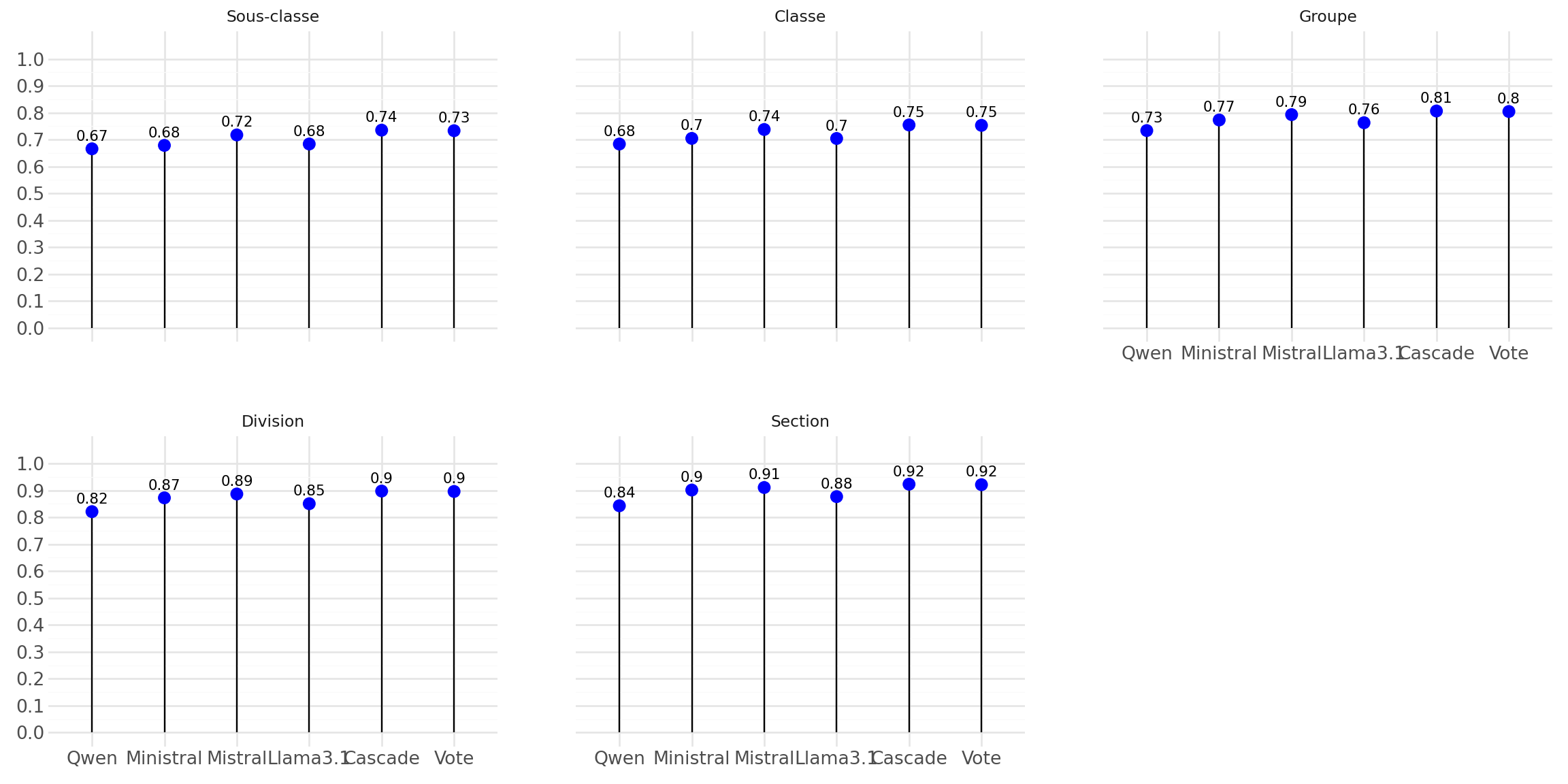
Reconstruction du jeu multivoques
- 💡Principe : considérer les LLMs comme des annotateurs classiques ➡️ X-annotation
- ❓Peut-on améliorer performances en mixant les résultats de chaque modèles ?
- Construction de 3 annotations supplémentaires
- Choix en cascade (un modèle en priorité)
- Choix par vote à la majorité
- Choix par vote pondéré
Combinaison des annotations
Ré-entrainement en NAF 2025
- Reconstruction du stock Sirene 4 en NAF 2025 (\(~2\) millions d’observations)
- Distribution des données quasi-inchangées
- Utilisation de nouvelles variables propres à Sirene 4
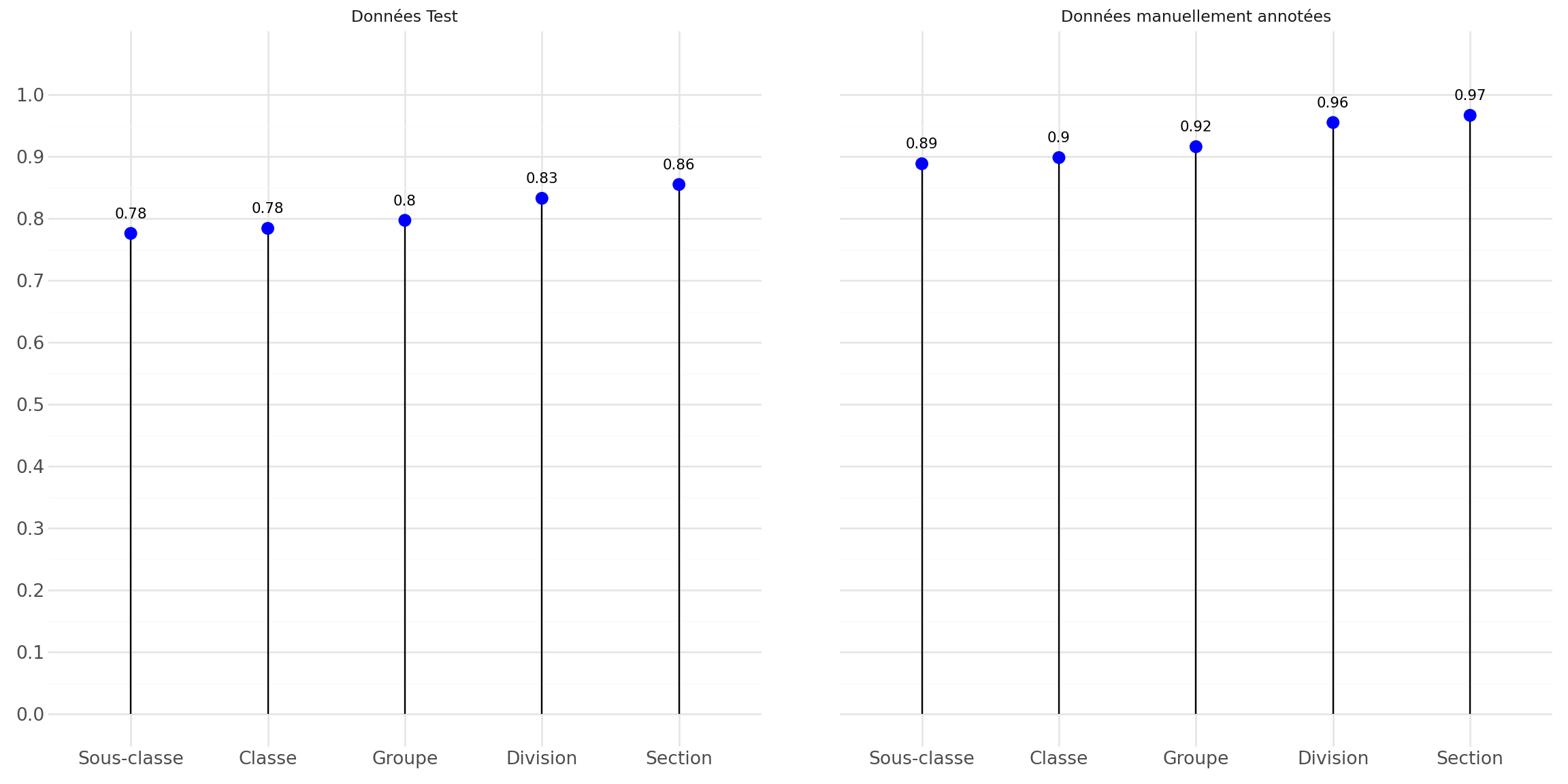
- Performances similaires au modèle en NAF 2008
Ré-entrainement en NAF 2025
Le modèle NAF 2025
viewof activite = Inputs.text(
{label: '', value: 'coiffeur', width: 800}
)
viewof type_form = Inputs.text(
{label: 'Type de la liasse', value: 'X', width: 80}
)
urlApe = `https://codification-ape-dev.lab.sspcloud.fr/predict?description_activity=${activite}%20&type_form=${type_form}&event=01P&nb_echos_max=3&prob_min=0.0009`
d3.json(urlApe).then( res => {
var IC, results;
( {IC, ...results} = res )
IC = parseFloat(IC)
const rows = Object.values(results).map( obj => {
return `
<tr>
<td>${obj.code} | ${obj.libelle}</td>
<td>${obj.probabilite.toFixed(3)}</td>
</tr>
`
}).join('')
return html`
<table>
<caption>
Indice de confiance : ${IC.toFixed(3)}
</caption>
<tr>
<th style="text-align:center;">Libellé (NAF 2025)</th>
<th>Probabilité</th>
</tr>
${rows}
</table>`
})