FastTextModel(
(embeddings): Embedding(20000, 80, padding_idx=0, sparse=True)
(fc): Linear(in_features=80, out_features=732, bias=True)
)L’après fastText: Présentation de torchFastText
Groupe de veille Codification Automatique n°10
5 mars 2025
1️⃣ Contexte
fastText : en production, mais archivé
- fastText : le go-to pour la classification de texte à l’Insee
- Efficace, performant, mis en production pour la codification APE…
- …mais repo archivé depuis le 19/03/2024
Enjeux
- La non-maintenance de la librairie : à terme, risques de maintenance, de compatibilité…
- Surtout : freine les possibilités de modernisation
- Une alternative :
torchFastText - Avec toujours un horizon de production
Opportunités (et contraintes ?)
💪
- Architecture in-house, adaptée aux besoins maison
- Maintenance internalisée
- Meilleur monitoring de l’entraînement 📈
- Passage en PyTorch ouvre des opportunités de modernisation : explicabilité, modèles plus performants…
😖 Nécessite une GPU pour garder des temps d’entraînement similaires
Surtout, des questions sur le temps d’inférence (forcément sur CPU)…
2️⃣ Présentation du package
Objectifs
- Distribution d’une architecture de deep learning standardisée pour les besoins de classification de texte avec variables catégorielles
- Publication en open-source pour favoriser la collaboration
- A destination d’autres équipes de l’Insee, SSM et INS européens 👐
- Progressivement pouvoir mettre en production du PyTorch
Le modèle PyTorch
- Le modèle en tant que tel en PyTorch natif
Gestion des variables catégorielles
- Véritable ajout par rapport à la librairie originale : chaque variable catégorielle a une matrice d’embedding associée
- Le read-me précise la façon dont le modèle les gère
FastTextModel(
(embeddings): Embedding(20000, 80, padding_idx=0, sparse=True)
(emb_0): Embedding(10, 5)
(emb_1): Embedding(20, 5)
(fc): Linear(in_features=85, out_features=732, bias=True)
)Le module Lightning
- La librairie
Lightningest une surcouche de PyTorch qui permet de gérer l’entraînement - Le package fournit également le “module” Lightning qui peut être donné en entrée au
Trainer
from torchFastText.model import FastTextModel, FastTextModule
import torch
model = FastTextModel(embedding_dim=80,
num_classes=732,
num_rows = 20000,
)
module = FastTextModule(
model=model,
loss= torch.nn.CrossEntropyLoss(),
optimizer=torch.optim.Adam,
optimizer_params={"lr": 0.001},
scheduler = None,
scheduler_params=None
)
print(module)FastTextModule(
(model): FastTextModel(
(embeddings): Embedding(20000, 80, padding_idx=0, sparse=True)
(fc): Linear(in_features=80, out_features=732, bias=True)
)
(loss): CrossEntropyLoss()
(accuracy_fn): MulticlassAccuracy()
)Le tokenizer
- L’objet
NGramTokenizerreprend la méthode des ngrams du papier original pour transformer une phrase en une liste de tokens
from torchFastText.datasets import NGramTokenizer
training_text = ['boulanger', 'coiffeur', 'boucherie', 'boucherie charcuterie']
tokenizer = NGramTokenizer(
min_n=3,
max_n=6,
num_tokens= 100,
len_word_ngrams=2,
min_count=1,
training_text=training_text
)
print(tokenizer.tokenize(["boulangerie"])[0])[['<bo', 'bou', 'oul', 'ula', 'lan', 'boul', 'nge', '<boul', 'eri', 'rie', 'ie>', 'boul', 'boul', 'oula', 'ulan', 'lang', 'ange', 'nger', 'geri', 'erie', 'rie>', '<boul', 'boula', 'oulan', 'ulang', 'lange', 'anger', 'ngeri', 'gerie', 'erie>', '<boula', 'boulan', 'oulang', 'ngerie', 'langer', 'angeri', 'ngerie', 'gerie>', '</s>', 'boulangerie </s>']]La classe wrapper
- A destination d’utilisateurs débutants en deep learning
- Orchestre l’ensemble des briques pour lancer un entraînement rapidement
from torchFastText import torchFastText
# Initialize the model
model = torchFastText(
num_tokens=1000000,
embedding_dim=100,
min_count=5,
min_n=3,
max_n=6,
len_word_ngrams=True,
sparse=True
)
# Train the model
model.train(
X_train=train_data,
y_train=train_labels,
X_val=val_data,
y_val=val_labels,
num_epochs=10,
batch_size=64
)
# Make predictions
predictions = model.predict(test_data)3️⃣ Tests sur la codification APE
Stratégie
📈 Données :
- Extraction Sirene 4 : de janvier 2023 à février 2025
- Split en train (2.5M de libellés) / val (300k) / test (300k)
- Dataset de test externe annoté par des humains (8k)
⛓️ Méthode :
- Entraînement parallélisé (Argo Workflow), tracking avec MLFlow
- Sur GPU (A2 et H100)
- 10 epochs, batch size de 256
🚀 Objectifs :
- Grid search sur la dimension d’embedding et le nombre de buckets avec entraînement GPU (~2 mn / epoch)
- Sélection du modèle le plus petit possible sans rogner sur la performance
- Test sur CPU (précision, calibration, temps d’inférence)
Entraînement - bilan
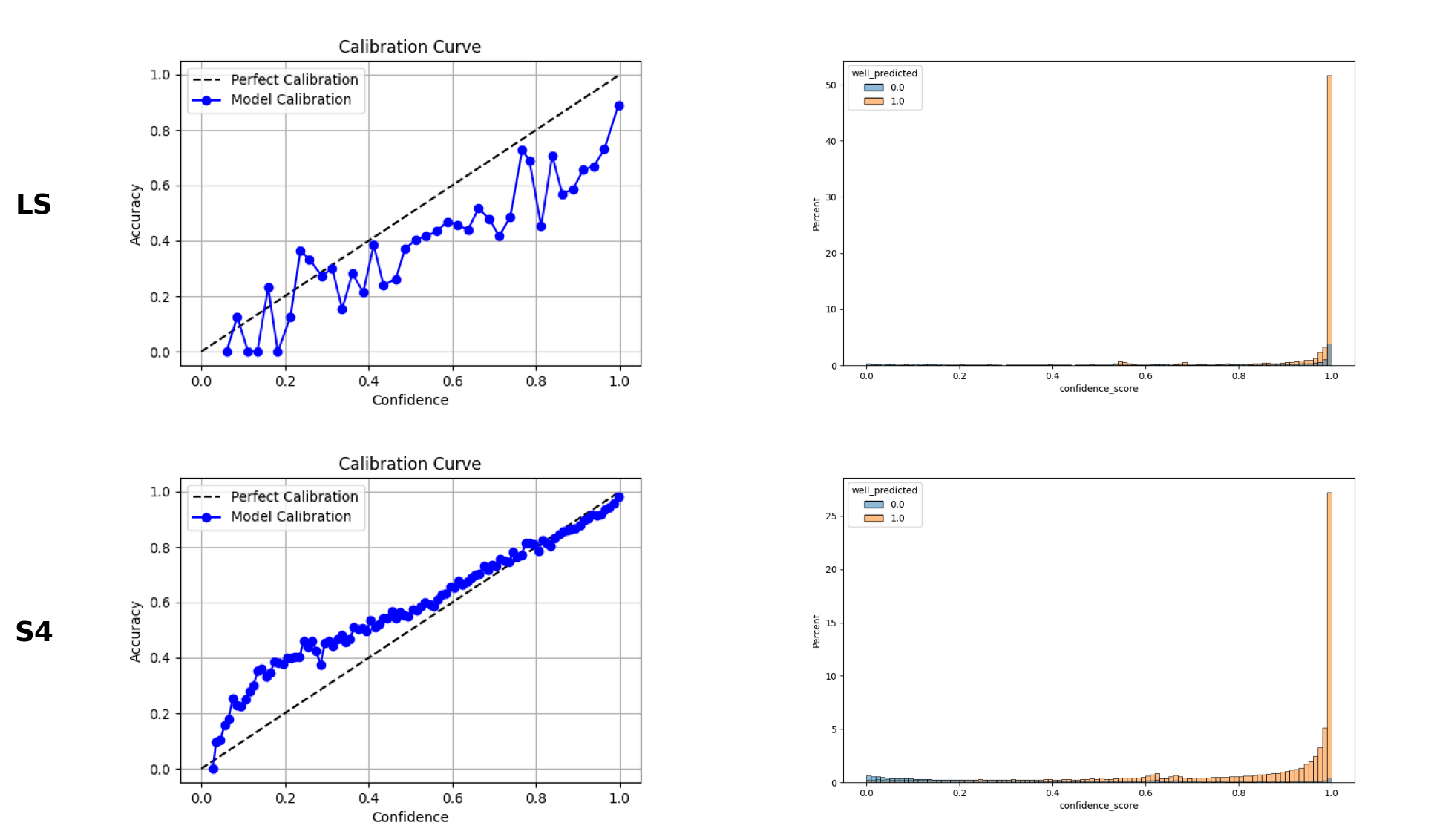
Résultats de la validation
☑️ On choisit le modèle \((10000, 80)\)
| Test Accuracy ⬆️ | Brier Score ⬇️ | |
|---|---|---|
| Dataset | ||
| Label Studio | 0.782 | 0.153 |
| S4 | 0.820 | 0.117 |
Calibration
Temps d’inférence
Explicabilité
viewof top_k = Inputs.range([0, 10], {value: 3, step: 1, label: "Top k"})
viewof activite = Inputs.text({label: "", value: "coiffeur", width:800})
urlApe = transformToUrl(activite, top_k)
predictions = d3.json(urlApe)
predictions_arr = Object.values(predictions)
Inputs.table(
predictions_arr, {
format: {
probabilite: (d) => d.toFixed(3)},
columns: [
"code",
"libelle",
"probabilite",
],
header: {
code: "Code NAF",
libelle: "Libellé",
probabilite:"Score de confiance"
}
}
)letters = activite.split('').filter(letter => letter != ' ')
words = activite.split(" ").filter(word => word !== "")
lettersData = letters.map((letter, i) => ({
x: `${letter}_${i}`,
y: chosen_label.letter_attr[i],
code: chosen_label.code,
letter: letter,
idx: i,
}))
wordsData = words.map((word, i) => ({
x: `${word}_${i}`,
y: chosen_label.word_attr[i],
code: chosen_label.code,
word:word,
idx:i,
}))
lettersDomain = letters.map((letter, i) => `${letter}_${i}`)
wordsDomain = words.map((word, i) => `${word}_${i}`)
viewof chosen_label =
Inputs.select(predictions_arr, {label: "", format: x=>x.code, value:predictions_arr[0].code})
viewof aggregateWords = Inputs.toggle({
label: ""
})
data_to_plot = (aggregateWords == true) ? wordsData : lettersData
domain_to_plot = (aggregateWords == true) ? wordsDomain : lettersDomain
Plot.plot({
marks: [
Plot.barY(
data_to_plot,
{
x: "x",
y: "y",
fill: "code",
}
)
],
x: { label: "", tickFormat: d => d.split('_')[0], domain:domain_to_plot },
y: { label: "Score d'influence", grid: true },
color: { scheme: "Tableau10", legend: true },
})import { debounce } from "@mbostock/debouncing-input"
import {Plot} from "@observablehq/plot";
function transformToUrl(description, top_k) {
// Base URL
const baseUrl = "https://codification-ape-pytorch.lab.sspcloud.fr/predict-and-explain";
// Encode the description to make it URL-safe
const encodedDescription = encodeURIComponent(description);
// Append parameters to the URL
const fullUrl = `${baseUrl}?text_description=${encodedDescription}&prob_min=0.01&top_k=${top_k}`;
return fullUrl;
}
function generateLetterLabels(length) {
return Array.from({ length }, (_, i) => String.fromCharCode(65 + (i % 26)));
}