Retraining strategies for an economic activity classification model
European Conference on Quality in Official Statistics 2024
21 May 2024
Machine learning in official statistics
- Today, machine learning systems contribute effectively to the production of official statistics
- Coding engines, data editing: outlier detection, imputation
- CoP: “Source data, integrated data, intermediate results and statistical outputs [must be] regularly assessed and validated” and “revisions [must be] regularly analysed in order to improve source data, statistical processes and outputs”
- This naturally applies when ML systems are leveraged in the process of producing statistics
Quality of ML systems
- A ML model is trained to solve a task based on reference data
- Real-life data can deviate from the reference data, which leads to performance issues
- Retraining is necessary to avoid these issues
Description of the coding system
- Sirene is the French national company register
- When a company registers, an activity code is attributed
- A model trained on historical Sirene data is used when it is confident enough. Otherwise, the description is given a code manually
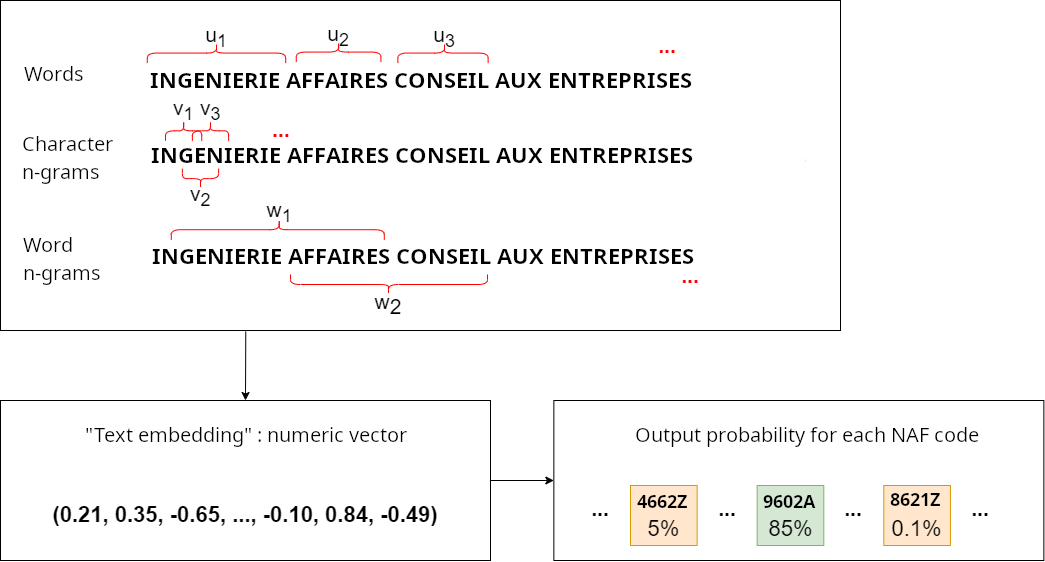
Modeling
![]()
Design
- The model is served via a REST API (developed with FastAPI)
- A process fetches logs daily, parses them and saves their content on a persistent storage
- An interactive dashboard is built with Quarto to offer insight on data and how it is coded
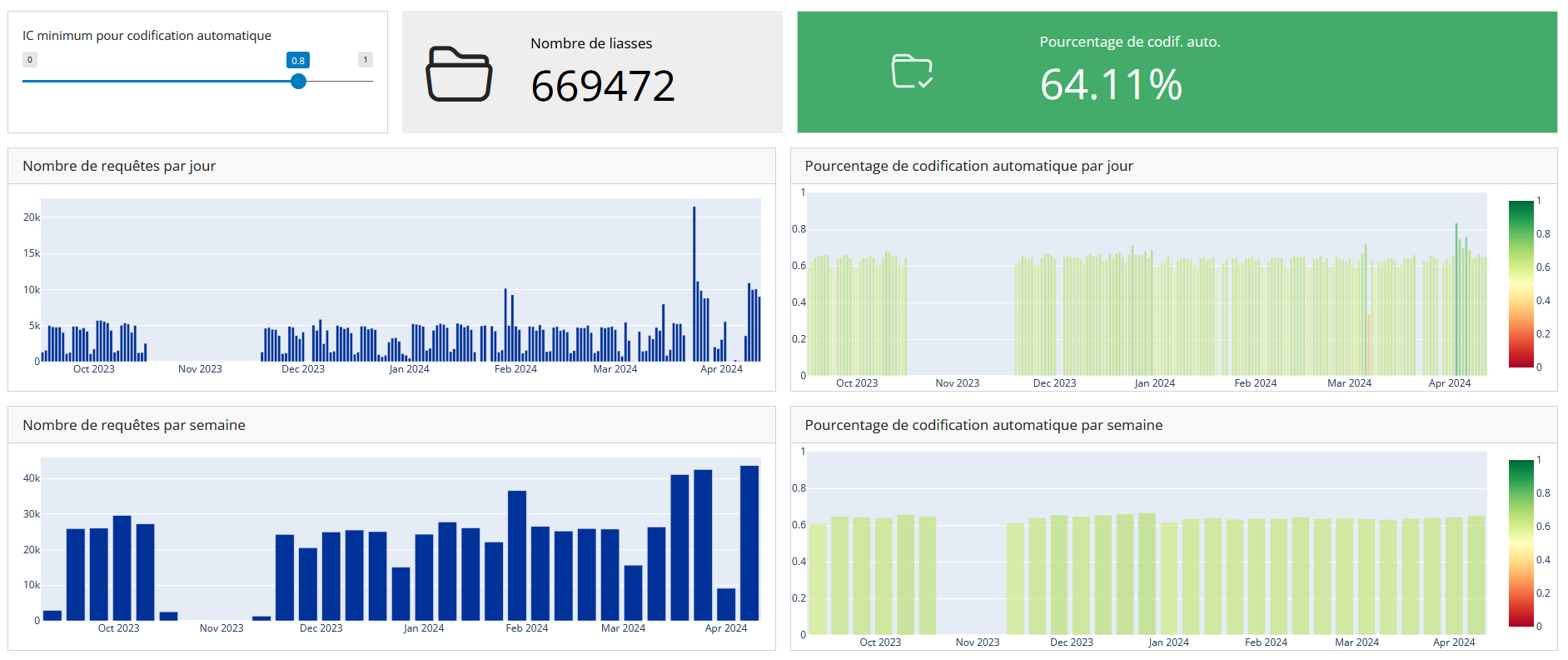
Dashboard
![]()
Dashboard tab offering daily and weekly insight on the number of queries to the API and its automatic coding rate.
Dashboard
![]()
Dashboard tab displaying the two distributions of predicted classes at a specified level of the classification system for two specified time windows.
Periodic retraining
- Company activities evolve over time. A first strategy is to retrain the model periodically
- How frequently ? There is a tradeoff as there should be a validation procedure to use a new model in production
- In our case, distribution shifts are not large. It is reasonable to retrain twice a year
Additional retraining
- Additional specific retraining procedures can be triggered:
- When the monitoring system detects unusual shifts in the data
- When repeated claims are made by certain companies on their activity code
- When coding concepts change
What training data ?
- When retraining a model from scratch: how far should we go in the past to build the training set ?
- Empirical evaluation is necessary:
- Model capabilities scale with training data
- Older data has lower quality labels
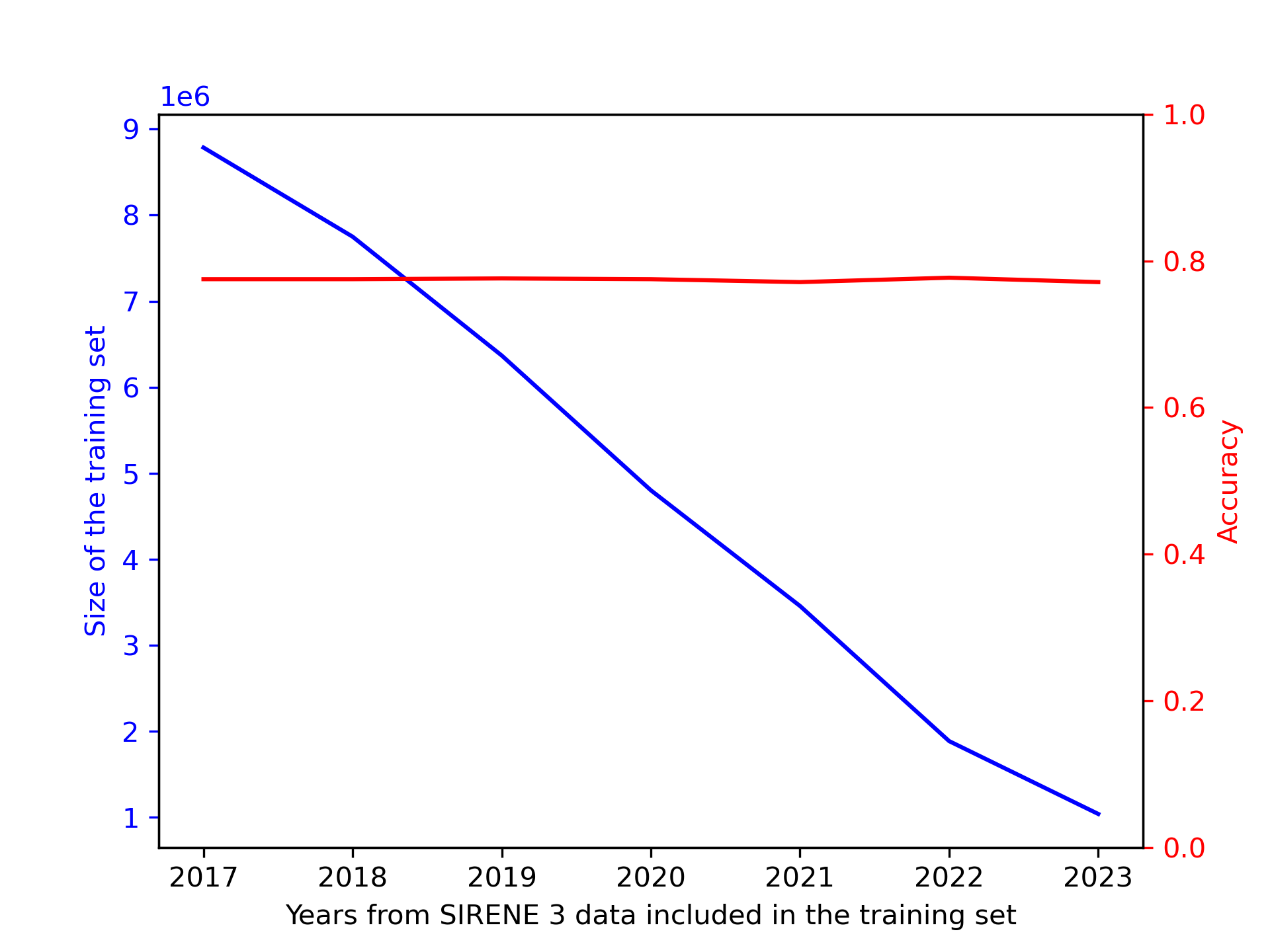
What training data ?
![]()
Accuracy and training set size as functions of the earliest year included in historical training data